14523652
Description
Mind Map by david segura palacios, updated more than 1 year ago
|
|
Created by david segura palacios
over 5 years ago
|
|
Estadística Inferencial (MAPA MENTAL)
- 2 Teoría del muestreo
- De entrada, es de necesidad observar que en todo lo
revisado hasta ahora se ha supuesto que el conjunto
de datos con que se trabaja son muestras. Sin
embargo, en la realidad es difícil trabajar con
poblaciones enteras sino, más bien, con muestras.
Para ilustrar esto, se recuerda la definición de
población:
- Población: Conjunto de todas las
observaciones posibles sobre una
característica de interés observada.
- Lo que en la vida real se hace, como el INEGI, es trabajar no con la población
de datos sino con una muestra de los mismos. Es decir, una parte de estos.
- Muestra: subconjunto de una población de la cual se
deriva.
- Muestra: subconjunto de una población de la cual se
deriva.
- Población: Conjunto de todas las
observaciones posibles sobre una
característica de interés observada.
- 2.1 Tipos de muestreo
- En este tema simplemente se explorarán las características
relacionadas a la forma de hacer muestras. En el siguiente tema: la
inferencia, se observará que el cálculo de parámetros como la media
y la desviación estándar cambian en una muestra respecto a una
población.
- Una parte de importancia a observar es que una muestra, según el tipo de
estudio que se haga, se realiza de diferentes formas. Por ejemplo, la
muestra de un grupo de aguacates en inventario o la que se obtiene con las
botellas de agua extraídas de una línea de producción se forma de manera
diferente a la que emplea una empresa de mercadotecnia para probar la
demanda de un producto. Esta diferencia radica en el uso que se dará a los
datos.
- En virtud de esto, se tienen cuatro tipos de muestreo o forma de hacer
muestras comúnmente utilizados:
- 1. Muestreo aleatorio simple
- 2. Muestreo
sistemático.
- 3. Muestreo de
racimo
- 4. Muestreo estratificado.
- 1. Muestreo aleatorio simple
- En virtud de esto, se tienen cuatro tipos de muestreo o forma de hacer
muestras comúnmente utilizados:
- Una parte de importancia a observar es que una muestra, según el tipo de
estudio que se haga, se realiza de diferentes formas. Por ejemplo, la
muestra de un grupo de aguacates en inventario o la que se obtiene con las
botellas de agua extraídas de una línea de producción se forma de manera
diferente a la que emplea una empresa de mercadotecnia para probar la
demanda de un producto. Esta diferencia radica en el uso que se dará a los
datos.
- 2.2 Muestreo aleatorio simple
- Como su nombre lo indica, consiste en seleccionar, de manera aleatoria, una
serie de observaciones, objetos o datos de una población sin seguir algún tipo de
agrupamiento específico
- Este tipo de muestreo es el más común pero tiene la limitante de que se
elijen muestras aleatorias y algún tipo de característica (como puede ser
color, procedencia, género, etc. En un grupo de personas) puede no ser
tomada en cuenta.
- Este tipo de muestreo es el más común pero tiene la limitante de que se
elijen muestras aleatorias y algún tipo de característica (como puede ser
color, procedencia, género, etc. En un grupo de personas) puede no ser
tomada en cuenta.
- 2.3 Muestreo
sistemático
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos
predeterminados. Por ejemplo, piense usted que tiene 2,000 cajas de aguacate
foliadas todas y listas para empacarse a Estados Unidos. Ahora elige primero la caja
número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una
muestra de 100 cajas a las que le puede realizar el estudio estadístico que necesita.
- El muestreo sistemático es muy útil. Sin embargo, tiene una limitante llamada introducción de sesgo. Para
ilustrar la idea, se le da un ejemplo: Suponga que usted es dueño de una cadena de farmacias y desea muestrear
el nivel de ventas de sus sucursales en Morelia haciendo el muestreo solo los días lunes. De entrada esto puede
ser bueno y práctico. Sin embargo, puede tener la limitante de que el patrón de consumo de sus clientes es bajo
los días lunes ya que es inicio de semana y desean gastar en otras cosas su dinero. Claramente, de hacer este
tipo de muestreo, usted estaría estimando ventas menores y correría el riesgo de tomar decisiones mal
informadas
- El muestreo sistemático es muy útil. Sin embargo, tiene una limitante llamada introducción de sesgo. Para
ilustrar la idea, se le da un ejemplo: Suponga que usted es dueño de una cadena de farmacias y desea muestrear
el nivel de ventas de sus sucursales en Morelia haciendo el muestreo solo los días lunes. De entrada esto puede
ser bueno y práctico. Sin embargo, puede tener la limitante de que el patrón de consumo de sus clientes es bajo
los días lunes ya que es inicio de semana y desean gastar en otras cosas su dinero. Claramente, de hacer este
tipo de muestreo, usted estaría estimando ventas menores y correría el riesgo de tomar decisiones mal
informadas
- 2.4 Muestreo
estratificado.
- En este tipo de muestreo, se divide la población de datos en grupos
homogéneos (mujeres y hombres, intervalo de pesos, etc.) y se determina qué
proporción representa cada estrato o grupo. Cuando se analizan las
características y parámetros como media, desviación estándar, etc., se
ponderan los mismos en función de su representación o proporción de peso
respecto la población total y con esa ponderación se obtienen los parámetros y
probabilidades totales de dicha población con este tipo de muestra.
- Por ejemplo, piense usted que desea saber el número medio de personas que entran a sus farmacias en
función de su edad. Por ejemplo, tendría usted una tabla como la siguiente:
- Por ejemplo, piense usted que desea saber el número medio de personas que entran a sus farmacias en
función de su edad. Por ejemplo, tendría usted una tabla como la siguiente:
- 2.5 Muestreo de
racimo.
- Esta forma de muestrear se parece a la
anterior, con la diferencia de que
primero se hacen estratos y luego se
seleccionan miembros, datos u
observaciones de cada uno de los
estratos de una manera aleatoria. Por
ejemplo, usted desea saber cuántas
televisiones existen en la ciudad de
Morelia. Entonces, usted divide la
ciudad en colonias y elige, de cada
colonia y de manera aleatoria, una serie
de casas, toca la puerta y pregunta el
número de televisiones que hay en cada
una. Con esto toma muestras aleatorias
no de la totalidad de la población sino
de cada uno de los grupos que usted
formó.
- 2.6 Diferencias operativas en cada uno de los tipos de
muestreo y determinación del empleado en Estadística
Inferencial.
- 2.7 Diseño de un experimento: el proceso que se sigue
para tomar decisiones.
- En Estadística aplicada a los negocios, es importante conducir de
manera apropiada la toma de decisiones. Si usted a esta altura ya llevó
una clase de Métodos de investigación o metodología de la
investigación, recordará el método científico. Aunque éste último es
más apropiado para la generación de conocimiento científico, la forma
en cómo se llega a una conclusión y a la toma de decisiones en los
negocios es muy similar.
- Para poder decidir usted sobre algo, primero debe plantearse un objetivo del cual se elabora una
hipótesis, luego se comprueba la misma y se decide en base a esta conclusión. Por ejemplo, en el caso
de Steve Jobs, él tenía como objetivo determinar si su modelo de computadora tendría
- mayor preferencia respecto a su competencia. Para esto, tuvo que plantear una hipótesis a
demostrar: “La computadora de mi compañía es más preferida que la de mi competencia”.
- El diseño de experimento o pasos del análisis estadístico a seguir son los siguientes (Se utilizará el
ejemplo de los comerciantes de aguacate):
- 1. Definir el objetivo: Los comerciantes definieron
como objetivo determinar que la calidad de sus
inventarios es la misma.
- 2. Definir lo que se medirá: Aquí los
comerciantes definieron “calidad”
como el peso de sus aguacates. En
pocas palabras pusieron una hipótesis
dada por: “Si nuestros inventarios de
aguacates tienen el mismo peso,
comparten la misma calidad”.
- 3. Definir el tamaño de muestra:
Aquí los comerciantes decidieron
no trabajar con la totalidad de su
inventario porque son miles de
aguacates pero acordaron tomar
una muestra de 200 aguacates
(cómo definir este número lo
veremos en breve).
- 4. Analizar los datos: Aquí se emplean técnicas
estadísticas, como es la comprobación de
hipótesis, para concluir si el objetivo planteado
se cumple o no. Por ejemplo, los comerciantes
determinaron, con técnicas estadísticas, que
sus inventarios son iguales.
