37007538
Beschreibung
Mindmap von Artur Assis, aktualisiert more than 1 year ago
|
|
Erstellt von Artur Assis
vor mehr als 3 Jahre
|
|
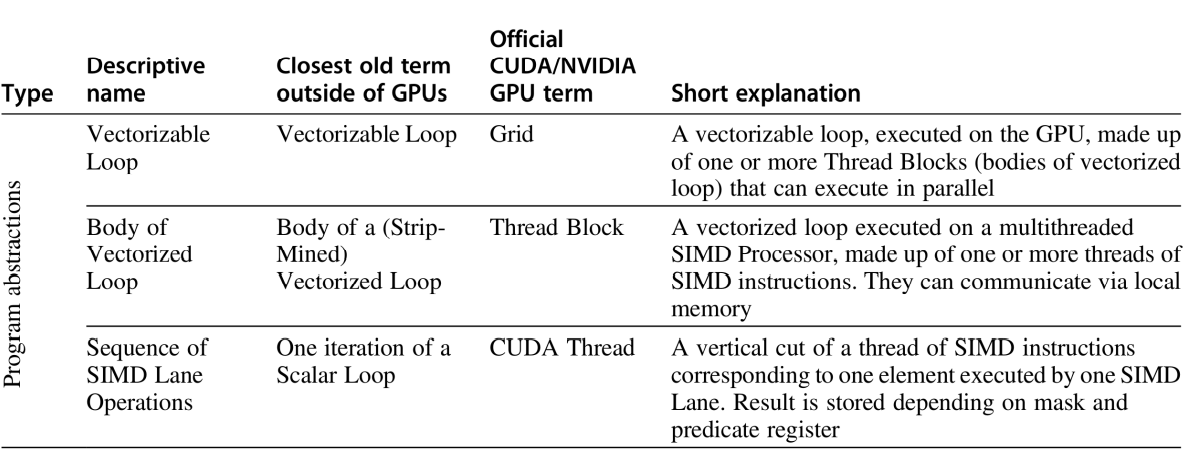
Graphic Processing Units (GPU)
- Overview
- A graphics processing unit (GPU) is similar to a set of vector processors sharing hardware. The multiple SIMD
processors in a GPU act as independent MIMD cores, like vector computers have multiple vector processors. The main
difference is multithreading, which is fundamental to GPU. This feature is missing on most vector processors.
- Set of vector processors
- Multiple SIMD processors
- Act like independend
MIMD
- Act like independend
MIMD
- Multithreading
- A graphics processing unit (GPU) is similar to a set of vector processors sharing hardware. The multiple SIMD
processors in a GPU act as independent MIMD cores, like vector computers have multiple vector processors. The main
difference is multithreading, which is fundamental to GPU. This feature is missing on most vector processors.
- Programming for the GPU
- Compute Unified Device Architecture (CUDA)
- It is a C-like programming language developed by
NVIDIA used to program for its GPUs. CUDA
generates C/C++ code for the system processor
(named host), and a C/C++ dialect for the GPU
(named device). In this setup system, the processor
is known as the “host”, and the GPU as the “device”.
- Characteristics
- Developed by NVIDIA
- C-like programming language
- Setup System
- Host
- System processor
- C/C++ code
- System processor
- Device
- GPU
- C/C++ dialect
- GPU
- Host
- Developed by NVIDIA
- CUDA thread
- Lowest level of parallelism
- Single instruction, Multiple Threads
(SIMT)
- Lowest level of parallelism
- Thread block
- Threads are executed
together in blocks
- Threads are executed
together in blocks
- Multithreaded SIMD
- It is the hardware that executes a whole block of threads.
- It is the hardware that executes a whole block of threads.
- Modifiers
- Function modifiers
- The CUDA functions can have different modifiers such as device, global or
host.
- __device__
- Executed in the device, launched by the device.
- Executed in the device, launched by the device.
- __global__
- Executed in the device, launched by the host.
- Executed in the device, launched by the host.
- __host__
- Executed in the host, launched by the host.
- Executed in the host, launched by the host.
- The CUDA functions can have different modifiers such as device, global or
host.
- Variable
Modifiers
- __device__
- A variable declared with this modifier is allocated to the GPU
memory, and accessible by all multithreaded SIMD processors
- A variable declared with this modifier is allocated to the GPU
memory, and accessible by all multithreaded SIMD processors
- The CUDA variables have also some modifiers such as the device.
- __device__
- Function modifiers
- CUDA specific terms
- Code examples
- Ex. Y = a*X + Y
- Conventional C code
- Conventional C code
- CUDA corresponding version
- This code launches n threads, once per
vector element, with 256 threads per thread block in
a multithread SIMD processor. The GPU function
begins by computing the corresponding element
index i based on the block ID, number of threads per
block, and the thread ID. The operation of
multiplication and addition is performed as long as
the index i is within the array.
- CUDA corresponding version
- Ex. A = B * C
- Multiply 2 vectors with
8192 elements each
- Grid (Vectorized loop)
- GPU code that works on the whole 8192 elements
multiply is called grid.
- A grid is composed of thread blocks (body of vectorized loops)
- in this case, each thread block with up to 512 elements (16 threads/block x 32 elements/thread),
i.e., 16 threads per block
- in this case, each thread block with up to 512 elements (16 threads/block x 32 elements/thread),
i.e., 16 threads per block
- SIMD instruction executes 32 elements at a time
- GPU code that works on the whole 8192 elements
multiply is called grid.
- Multiply 2 vectors with
8192 elements each
- Ex. Y = a*X + Y
- It is a C-like programming language developed by
NVIDIA used to program for its GPUs. CUDA
generates C/C++ code for the system processor
(named host), and a C/C++ dialect for the GPU
(named device). In this setup system, the processor
is known as the “host”, and the GPU as the “device”.
- Open Computing Language (Open-CL)
- The Open Computing Language (Open-CL) is a CUDA-similar programming language, in
a general and rough sense. Several companies are developing OpenCL to offer a
vendor-independent language for multiple platforms, in contrast to CUDA.
- Vendor independent
- Multiple Platforms
- The Open Computing Language (Open-CL) is a CUDA-similar programming language, in
a general and rough sense. Several companies are developing OpenCL to offer a
vendor-independent language for multiple platforms, in contrast to CUDA.
- Extended function call
- Components
- dimGrid
- Specifies the dimensions of the code, in terms of thread blocks
- Specifies the dimensions of the code, in terms of thread blocks
- dimBlock
- Specifies the dimensions of a block, in terms of threads.
- Specifies the dimensions of a block, in terms of threads.
- Parameter list
- blockIdx
- It is the identifier/index for blocks.
- It is the identifier/index for blocks.
- threadIdx
- It is the identifier/index of the current thread within its block
- It is the identifier/index of the current thread within its block
- blockDim
- It stands for the number of threads in a block, which comes from
the dimBlock parameter.
- It stands for the number of threads in a block, which comes from
the dimBlock parameter.
- blockIdx
- dimGrid
- Compute Unified Device Architecture (CUDA)
Medienanhänge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
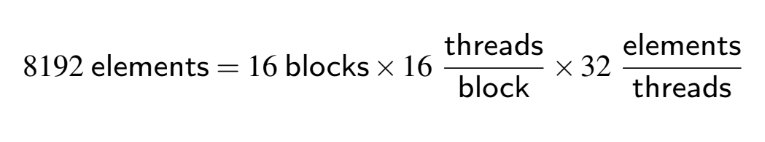{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.