37007976
Beschreibung
Mindmap von Artur Assis, aktualisiert more than 1 year ago
|
|
Erstellt von Artur Assis
vor mehr als 3 Jahre
|
|
Parallel Architectures
- Multiple instruction streams, multiple data streams (MIMD)
- Multiprocessors
- Computers consisting of tightly coupled processors whose
coordination and usage are generally controlled by a single operating
system. The processors share memory through a shared address space.
- Multiple processors tightly coupled
- Single Operating System
- Shared memory through shared memory space
- Multiple processors tightly coupled
- OBS: Multiprocessor is different from multicore.
- Computers consisting of tightly coupled processors whose
coordination and usage are generally controlled by a single operating
system. The processors share memory through a shared address space.
- Memory Organization
- Multiprocessors may share:
- cache memory, main memory, and I/O system
- main memory and I/O system
- I/O system
- nothing, usually communicating through networks
- Are all these options
interesting?
- Note that it is important to avoid
bottlenecks in the architecture. And the
answer to this question also depends
on the project requirements that have
to be fulfilled
- Avoid
bottlenecks
- It depends on the project requirements
- Avoid
bottlenecks
- Note that it is important to avoid
bottlenecks in the architecture. And the
answer to this question also depends
on the project requirements that have
to be fulfilled
- cache memory, main memory, and I/O system
- Classification
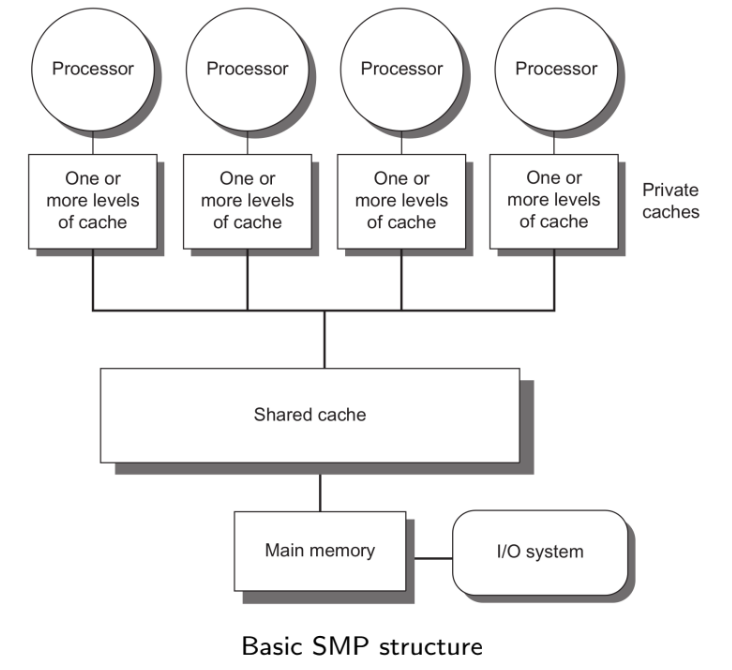
- Symmetric (shared-memory) Multiprocessors (SMP) or
Centralized shared-memory Multiprocessors
- Characteristics
- ≈ 32 cores or
less
- share a single centralized
memory where
processors have equal
access to.
- symmetric
- symmetric
- memory/bus may become a
bottleneck
- Large use of caches and
buses to avoid the
bottleneck
- Large use of caches and
buses to avoid the
bottleneck
- uniform access time (UMA) to all the
memory from all the processors
- UMA
- UMA
- ≈ 32 cores or
less
- Characteristics
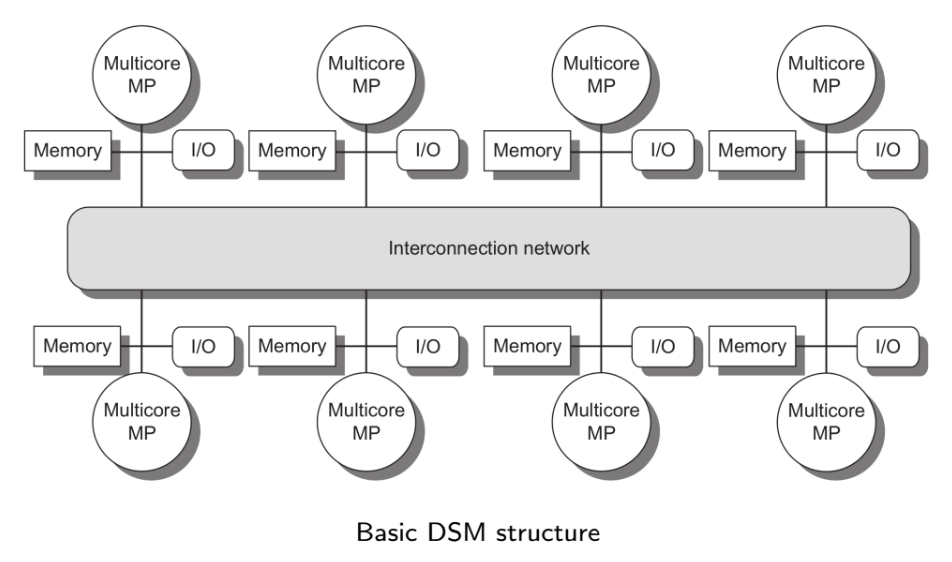
- Distributed Shared Memory
(DSM)
- Characteristics
- 16-64 processor cores
- Large number of processors
- Large number of processors
- Distributed memory
- Increase bandwidth
- Reduce access latency
- Increase bandwidth
- More complex communication between processors
- More software effort to take
advantage of the increased
memory bandwidth
- Distributed I/O
- Each node can be a small distributed
system with centralized memory
- Each node can be a small distributed
system with centralized memory
- Nonuniform memory access (NUMA). Access time
depends on the location of a data word in memory.