- 5. Conclusión y toma de decisiones: En este
punto, en base al diseño del experimento
seguido hasta ahora, se concluye que los
inventarios tienen la misma calidad y toman la
decisión de no reclamar al proveedor.
- A manera de síntesis de dedo, se presentan los pasos del diseño experimental o proceso de análisis
estadístico:
- 1. Definir el
objetivo
- 2. Definir lo que se medirá (Aquí se plantea una
hipótesis estadística).
- 3. Definir el tamaño de
muestra.
- 4. Analizar los
datos.
- 5. Conclusión y toma de decisiones.
- 1. Definir el
objetivo
- 1. Definir el objetivo: Los comerciantes definieron
como objetivo determinar que la calidad de sus
inventarios es la misma.
- El diseño de experimento o pasos del análisis estadístico a seguir son los siguientes (Se utilizará el
ejemplo de los comerciantes de aguacate):
- mayor preferencia respecto a su competencia. Para esto, tuvo que plantear una hipótesis a
demostrar: “La computadora de mi compañía es más preferida que la de mi competencia”.
- Para poder decidir usted sobre algo, primero debe plantearse un objetivo del cual se elabora una
hipótesis, luego se comprueba la misma y se decide en base a esta conclusión. Por ejemplo, en el caso
de Steve Jobs, él tenía como objetivo determinar si su modelo de computadora tendría
- 2.8 Distribuciones de probabilidad muestrales
- Hasta ahora, se ha trabajado con el supuesto de que los
datos que se han estudiado pertenecen a una población.
Es decir, se ha supuesto que los datos con que se trabaja
es la totalidad que se pueden tener. Sin embargo, al
introducirnos en este nuevo tema de Teoría del
muestreo, hemos visto que, en la mayoría de las
ocasiones, es difícil obtener y manipular todos los datos
de una población.
- hacer un análisis estadístico con muestreo observando que tanto la media como la
desviación estándar pueden ser diferentes de muestra en muestra, implica que se tiene
incertidumbre o poca seguridad de tomar decisiones ya que la media y desviación
estándar de la muestra no son la misma que la de la población.
- Dado que en la mayoría de las ocasiones, usted utilizará
muestras y no poblaciones8 , esta distribución de probabilidad
muestral será la que se utilizará. Ahora, dos preguntas
naturales que usted podría tener serían ¿Existe una diferencia
entre la normal estándar y la muestral? y ¿Cómo se calcula
esta función de probabilidad muestral? La respuesta a la
primera pregunta es: No en términos de cálculo, salvo un
pequeño ajuste que veremos en breve, no cambia en lo
absoluto. Es más incluso usted podrá seguir utilizando las
tablas de probabilidad normal estándar que empleó
previamente. La segunda pregunta, relativa a la fórmula de
cálculo se ve en el siguiente subtema.
- Que ahora la llamaremos error estándar (en breve veremos el por qué del nombre), Incluso en
ocasiones, como es el caso de los precios de una acción o la temperatura de un lugar, usted no podrá
conocer la población verdadera.
- Dado que en la mayoría de las ocasiones, usted utilizará
muestras y no poblaciones8 , esta distribución de probabilidad
muestral será la que se utilizará. Ahora, dos preguntas
naturales que usted podría tener serían ¿Existe una diferencia
entre la normal estándar y la muestral? y ¿Cómo se calcula
esta función de probabilidad muestral? La respuesta a la
primera pregunta es: No en términos de cálculo, salvo un
pequeño ajuste que veremos en breve, no cambia en lo
absoluto. Es más incluso usted podrá seguir utilizando las
tablas de probabilidad normal estándar que empleó
previamente. La segunda pregunta, relativa a la fórmula de
cálculo se ve en el siguiente subtema.
- ¿Qué sucede cuando hacen
esto? Para responder esto
imagine que tiene una población
total de 5,000 aguacates con
diferentes niveles de peso en
gramos. Esta población total
tendrá una distribución de
probabilidad determinada.
Ahora, si se extrae una muestra
de 30 aguacates, esta tendrá un
promedio y una desviación
estándar y, a su vez una
distribución de probabilidad con
una forma y valores
determinados. SI se repite dos
veces más el ejercicio de
muestreo, se verá que las
medias, las desviaciones
estándar y las distribuciones de
probabilidad son diferentes por
lo que, si se está trabajando con
una muestra, es muy prob
- hacer un análisis estadístico con muestreo observando que tanto la media como la
desviación estándar pueden ser diferentes de muestra en muestra, implica que se tiene
incertidumbre o poca seguridad de tomar decisiones ya que la media y desviación
estándar de la muestra no son la misma que la de la población.
- 2.8.1 Las estadísticas necesarias para calcular la distribución normal muestral
- Hasta ahora se ha revisado cómo se genera una función de
probabilidad normal estándar y se ha hecho énfasis en
observar que esta se revisó suponiendo que los datos con
que se trabaja son poblaciones. Sin embargo, usted tendrá
en su poder para trabajar, y salvo que el problema que usted
resuelva sea diferente, muestras.
- Cuando usted trabaja con poblaciones, las medidas
que son insumos necesarios para el cálculo de
probabilidades se llaman Parámetros. Es decir, si los
datos que usted tiene para analizar son la media y
la desviación estándar. A estos dos se les denomina
parámetros de su función de probabilidad.
- Sin embargo, para una función de probabilidad cuando usted
tiene muestras, los insumos son los mismos y se llaman ahora
estadísticas o medidas estadísticas. Y estas estadísticas son la
media y el error estándar (recuerde que así le llamamos a la
desviación estándar cuando tenemos datos de muestras).
- Sin embargo, para una función de probabilidad cuando usted
tiene muestras, los insumos son los mismos y se llaman ahora
estadísticas o medidas estadísticas. Y estas estadísticas son la
media y el error estándar (recuerde que así le llamamos a la
desviación estándar cuando tenemos datos de muestras).
- Cuando usted trabaja con poblaciones, las medidas
que son insumos necesarios para el cálculo de
probabilidades se llaman Parámetros. Es decir, si los
datos que usted tiene para analizar son la media y
la desviación estándar. A estos dos se les denomina
parámetros de su función de probabilidad.
- 2.8.2 Media
muestral
- Como puede apreciar, la función de probabilidad normal estándar sigue
utilizándose. Lo único que cambian son la forma de calcular la media y la
desviación estándar.
- Como una nota adicional, también es de importancia observar que esta
aproximación se cumple incluso si se tienen múltiples muestras con
diferente tamaño. Es decir, una muestra de 30 aguacates, otra de 200 y así
sucesivamente.
- Como una nota adicional, también es de importancia observar que esta
aproximación se cumple incluso si se tienen múltiples muestras con
diferente tamaño. Es decir, una muestra de 30 aguacates, otra de 200 y así
sucesivamente.
- 2.8.3 Error
estándar
- En el sub tema anterior se dijo que el tamaño de la muestra no influía en el
cálculo de la media muestral y que sería la misma media para población
que para muestra. Sin embargo, en el caso de la desviación estándar
aplicable a una muestra, mejor conocida como error estándar, la cosa
cambia.
- el error estándar es el error o separación que la media de su muestra tiene respecto a la
verdadera media de la población y este se aproxima muy bien al simplemente dividir la
desviación estándar de su muestra entre la raíz cuadrada del número de observaciones
que integran su muestra.
- Error estándar: separación
que la media de su muestra
tiene respecto a la verdadera
media de la población y este
se aproxima muy bien al
simplemente dividir la
desviación estándar de su
muestra entre la raíz
cuadrada del número de
observaciones que integran
su muestra.
- Error estándar: separación
que la media de su muestra
tiene respecto a la verdadera
media de la población y este
se aproxima muy bien al
simplemente dividir la
desviación estándar de su
muestra entre la raíz
cuadrada del número de
observaciones que integran
su muestra.
- el error estándar es el error o separación que la media de su muestra tiene respecto a la
verdadera media de la población y este se aproxima muy bien al simplemente dividir la
desviación estándar de su muestra entre la raíz cuadrada del número de observaciones
que integran su muestra.
- 2.8.4 Cálculo de probabilidades con muestras.
- Para calcular la probabilidad en una muestra
se sigue utilizando la misma tabla de
distribución normal estándar y se siguen los
mismos métodos de cálculo previamente
vistos. Lo único que cambia es la fórmula 6 a
la que se le sustituye la desviación estándar
por el error estándar
- Como se aprecia, el método de cálculo de
probabilidades con muestras sigue siendo el
mismo. Lo único que cambia es que se calcula el
error estándar y en lugar de la desviación
estándar.
- Como se aprecia, el método de cálculo de
probabilidades con muestras sigue siendo el
mismo. Lo único que cambia es que se calcula el
error estándar y en lugar de la desviación
estándar.
- 2.9 El teorema del límite central y una primera forma
de determinar el tamaño adecuado de la muestra
- Hasta ahora se ha trabajado con el supuesto de que
las variables aleatorias que se estudian están
normalmente distribuidas. Sin embargo puede darse
el caso de que esto no sea así. Cuando usted, con
técnicas de las que se revisarán algunas en temas
posteriores, detecta que los datos con que trabaja
no están normalmente distribuidos, puede seguir
manejando el supuesto de normalidad si incrementa
el número de datos de su muestra.
- plantearse usted sería ¿Qué tan grande debe ser mi
muestra para darle validez al Teorema del Límite
Central? La mayoría de los estadísticos sugiere que
debe cumplirse una de las siguientes condiciones
para considerar la muestra “grande”:
- 1. Que el número de observaciones de la
muestra sea mayor de 30. Esto es: n 30
- 2. O que el número de datos de su muestra
tenga una proporción menor o igual al 5% de la
población total.
- Por ejemplo, si usted quiere determinar cuál es el tamaño
apropiado de muestra para un análisis estadístico aplicado el
precio de una acción o la temperatura de Morelia, usted
deberá elegir 30 o más datos para considerar “grande” su
muestra y darle validez al teorema del límite central. Casos
como estos dos son situaciones en las que usted desconoce el
verdadero tamaño de la población total.
- Teorema del límite
central:
- “Una muestra de datos que no tenga una
distribución de probabilidad normal podrá
suponerse que está normalmente distribuida
si su número de datos es mayor o igual a 30.
si se conoce el tamaño total de la población
(y estas es muy grande), su número de datos es
menor o igual al 5% de la población total…”
- Por tanto, para regla general de usted y a reserva de ver otras
más, si usted quiere determinar si su muestra está
normalmente distribuida y no sabe cuántos datos debe tener
como mínimo, recuerde el teorema del límite central revisado
que le pide mínimo 30 datos. Por tanto, un tamaño adecuado
de muestra, como regla general, es de 30 observaciones.
- Habrá ocasiones en que usted no tenga capacidad material
de obtener 30 datos sino menos. Para esos casos se utiliza
una distribución t-Student. De momento, no la veremos para
que usted sea capaz de asimilar estas ideas. Este tipo de
distribución se revisará en el tema de comprobación de
hipótesis.
- Habrá ocasiones en que usted no tenga capacidad material
de obtener 30 datos sino menos. Para esos casos se utiliza
una distribución t-Student. De momento, no la veremos para
que usted sea capaz de asimilar estas ideas. Este tipo de
distribución se revisará en el tema de comprobación de
hipótesis.
- “Una muestra de datos que no tenga una
distribución de probabilidad normal podrá
suponerse que está normalmente distribuida
si su número de datos es mayor o igual a 30.
si se conoce el tamaño total de la población
(y estas es muy grande), su número de datos es
menor o igual al 5% de la población total…”
- Teorema del límite
central:
- 1. Que el número de observaciones de la
muestra sea mayor de 30. Esto es: n 30
- plantearse usted sería ¿Qué tan grande debe ser mi
muestra para darle validez al Teorema del Límite
Central? La mayoría de los estadísticos sugiere que
debe cumplirse una de las siguientes condiciones
para considerar la muestra “grande”:
- 2.10El multiplicador de población finita
- Para finalizar la revisión de la Teoría del muestreo que
contempla este segundo tema del curso de Estadística
II. Es de interés observar algo más del cálculo del
error estándar
- 3 Estimaciones puntuales y de intervalo. La base de la
inferencia estadística.
- En el tema anterior se introdujo el concepto de que la media muestral puede ser diferente respecto a la
poblacional e incluso entre muestras. Eso llevó a observar como momentáneamente válida la aproximación
de dicha media poblacional a través de la media de la muestra con que se trabaja x . Sin embargo, sigue
presente el efecto de la incertidumbre que se genera al ver fluctuar x . Aquí es donde las estimaciones
puntuales y de intervalo cobran vida como conceptos
- Durante su vida profesional, usted, para tomar decisiones, deberá siempre hacer estimaciones de qué
sucederá en el futuro. Se vio al inicio de estas notas que usted siempre decidirá en un entorno de riesgo y uno
de los riesgos a considerar es el hecho de que su muestra, si tiene datos de muestrales, es toda la información
que tendrá para decidir.
- Cuando usted estime qué sucederá en el futuro, puede hacer dos tipos de estimaciones:
- Estimaciones puntuales: Es un solo número
que se utiliza para estimar un parámetro de
la población: la media poblacional.
- La forma más común de obtener este tipo de estimación puntual es simplemente
utilizar la media muestral x . Sin embargo, el utilizar x está sujeto a cometer errores
de muestra por lo que es más apropiado hacer afirmaciones o estimaciones del tipo:
El día de mañana a las 12:00 la temperatura podría estar entre 20° y 21° o el nivel de
llenado de la botella puede estar entre 996 l y 997l.Este tipo de afirmación se conoce
como estimación de intervalo.
- Estimación de intervalo: Es un rango de
valores que se utiliza para estimar un
parámetro de la población.
- Estimación de intervalo: Es un rango de
valores que se utiliza para estimar un
parámetro de la población.
- Estimaciones puntuales: Es un solo número
que se utiliza para estimar un parámetro de
la población: la media poblacional.
- Cuando usted estime qué sucederá en el futuro, puede hacer dos tipos de estimaciones:
- Durante su vida profesional, usted, para tomar decisiones, deberá siempre hacer estimaciones de qué
sucederá en el futuro. Se vio al inicio de estas notas que usted siempre decidirá en un entorno de riesgo y uno
de los riesgos a considerar es el hecho de que su muestra, si tiene datos de muestrales, es toda la información
que tendrá para decidir.
- 3.1 Consideraciones para calcular verdaderas estimaciones de intervalo
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se exponen
las 30 muestras aleatorias en comparación a la media poblacional.
- Si usted quisiera hacer una estimación puntual del precio para el día siguiente en dicha acción podría calcular
la media muestral10 que es de x 26.4666 . Sin embargo, usted sabe que esta media no es la misma que la de la
población ya que podría fluctuar de muestra en muestra. Por tanto se podría calcula el error estándar de la
media muestral
- Si usted quisiera hacer una estimación puntual del precio para el día siguiente en dicha acción podría calcular
la media muestral10 que es de x 26.4666 . Sin embargo, usted sabe que esta media no es la misma que la de la
población ya que podría fluctuar de muestra en muestra. Por tanto se podría calcula el error estándar de la
media muestral
- 3.1.1 El verdadero cálculo del error muestral cuando se
desconoce la desviación estándar de la población.
- Sin embargo, algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la
desviación estándar de la población y en realidad lo que se está calculando la de una muestra.
- 3.1.2 La estimación de
intervalo.
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que
reconoce que este valor puede cambiar de muestra en muestra y que
tiene el cálculo del error estándar de la muestra calculado con la fórmula
11, procederá usted a hacer una afirmación de este tipo: “El precio de la
acción se estima que sea de $26.4666 y, con un 95% de confianza, se
espera que ese valor oscile entre $26.6533 y $28.2802.” Si usted observa la
gráfica 26, quizá no le sea muy preciso el pronóstico en el sentido de que
el precio esperado y su intervalo están muy abajo. Con el análisis de
regresión podremos mejorar la precisión. Baste con suponer, de
momento, que la media muestral es buen pronóstico del valor futuro.
- Un ejemplo que puede ser más
apropiado podría ser el del comerciante
de aguacates. De una muestra de 30
aguacates, usted puede llegar a una
media muestral de x g 153.0547 y un
error
- estándar calculado con la fórmula 11 de 57.6770 x g . Con estos
datos podría decir que su estimación del peso de un solo aguacate que
tome de manera aleatoria podría ser de 153.0547 g. y que esta
estimación podría, con un 95% de probabilidad, variar entre 58.1844 g
y 247.9249 g.
- Un ejemplo que puede ser más
apropiado podría ser el del comerciante
de aguacates. De una muestra de 30
aguacates, usted puede llegar a una
media muestral de x g 153.0547 y un
error
- 3.2 ¿Qué pasa cuando nuestra muestra de datos no es
grande? La distribución t-Student
- Hasta ahora se ha trabajado con el supuesto de que los datos
(sean de población o de muestra) están normalmente distribuidos
ya sea porque así nos conviene o porque hemos trabajado con
muestras con más de 30 datos, situación que satisface el Teorema
del Límite Central previamente revisado.