- NUMA
- NUMA
- 16-64 processor cores
- Characteristics
- Symmetric (shared-memory) Multiprocessors (SMP) or
Centralized shared-memory Multiprocessors
- Multiprocessors may share:
- Memory Architecture for
- SMP
- processors share a single memory
- uniform access times to the memory (UMA)
- processors share a single memory
- DSM
- processors share the same address space, but
not necessarily the same physical memory
- nonuniform memory access (NUMA)
- processors share the same address space, but
not necessarily the same physical memory
- Multicomputers
- processors with independent memories and address spaces
- communicate through interconnection networks
- may even be complete computers connected in network, i.e., clusters
- may even be complete computers connected in network, i.e., clusters
- processors with independent memories and address spaces
- SMP
- Communication models for
- SMP
- SMP Communication Model: There is an implicit memory communication
(memory access). In SMP, with a central memory, it is possible to use the
threads and fork-join model. One alternative is the application
programming interface named open multi-processing (OpenMP).
- Implicit memory communication
- Memory access
- Memory access
- Central memory
- Threads and fork-joins
- Ex.: OpenMP
- Thread (lightweight process)
- Threads are lines of execution within a
process and they share the address space
of the process to which they belong.
- Threads are lines of execution within a
process and they share the address space
of the process to which they belong.
- Fork-join model
- A process creates a child process (thread), by using fork.
A process (parent) and its threads (children) share the same
address space. Next, the process waits for their threads to
finish their computation by calling join. Creating a process is
expensive to the operating system, and that is one reason to
use different threads to perform a computation.
- A process creates a child process (thread), by using fork.
A process (parent) and its threads (children) share the same
address space. Next, the process waits for their threads to
finish their computation by calling join. Creating a process is
expensive to the operating system, and that is one reason to
use different threads to perform a computation.
- Ex.: OpenMP
- Implicit memory communication
- SMP Communication Model: There is an implicit memory communication
(memory access). In SMP, with a central memory, it is possible to use the
threads and fork-join model. One alternative is the application
programming interface named open multi-processing (OpenMP).
- DSM
- DSM Communication Model: In DSM, with a distributed memory,
it is possible to make use of the message passing model. There
is a library project implementing a message passing interface
(MPI). Explicit communication is in place (message passing). This
solution brings also synchronization problems.
- Distributed memory
- Message passing model
- synchronization problems
- Ex.: Message Passing Interface (MPI)
- synchronization problems
- Explicit communication (message passing)
- Distributed memory
- DSM Communication Model: In DSM, with a distributed memory,
it is possible to make use of the message passing model. There
is a library project implementing a message passing interface
(MPI). Explicit communication is in place (message passing). This
solution brings also synchronization problems.
- SMP
- Market share for
- SMP
- biggest market share, both in money and in units
- Ex.: Multiprocessors in a chip.
- biggest market share, both in money and in units
- Multicomputers
- Ex.: Clusters for systems on the Internet.
- Ex.: > 100 processors (massively parallel processors MPP)
- Ex.: Clusters for systems on the Internet.
- SMP
- Observations about SMP
- Large and efficient cache systems can greatly
reduce the need for memory bandwidth
- Not much extra hardware is needed
- Based on general purpose processors (GPP)
- Base question for cache coherence problem:
Caches not only provide locality but also
replication. Is that a problem?
- Large and efficient cache systems can greatly
reduce the need for memory bandwidth
Medienanhänge
{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.