- Sin embargo, no siempre se tiene la posibilidad de tener muestras de 30 datos sino más pequeñas. Un
ejemplo muy claro puede estar en la contabilidad de una empresa. Suponga que usted desea hacer un
análisis estadístico y calcular la distribución de probabilidad del ROI11 y que solo tiene 12 trimestres de
información. Claramente la distribución normal estándar no es de utilidad porque viola el Teorema del límite
central. ¿Qué se hace entonces? ¿Qué función de probabilidad se puede utilizar?
- Muy simple: Hay un tipo de función de probabilidad, de los cuatro que revisaremos en el curso, que sirve para
este fin. Esta se llama distribución t-Student o simplemente distribución t.
- Esta distribución fue propuesta por W.S. Gosset quien era un trabajador de la cervecería Guinness en Dublín.
El hombre era un aficionado a la Estadística y, como la cervecería prohibía a sus empleados hacer
publicaciones científicas y académicas, Gosset utilizó el pseudónimo de “Student” para poder publicar su
artículo y hacer su gran aportación a la Estadística.
- Antes de hablar de los tres parámetros (uno más respecto a la normal) que se necesitan para calcular la
distribución t-Student imagine usted que tiene tres muestras con la misma media:
- 1. Una con más de 30 datos a la que le podemos
calcular la probabilidad normal.
- 2. Una con solo 5 datos que se
le calcula una función de
probabilidad t-Student.
- 3. Una con 20 datos que
también se le calcula una
función de probabilidad
t-Student.
- No siempre se tienen muestras con una cantidad de datos u observaciones mayor o igual a 30. Cuando esto
sucede, los datos no están normalmente distribuidos pero se pueden hacer estimaciones de intervalo
utilizando la distribución t-Student.
- 1. Una con más de 30 datos a la que le podemos
calcular la probabilidad normal.
- Antes de hablar de los tres parámetros (uno más respecto a la normal) que se necesitan para calcular la
distribución t-Student imagine usted que tiene tres muestras con la misma media:
- Esta distribución fue propuesta por W.S. Gosset quien era un trabajador de la cervecería Guinness en Dublín.
El hombre era un aficionado a la Estadística y, como la cervecería prohibía a sus empleados hacer
publicaciones científicas y académicas, Gosset utilizó el pseudónimo de “Student” para poder publicar su
artículo y hacer su gran aportación a la Estadística.
- Muy simple: Hay un tipo de función de probabilidad, de los cuatro que revisaremos en el curso, que sirve para
este fin. Esta se llama distribución t-Student o simplemente distribución t.
- Sin embargo, no siempre se tiene la posibilidad de tener muestras de 30 datos sino más pequeñas. Un
ejemplo muy claro puede estar en la contabilidad de una empresa. Suponga que usted desea hacer un
análisis estadístico y calcular la distribución de probabilidad del ROI11 y que solo tiene 12 trimestres de
información. Claramente la distribución normal estándar no es de utilidad porque viola el Teorema del límite
central. ¿Qué se hace entonces? ¿Qué función de probabilidad se puede utilizar?
- 3.2.1 Los parámetros para calcular la distribución t-Student y su
empleo para el cálculo de estimaciones de intervalo.
- Se ha visto previamente que la distribución normal, a
parte del valor de la variable aleatoria i x , necesita solo
dos simples parámetros o estadísticas12 que son la
media y la desviación estándar. Para el caso de la
distribución t-Student se siguen utilizando estos dos más
uno llamado Grados de libertad (denotado como GL o ).
- ¿Qué es esto de los grados de libertad?
- Grados de libertad: Número de
valores de una muestra que
podemos especificar
libremente, una vez que se
sabe la media de la muestra.
- Función de densidad de probabilidad t-Student: Función de densidad de probabilidad que es la más utilizada
y requiere de solo cuatro parámetros para su cálculo, el valor aleatorio ( i x ) al que se le determinará la
probabilidad, la media (), la desviación estándar () y los grados de libertad. A diferencia de la normal o
normal estándar, se emplea cuando nuestra muestra tiene menos de 30 datos (es muestra pequeña).
- Grados de libertad: Número de
valores de una muestra que
podemos especificar
libremente, una vez que se
sabe la media de la muestra.
- ¿Qué es esto de los grados de libertad?
- 3.3 Estimaciones de intervalo para comparar medias3.3.1.1
Estimación de intervalo para muestras apareadas grandes
- Recuerde usted que, por el Teorema del Límite central, se puede considera una muestra como “grande” si tiene
más de 30 observaciones e incluso se puede suponer que está distribuida si el tamaño de dicha muestra es
menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se tienen 4 grupos
de 20 individuos que dan un total de 80 diferencias o diferencias de calificaciones entr aceptar el supuesto de
que es muestra grande y de que está normalmente distribuida.
- que probablemente el Sr. Jobs primero hizo un muestreo de racimo. Recordando la nota legal, se mencionó
que esta es una mera suposición y resulta ser lo que muchos analistas de mercado o mercadólogos harían
por su empresa para saber la superioridad de su producto respecto al de la competencia.
- Recordando los comentarios iniciales del muestreo de racimo, se observó que este consiste en separar una
población en diferentes grupos de interés y luego tomar una muestra de cada segmento, estrato o grupo de
interés para tomar una muestra aleatoria de cada uno. ¿Qué pudo hacer el Sr. Jobs? De entrada separó su
población objetivo (usuarios de computadoras) en cuatro grupos o estratos de interés:
- 1. Arquitectos ingenieros, matemáticos, físicos,
investigadores y profesionistas que ocupen
procesamiento de cálculo. 2. Diseñadores
gráficos, artistas de medios, músicos y gente
que ocupe procesamiento gráfico. 3. Amas de
casa, estudiantes y gente mayor. 4.
Contadores, abogados, economistas,
financieros y otros profesionistas
- De cada uno de ellos seleccionó y entrevistó a 20 individuos, a los que les aplicó un cuestionario con una serie
de preguntas sobre capacidad de procesamiento, facilidad de manejo, costo y calidad. Para esto, el Sr. Jobs les
prestó a cada individuo tanto una Macbook como una PC de alta potencia durante un periodo de tiempo y
luego les aplicó el cuestionario. Las calificaciones que arroja el mismo iban de 0 para una mala calificación de
calidad, precio y procesamiento, es decir, una preferencia muy baja, hasta un 10 que es el nivel máximo de
preferencia que pueden tener por la computadora (Mac o PC)
- Con estas estimaciones, el Sr. Jobs podría hacer la siguiente afirmación: “La calificación de preferencia una
Mac respecto a una PC será superior en el mercado en 1.6802 puntos y esta puede fluctuar como máximo y
mínimo, con un nivel de confianza de 95%, entre 2.9122 y 0.4482”. Por tanto, partiendo del criterio de que la
superioridad de la Mac se da por un valor positivo de la diferencia de calificaciones recibidas entre esta y la
competencia, se puede observar que incluso en el escenario más pesimista, dado con el intervalo inferior, la
diferencia de las preferencias del consumidor está a favor de la computadora de Apple.
- Con estas estimaciones, el Sr. Jobs podría hacer la siguiente afirmación: “La calificación de preferencia una
Mac respecto a una PC será superior en el mercado en 1.6802 puntos y esta puede fluctuar como máximo y
mínimo, con un nivel de confianza de 95%, entre 2.9122 y 0.4482”. Por tanto, partiendo del criterio de que la
superioridad de la Mac se da por un valor positivo de la diferencia de calificaciones recibidas entre esta y la
competencia, se puede observar que incluso en el escenario más pesimista, dado con el intervalo inferior, la
diferencia de las preferencias del consumidor está a favor de la computadora de Apple.
- 1. Arquitectos ingenieros, matemáticos, físicos,
investigadores y profesionistas que ocupen
procesamiento de cálculo. 2. Diseñadores
gráficos, artistas de medios, músicos y gente
que ocupe procesamiento gráfico. 3. Amas de
casa, estudiantes y gente mayor. 4.
Contadores, abogados, economistas,
financieros y otros profesionistas
- Recordando los comentarios iniciales del muestreo de racimo, se observó que este consiste en separar una
población en diferentes grupos de interés y luego tomar una muestra de cada segmento, estrato o grupo de
interés para tomar una muestra aleatoria de cada uno. ¿Qué pudo hacer el Sr. Jobs? De entrada separó su
población objetivo (usuarios de computadoras) en cuatro grupos o estratos de interés:
- que probablemente el Sr. Jobs primero hizo un muestreo de racimo. Recordando la nota legal, se mencionó
que esta es una mera suposición y resulta ser lo que muchos analistas de mercado o mercadólogos harían
por su empresa para saber la superioridad de su producto respecto al de la competencia.
- 3.3.1.2 Estimación de intervalo para muestras apareadas pequeñas
- Como se vio previamente para trabajar con estimaciones de
muestra pequeñas, las fórmulas de cálculo del límite superior e
inferior de la estimación de intervalo siguen siendo los
mismos.
- Para simplificar el ejemplo del Sr. Jobs, supongamos que los datos de la tabla 12, no son muestra grande sino
pequeña y, para esto suponga que los valores de D y D de dicha tabla son de una muestra de solo 26
observaciones. Por tanto, si el número de observaciones es de 26, los grados de libertad son 25. Por tanto,
al buscar en la tabla t para un nivel de significancia de 5% (el inverso de un nivel de confianza de 95%) con 25
grados de libertad, se llega a un valor 2.0595
- Para simplificar el ejemplo del Sr. Jobs, supongamos que los datos de la tabla 12, no son muestra grande sino
pequeña y, para esto suponga que los valores de D y D de dicha tabla son de una muestra de solo 26
observaciones. Por tanto, si el número de observaciones es de 26, los grados de libertad son 25. Por tanto,
al buscar en la tabla t para un nivel de significancia de 5% (el inverso de un nivel de confianza de 95%) con 25
grados de libertad, se llega a un valor 2.0595
- 3.3.2 Estimaciones de intervalo para muestras independientes
- Para poder calcular las estimaciones de intervalo de diferencias de muestras independientes, lo único
que debe cambiar es la forma de calcular estándar de las mismas
- Antes de proceder a un tema muy importante y sencillo (una vez que se domina esto) es necesario
responder dos preguntas que quedaron sueltas:
- 1. Se ha dicho que las estimaciones de intervalo tienen un grado de confianza de X%. ¿cómo se
determina el mismo? Ya que, si incrementamos el grado de confianza o lo reducimos, podemos
manipular las cifras de nuestras estimaciones. 2. Se ha hablado de muestras grandes y muestras
pequeñas y se sugiere que el tamaño apropiado es que n≥30 para que los datos se acepte el supuesto
de que los datos distribuyan normalmente. ¿Hay otra forma de determinar el tamaño óptimo de la
muestra? 3. Hasta ahora se está trabajando con muestras “bien portadas”. Es decir que no se da la
presencia de lo que se conoce como datos atípicos. Estos ¿qué son? Datos cuyo valor se sale
notablemente del resto. Por ejemplo, un aguacate de medio kilo en el ejemplo de los aguacateros.
- 1. Se ha dicho que las estimaciones de intervalo tienen un grado de confianza de X%. ¿cómo se
determina el mismo? Ya que, si incrementamos el grado de confianza o lo reducimos, podemos
manipular las cifras de nuestras estimaciones. 2. Se ha hablado de muestras grandes y muestras
pequeñas y se sugiere que el tamaño apropiado es que n≥30 para que los datos se acepte el supuesto
de que los datos distribuyan normalmente. ¿Hay otra forma de determinar el tamaño óptimo de la
muestra? 3. Hasta ahora se está trabajando con muestras “bien portadas”. Es decir que no se da la
presencia de lo que se conoce como datos atípicos. Estos ¿qué son? Datos cuyo valor se sale
notablemente del resto. Por ejemplo, un aguacate de medio kilo en el ejemplo de los aguacateros.
- Antes de proceder a un tema muy importante y sencillo (una vez que se domina esto) es necesario
responder dos preguntas que quedaron sueltas:
- 3.4 ¿Cómo determinar el intervalo de confianza?
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el
nivel de confianza que se imprimirá a las estimaciones de intervalo.
Sin embargo, estas salen de la óptica y grado de exigencia del curso ya
que en el mismo se le enseñará a dominar las principales técnicas
estadísticas de utilidad para su vida profesional. Si usted desea
profundizar en esto, puede cursar una maestría en administración o
una en finanzas que logre ese grado de profundización o puede
consultar fuentes más avanzadas en Econometría o análisis de datos
multivariante.
- Para usted, sea suficiente saber que un nivel de confianza de 90% o mayor es más que suficiente y
que no debe de bajar de dicho valor para poder generar buenas estimaciones.
- Para usted, sea suficiente saber que un nivel de confianza de 90% o mayor es más que suficiente y
que no debe de bajar de dicho valor para poder generar buenas estimaciones.
- 3.5 ¿Cómo determinar el tamaño de muestra cuando se busca
incrementar la precisión del intervalo de confianza?
- Ya para finalizar el tema de la Teoría del muestreo es necesario completar
un poco más una pregunta que se planteó previamente ¿Qué tan grande
debe ser la muestra para tener un estudio estadístico adecuado? Esta
pregunta se respondió en una primera instancia con el Teorema del límite
central que sugiere que la muestra sea mayor o igual a 30 observaciones
para poder suponer que los datos se distribuyen normalmente. Sin
embargo, el mismo se aplica cuando la población de datos del fenómeno
en estudio es muy grande y, por ende, se desconoce el verdadero valor de
la desviación estándar poblacional (σ).
- uede darse el caso de que usted sí conozca la desviación estándar de la población y es
entonces cuando usted puede determinar el tamaño de la muestra que debe utilizar
para poder ser más preciso en sus estimaciones puntuales de intervalo. Es decir lograr
que su media muestral y error estándar se aproximen a los mismos parámetros
calculados en la población.
- Cuando se logra que la media muestral sea igual o muy próxima a la de la población, se dice que la
muestra es insesgada. Cuando la media muestral es mayor que la poblacional, se dice que tiene sesgo
positivo y, cuando sucede lo contrario, tienen sesgo negativo.
- Cuando se logra que el error estándar sea igual o aproximado a la desviación estándar de la
población, se dice que la muestra es eficiente.
- Cuando se logra que el error estándar sea igual o aproximado a la desviación estándar de la
población, se dice que la muestra es eficiente.
- Cuando se logra que la media muestral sea igual o muy próxima a la de la población, se dice que la
muestra es insesgada. Cuando la media muestral es mayor que la poblacional, se dice que tiene sesgo
positivo y, cuando sucede lo contrario, tienen sesgo negativo.
- uede darse el caso de que usted sí conozca la desviación estándar de la población y es
entonces cuando usted puede determinar el tamaño de la muestra que debe utilizar
para poder ser más preciso en sus estimaciones puntuales de intervalo. Es decir lograr
que su media muestral y error estándar se aproximen a los mismos parámetros
calculados en la población.
- 4 Prueba de hipótesis: La técnica clásica
- Hasta ahora se ha visto una de las aplicaciones de la Estadística inferencial que es la estimación de
valores futuros dados los datos muestrales con que se cuenta. Ahora se revisará una de las técnicas
más útiles y necesarias de la misma, la cual no será excepción en aplicaicones de su empresa y futuras
materias de su carrera como pueden ser Producción, Administración de la calidad o Finanzas. Esta
técnica de la que se habla es: la prueba de hipótesis.
- 1. Definir el objetivo: Definir el objetivo de la decisión que se va a
hacer. Por ejemplo, determinar si la calidad del inventario es buena
o no, si el número de piezas desperdiciadas es mayor a cierta
cantidad, si el número de trimestres con pérdida es mayor a cierto
objetivo o si el número de conexiones fallidas en un sistema de
cómputo es mayor a determinada cantidad objetivo que se define
en los estándares de calidad de la empresa de comunicaciones.
Estos ejemplos se dan por citar algunos casos de lo que podría
presentársele en su vida cotidiana.
- 2. Definir lo que se medirá: Aquí
usted definirá cuál será la variable
que delimitará la toma de sus
decisiones. Por ejemplo “La
cantidad de desperdicio” o el
número de trimestres con pérdidas”.
- 3. Definir el tamaño de muestra: Esto es de
vital importancia y se ha revisado en temas
anteriores. Si usted no conoce el verdadero
tamaño de la población ni sus parámetros
como son la media y la desviación estándar,
entonces apelará al teorema del límite
central. Si se encuentra al caso contrario,
usted empleará la fórmula 22 si y solo si se le
proporciona algún valor que corresponda a la
desviación estándar de dicha población.
- 4. Analizar los datos: Aquí se pueden utilizar varias técnicas de análisis. De
entrada pueden ser lastécnicas de estimación (puntual y de intervalo) y la
comprobación de hipótesis.
- 5. Conclusión y toma de decisiones: Para fines del tema que interesa, una vez que se aplica la
comprobación de hipótesis, se tiene una conclusión de la que se toma una decisión en la empresa.
- 1. Definir el objetivo: Definir el objetivo de la decisión que se va a
hacer. Por ejemplo, determinar si la calidad del inventario es buena
o no, si el número de piezas desperdiciadas es mayor a cierta
cantidad, si el número de trimestres con pérdida es mayor a cierto
objetivo o si el número de conexiones fallidas en un sistema de
cómputo es mayor a determinada cantidad objetivo que se define
en los estándares de calidad de la empresa de comunicaciones.
Estos ejemplos se dan por citar algunos casos de lo que podría
presentársele en su vida cotidiana.
- 4.1 Comprobación de hipótesis de una sola muestra.
- Para exponer el concepto de la prueba de hipótesis se
deben recordar tanto la forma de hacer estimaciones
como el cálculo de probabilidades empleando valores
Z o valores t. Para iniciar con la exposición de la idea
recordemos al ejemplo de los comerciantes de
aguacate. En concreto, centremos la atención de la
empresaria de Chicago. Suponga usted que ella busca
definir que la calidad de su inventario (recordemos
que este concepto está medido a través del peso de
cada fruta) debe ser mayor a 3.8 onzas (Oz.) para decir
que tiene buena calidad. Suponga que la empresaria
toma una muestra de 30 aguacates de su inventario
total de 5,000 y la experiencia de inventarios previos le
dice que la desviación estándar en el peso de los
aguacates es de 1.1 Oz. Es decir, aquí no se tiene
medida la desviación estándar de una población pero
se supone que ésta desviación estándar, que se logra
con la experiencia de inventarios previos, es una
aproximación adecuada13 .
- Para poder responder esta pregunta de si el inventario cubre los
estándares de calidad de la empresa, la comerciante de Chicago tuvo que
hacer los tres primeros pasos del proceso de toma de decisiones con la
Estadística:
- 1. Definir el objetivo: Determinar si el estándar de
calidad mínimo requerido se cumple en el inventario.
- 2. Definir lo que se medirá: Definir “calidad” como sinónimo de peso de
la fruta: Más peso=más calidad.
- 3. Definir el tamaño de muestra: En base al Teorema
del límite central previamente visto, la empresaria
decide hacer una muestra de 30 piezas.
- El cuarto paso correspondería al análisis de datos y es en ese punto donde
se realiza la comprobación de hipótesis. En términos generales, lo que se
busca hacer en una comprobación de hipótesis con la técnica clásica es
determinar que, dada la muestra de datos que se tiene, la media de la
misma es igual, más grande o más pequeña que la media de la población o
media objetivo.
- Definición de prueba de hipótesis: Método para evaluar creencias o afirmaciones
sobre la realidad en base en la evidencia estadística, de tal forma que se
determine la validez de dichas creencias o afirmaciones.
- Para poder comprobar la hipótesis es necesario establecer que, en el caso
de la técnica clásica, lo que se busca demostrar es que la media de la
muestra empleada es parecida, inferior o superior a una media poblacional
o a una aproximación de la misma dada a través de una media hipotética u
objetivo.
- Como se ha visto, la comprobación de hipótesis es un procedimiento estadístico, comprendido en el
cuarto paso del proceso de toma de decisiones, el cual, a su vez, realiza los siguientes pasos:
- El proceso de comprobación de hipótesis: 1. Definir una hipótesis
nula a demostrar: Se plantea el enunciado (hipótesis) a
demostrar y se plantean la hipótesis nula ( H0 ) y la alternativa (
Ha ). 2. Se determina, dada la hipótesis, si es prueba dos colas,
cola superior y cola inferior. 3. Se define el grado de
significancia: Este es el contrario al intervalo de confianza. Es
decir, si se tiene 5% de significancia, se tiene 95% de confianza.
Aquí se calculan los valores Z o t con las expresiones de las
formulas 24 y 25. 4. Se define si se trabaja con la escala original
o con una estandarizada. 5. Se define la regla de aceptación. 6.
Se comparan los valores críticos fijados con los estadísticos
(valor Z o media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ).
- El proceso de comprobación de hipótesis: 1. Definir una hipótesis
nula a demostrar: Se plantea el enunciado (hipótesis) a
demostrar y se plantean la hipótesis nula ( H0 ) y la alternativa (
Ha ). 2. Se determina, dada la hipótesis, si es prueba dos colas,
cola superior y cola inferior. 3. Se define el grado de
significancia: Este es el contrario al intervalo de confianza. Es
decir, si se tiene 5% de significancia, se tiene 95% de confianza.
Aquí se calculan los valores Z o t con las expresiones de las
formulas 24 y 25. 4. Se define si se trabaja con la escala original
o con una estandarizada. 5. Se define la regla de aceptación. 6.
Se comparan los valores críticos fijados con los estadísticos
(valor Z o media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ).
- Como se ha visto, la comprobación de hipótesis es un procedimiento estadístico, comprendido en el
cuarto paso del proceso de toma de decisiones, el cual, a su vez, realiza los siguientes pasos:
- Definición de prueba de hipótesis: Método para evaluar creencias o afirmaciones
sobre la realidad en base en la evidencia estadística, de tal forma que se
determine la validez de dichas creencias o afirmaciones.
- 1. Definir el objetivo: Determinar si el estándar de
calidad mínimo requerido se cumple en el inventario.
- Para poder responder esta pregunta de si el inventario cubre los
estándares de calidad de la empresa, la comerciante de Chicago tuvo que
hacer los tres primeros pasos del proceso de toma de decisiones con la
Estadística:
- 4.1.1.1 Pruebas de hipótesis para demostrar igualdad de la
media muestral con una media poblacional conocida o
hipotética.
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media objetivo
o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la comerciante de
Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar mejor el empleo de la
prueba de hipótesis en diferentes circunstancias.
- El objetivo de la empresaria para este primer caso es determinar que un
embarque de 5,000 piezas de aguacate que le acaba de llegar se ajusta a su
estándar de calidad de 3.8 onzas que es el valor que define a la media
poblacional hipotética ( Ho ). Para ello tomó 30 piezas de dicho embarque y
siguió los siguientes pasos para demostrar que la calidad del mismo se ajusta
al objetivo planteado. Esto lo hizo siguiendo los pasos que se presentan:
- 1. Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de
aguacates recibido tiene una calidad (peso)
igual a 3.8 Oz”. Esto se representa con la
siguiente hipótesis nula a demostrar y su
alternativa:
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola
superior y cola inferior: Aquí es importante observar, siguiendo
las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID
1, ya que se busca demostrar una igualdad:
- 1. Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de
aguacates recibido tiene una calidad (peso)
igual a 3.8 Oz”. Esto se representa con la
siguiente hipótesis nula a demostrar y su
alternativa:
- 4.1.1.1.1 Prueba de hipótesis para
demostración de igualdad empleando
muestras grandes
- De entrada, la comerciante de Chicago tiene el siguiente inventario, al cual
se le establecen la media hipotética de 3.8 . Ho Oz y una desviación
estándar poblacional, determinada con la experiencia previa de la
empresaria, de 1.1 .
- 4.1.1.1.2 Prueba de hipótesis para demostración de
igualdad empleando una muestra grande y una escala
estandarizada.
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una
escala estandarizada. Es decir, se aplicará la fórmula del cálculo del valor Z dada
en la fórmula 9 a la media muestral a contrastar, considerando que es muestra
grande.
- 4.1.1.1.3 Prueba de hipótesis para un caso de
demostración de igualdad con una muestra pequeña
con escala original.
- Note usted cómo se empleó, para las pruebas anteriores, la escala original y el valor Z ya sea para
realizar las estimaciones de intervalo o para definir el estadístico de prueba en una escala
estandarizada. Sin embargo ¿Qué hubiera sucedido si la empresaria hubiera tomado sólo 15 aguacates
en lugar de 30 y hubiese decidido emplear la escala original (onzas)? En este punto, la muestra sería
pequeña y la media muestralsería ahora de X 5.1318:
- 4.2 ¿Cuándo se utiliza la escala original y cuándo la estandarizada?
- Hasta el momento se ha observado que una de las variantes que puede tener la comprobación de
hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada,
lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra. Sin embargo, poco se ha
dicho sobre el criterio para utilizar una escala u otra. En realidad, no existen reglas generales para
decidir. Más bien la selección se da en función del tipo de problema y las preferencias del analista.
- in embargo, algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta
sirve para homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve más
para comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios
aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a inherente
al analista.
- in embargo, algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta
sirve para homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve más
para comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios
aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a inherente
al analista.
- 4.3 ¿Qué se hace cuando se desconoce la desviación
estándar poblacional?
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar
poblacional o se supone una partiendo de la experiencia propia. Por ejemplo, la
empresaria de chicago partió de lo que ha observado con su proveedor, en el sentido
de fijar la desviación estándar del peso de aguacates que ha recibido a lo largo de la
historia como de 1.1Oz. Sin embargo, no siempre se conoce este valor por lo que debe
calcularse para poder determinar los estadísticos Z o t.
- Este estadístico se utiliza para determinar los valores críticos de la prueba de hipótesis (IC) con las
fórmulas de las estimaciones de intervalo si se trabaja con la escala original o se emplea directaente
para definir el estadístico de prueba de la hipótesis. También sirve para determinar los estadísticos Z y
t si se utiliza una prueba con escala estandarizada.
- Este estadístico se utiliza para determinar los valores críticos de la prueba de hipótesis (IC) con las
fórmulas de las estimaciones de intervalo si se trabaja con la escala original o se emplea directaente
para definir el estadístico de prueba de la hipótesis. También sirve para determinar los estadísticos Z y
t si se utiliza una prueba con escala estandarizada.
- 4.4 Pruebas de hipótesis para comparar muestras.
- n este caso específico ya no se busca demostrar que los parámetros de una muestra se ajustan a los
de una población o a un valor hipotético dado por H 0 . Más bien se busca comparar su media,
buscando probar que estas sean iguales, mayor en la muestra A respecto a la B o viceversa.
- Para ilustrar el empleo de este tipo de prueba de hipótesis, tómese la idea original que tenían los dos
empresarios aguacateros de comparar la calidad de sus inventarios, con la finalidad de saber si el
proveedor, que es el mismo para ambos, les vende la misma calidad. Lo primero que hacen los
empresarios es homologar sus escalas de medida, por lo que deciden trabajar con onzas.
Posteriormente, deciden probar la calidad estableciendo como objetivo determinar que la calidad que
ambos reciben es la misma.
- Para poder establecer el ejercicio, recuerde usted el tema de estimaciones de intervalo de diferencias.
En concreto, que las muestras pueden ser independientes o relacionadas. Para este caso, dado que
ambos reciben aguacates del mismo proveedor y este puede determinar qué calidad mandar a cada
cliente, se supondrá que la muestra está relacionada, acoplada o apareada.
- Definir una hipótesis nula a
demostrar: La hipótesis a demostrar
sería: “El inventario de aguacates de
ambos comerciantes es igual”.
- Se determina la función de
probabilidad a utilizar: En este
caso, al ser muestra grande, se
emplea la gaussiana (normal
estándar) y, por ende, se emplea
un valor Z
- . Se define el grado de significancia: La muestra con que se trabaja es de 30
piezas. Por tanto, la empresaria decide utilizar un valor Z que corresponda a
un nivel de significancia de 5%. Al ser esta una prueba de dos colas, se debe
buscar un valor Z en tablas que corresponda a 97.5% de probabilidad Esto le
lleva a un valor Z de 1.9599.
- Se define si se trabaja con la escala original o con una
estandarizada: Se determina trabajar con escala
estandarizada
- se comparan los valores críticos fijados con el
estadístico (media muestral) y se determina si se
acepta la hipótesis nula (H0 ) o se abre paso a la
alternativa ( Ha )
- Definir una hipótesis nula a
demostrar: La hipótesis a demostrar
sería: “El inventario de aguacates de
ambos comerciantes es igual”.
- Para poder establecer el ejercicio, recuerde usted el tema de estimaciones de intervalo de diferencias.
En concreto, que las muestras pueden ser independientes o relacionadas. Para este caso, dado que
ambos reciben aguacates del mismo proveedor y este puede determinar qué calidad mandar a cada
cliente, se supondrá que la muestra está relacionada, acoplada o apareada.
- Para ilustrar el empleo de este tipo de prueba de hipótesis, tómese la idea original que tenían los dos
empresarios aguacateros de comparar la calidad de sus inventarios, con la finalidad de saber si el
proveedor, que es el mismo para ambos, les vende la misma calidad. Lo primero que hacen los
empresarios es homologar sus escalas de medida, por lo que deciden trabajar con onzas.
Posteriormente, deciden probar la calidad estableciendo como objetivo determinar que la calidad que
ambos reciben es la misma.
- 5 Prueba de hipótesis: Las técnicas Ji- cuadrada y ANOVA
- Hasta ahora se ha visto el caso en el que se realizan pruebas de hipótesis comprobando medias
muestrales respecto a una media poblacional o una media hipotética. A su vez, se hicieron
comparaciones de diferencias de medias muestrales entre dos poblaciones diferentes.
- Dentro de los supuestos que se han manejado es determinar que existe dependencia o independencia
en dichas poblaciones, por un lado y que están ya sea normalmente distribuidas (si se trata de una
población o muestra grande) o t-Student distribuidas si se trata de una muestra pequeña.
- En este tema específico utilizaremos un tipo de técnica de comprobación de hipótesis conocido como la
técnica Ji-Cuadrada, la cual nos servirá para realizar dos cosas:
- 1. Determinar si dos o más variables o atributos de
interés son independientes en base a los datos
obtenidos en la muestra.
- 2. Determinar si el comportamiento de los datos
con que se cuenta se explican o no con una
distribución de probabilidad determinada como
puede ser la normal, la t-Student u otro tipo de
casos como son la F, la binomial, la Weibull, la
Gumbel, la Poisson, la uniforme u otras.
- 3. Determinar si la varianza de una
muestra es igual, inferior o superior a
sierto valor hipotético, poblacional u
objetivo.
- Otro tipo de técnica de comprobación de hipótesis que se revisará será la prueba ANOVA (siglas en
idioma inglés de Análisis de varianza –Analysis Of VAriance-) en la cual no se comparan medias
directamente, como en la técnica clásica; sino que se contrastan las varianzas. Esta prueba permitirá, a
su vez, ya no comparar solo dos muestras de manera conjunta. Más bien, ayudará a realizar lo
siguiente:
- 1. Comparar 2 o más muestras o
poblaciones al mismo tiempo con la
finalidad de determinar si son o no iguales
sus medias.
- 2. Comparar 2 o más muestras o poblaciones al
mismo tiempo con la finalidad de determinar si son o
no iguales o diferentes sus varianzas.
- 1. Comparar 2 o más muestras o
poblaciones al mismo tiempo con la
finalidad de determinar si son o no iguales
sus medias.
- 1. Determinar si dos o más variables o atributos de
interés son independientes en base a los datos
obtenidos en la muestra.
- En este tema específico utilizaremos un tipo de técnica de comprobación de hipótesis conocido como la
técnica Ji-Cuadrada, la cual nos servirá para realizar dos cosas:
- Dentro de los supuestos que se han manejado es determinar que existe dependencia o independencia
en dichas poblaciones, por un lado y que están ya sea normalmente distribuidas (si se trata de una
población o muestra grande) o t-Student distribuidas si se trata de una muestra pequeña.
- 5.1 La técnica Ji-Cuadrada 5.1.1 Prueba de
hipótesis para demostrar independencia.
- Ahora se revisará el empleo de la técnica Ji-Cuadrada para determinar si los atributos de dos o más
variables en una muestra o población son independientes o no. Por ejemplo, Steve Jobs pudo hacer una
encuesta más amplia y detallada que la previamente vista en donde se asignaron calificaciones, y ahora
preguntar a diferentes individuos de los cuatro segmentos o estratospreviamente estudiados14 si
preferirían Mac dados algunos atributos de la misma como son rapidez de arranque, el tamaño de la
computadora y la compatibilidad con Windows. Después de preguntar esto, Jobs pudo sospechar que
los diferentes resultados de cada atributo se relacionan a las necesidades profesionales o personales de
cada individuo en cada estrato realizado. Es entonces que pudo plantearse el cuestionamiento de si
¿Realmente los atributos estudiados y el estrato al que pertenece el individuo muestreado tienen
relación cercana para determinar la preferencia de los individuos
- Tabla de contingencia: Tabla que contiene R renglones y C columnas. Cada renglón corresponde a un
nivel de una variable; cada columna, a un nivel de otra variable. Los datos del cuerpo de la tabla son las
frecuencias con que ocurre cada combinación de variables y los totales en cada extremo son la suma de
esas frecuencias por renglón o por columna.
- El enunciado de la hipótesis a plantear en este caso sería: “Las variables atributo de la computadora y
estrato profesional están relacionadas entre sí y, por tanto pueden influir en la preferencia del usuario
de la computadora.”
- El enunciado de la hipótesis a plantear en este caso sería: “Las variables atributo de la computadora y
estrato profesional están relacionadas entre sí y, por tanto pueden influir en la preferencia del usuario
de la computadora.”
- Tabla de contingencia: Tabla que contiene R renglones y C columnas. Cada renglón corresponde a un
nivel de una variable; cada columna, a un nivel de otra variable. Los datos del cuerpo de la tabla son las
frecuencias con que ocurre cada combinación de variables y los totales en cada extremo son la suma de
esas frecuencias por renglón o por columna.
- 5.1.2 Distribución de probabilidad ji-cuadrada.
- Recuerde usted que las distribuciones normal (gaussiana) y t-Student son simétricas e incluyen valores
de probabilidad tanto a la izquierda como a la derecha del cero. Estas distribuciones de probabilidad
son muy útiles para muchos fenómenos como los revisados. Sin embargo, cuando se trata con valores
que solo son positivos, será de mucho interés tener una distribución de probabilidad que nunca tenga
valores negativos en su distribución de probabilidad
- Ahora, hay casos en que el problema estudiado no nos permite darnos el lujo de tener valores
negativos en los intervalos. Para estos casos se utilizan otro tipo de funciones de probabilidad como es
el caso de la ji-cuadrada. De hecho esta es de las más socorridas para hacer estimaciones de intervalos
y pruebas de hipótesis para actividades como son las siguientes:
- Determinar el número de personas que entran a
un supermercado en una determinada hora
(estará de acuerdo que no se pueden hacer
estimaciones de intervalo que digan “entran -30
personas).
- Aplicaciones de administración de riesgos crediticios como
son, determinar el monto de pérdida potencial que un banco
puede tener por hacer préstamos de tarjeta de crédito o
definir ¿cuál es la probabilidad de que nuestra cartera de
clientes acreditados nos haga perder X cantidad de dinero por
incumplimiento de pago?
- Determinar si el número de conexiones a nuestra página
por medio internet de internet es igual a un número
objetivo.
- Determinar que la varianza de nuestros datos es igual, inferior
o superior a un valor objetivo (no existen varianzas negativas de
ahí la necesidad de determinar probabilidades únicamente de
valores positivos).
- Las que, de momento, nos interesan más:
- o Determinar si dos variables, dada la
frecuencia de la combinación de ambas
en una tabla de contingencia, son
dependientes o independientes.
- o Determinar si un conjunto de datos se
distribuye o explica con una función de
densidad de probabilidad determinada
(prueba de bondad de ajuste).
- o Determinar si la varianza de una población, inferida a
partir de una muestra de datos, se ajusta a un objetivo
preestablecido.
- o Determinar si dos variables, dada la
frecuencia de la combinación de ambas
en una tabla de contingencia, son
dependientes o independientes.
- En base al contraste de hipótesis realizado, se tienen elementos estadísticos suficientes para aceptar la
hipótesis nula de que la variable estrato profesional y la variable atributo de la computadora están
estrechamente relacionadas para determinar la preferencia del individuo por una Mac. Por lo tanto,
Steve Jobs aplicó una encuesta adecuada y enfocó una adecuada estrategia de desarrollo, producción y
marketing para vender una computadora que satisfaga las necesidades de diferentes personas y que
tuviera una mayor demanda.
- Determinar el número de personas que entran a
un supermercado en una determinada hora
(estará de acuerdo que no se pueden hacer
estimaciones de intervalo que digan “entran -30
personas).
- Ahora, hay casos en que el problema estudiado no nos permite darnos el lujo de tener valores
negativos en los intervalos. Para estos casos se utilizan otro tipo de funciones de probabilidad como es
el caso de la ji-cuadrada. De hecho esta es de las más socorridas para hacer estimaciones de intervalos
y pruebas de hipótesis para actividades como son las siguientes:
- 5.1.3 Algunas consideraciones a tomar con la prueba ji-cuadrada.
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan:
- 1. Nunca se deben trabajar con tablas de
contingencia que tengan frecuencias menores a 5.
Es decir, que el valor de una celda sea menor a 5. Si
en algún momento se presentara este caso en dos o
más celdas, podemos eliminar algunas categorías
(renglón o columna) y combinar los valores de la (s)
eliminada (s) con otra que esté en el mismo caso y
así lograr frecuencias mayores o iguales a 5. Sin
embargo, esto tiene la limitante de la pérdida de
una o varias categorías y el examen de
independencia entre variables quedaría muy parcial
- 2. Si, por alguna circunstancia, el valor ji-cuadrada
derivado con la fórmula 24 diera cero, debe
sospecharse del resultado ya que se puede estar en
presencia de un problema de una inapropiada
recolección de datos.
- 1. Nunca se deben trabajar con tablas de
contingencia que tengan frecuencias menores a 5.
Es decir, que el valor de una celda sea menor a 5. Si
en algún momento se presentara este caso en dos o
más celdas, podemos eliminar algunas categorías
(renglón o columna) y combinar los valores de la (s)
eliminada (s) con otra que esté en el mismo caso y
así lograr frecuencias mayores o iguales a 5. Sin
embargo, esto tiene la limitante de la pérdida de
una o varias categorías y el examen de
independencia entre variables quedaría muy parcial
- 5.1.4 Prueba de hipótesis ji cuadrada para bondad de ajuste (determinar la
función de probabilidad a emplear en un grupo de datos).
- hora se revisará uno de los usos más comunes que tiene la prueba con distribución ji-cuadrada:
Determinar si el comportamiento de un grupo de datos se explica con alguna función de densidad
determinada.
- Como ha visto hasta ahora, el análisis de prueba con técnica ji-cuadrada se enfoca a trabajar con
tablas de contingencias en donde se presentan las diferentes frecuencias observadas en las
diferentes combinaciones de variables. Sin embargo, cuando se tiene una serie de datos, no siempre
se puede hacer una tabla de frecuencias, salvo que sea el histograma, de los datos debido a que se
deben fijar clases o intervalos discrecionales. Existen algunas otras distribuciones de probabilidad
cómo la binomial, la Poisson u otras que se enfocan a eventos aleatorios discretos (Recuerde usted la
definición correspondiente) y en estas se puede hacer un análisis de bondad de ajuste con técnica
ji-cuadrada que no difiere mucho del anteriormente realizado.
- Si desea profundizar en el tema de prueba de bondad de ajuste de diferentes
distribuciones de probabilidad puede usted consultar el libro de Levin y Rubin (2004, págs.
462-465) el cual resulta una excelente introducción al tema. El mismo no se desarrolla en
las presentes notas debido a que la lógica de razonamiento podría salirse, de manera
observable, de la lógica de presuponer que los datos con que se trabaja, están normal o
t-Student distribuidosl.
- En estas notas nos limitaremos, con la finalidad de solo sensibilizarle al empleo de la distribución de
probabilidad ji-cuadrada, a determinar si los datos con que se trabaja están o no normalmente
distribuidos. Para ello, se utilizará el cálculo de un estadístico elaborado ampliamente utilizado en la
Econometría y el análisis estadístico y el cuál fue elaborado por un Mexicano (Carlos Jarque15) y Anil
Bera. El mismo se conoce como estadístico Jarque-Bera.
- Recuerde usted que una distribución de probabilidad normal debe ser simétrica, es decir, que se
tengan la misma cantidad y probabilidades en los valores tanto positivos como negativos. Por lo
tanto, si usted calcula las probabilidades de sus datos y la distribución de probabilidad tiene sesgo
positivo o negativo, se tiene un claro indicio de que los datos pueden no ser normalmente
distribuidos.
- Recuerde usted que una distribución de probabilidad normal debe ser simétrica, es decir, que se
tengan la misma cantidad y probabilidades en los valores tanto positivos como negativos. Por lo
tanto, si usted calcula las probabilidades de sus datos y la distribución de probabilidad tiene sesgo
positivo o negativo, se tiene un claro indicio de que los datos pueden no ser normalmente
distribuidos.
- En estas notas nos limitaremos, con la finalidad de solo sensibilizarle al empleo de la distribución de
probabilidad ji-cuadrada, a determinar si los datos con que se trabaja están o no normalmente
distribuidos. Para ello, se utilizará el cálculo de un estadístico elaborado ampliamente utilizado en la
Econometría y el análisis estadístico y el cuál fue elaborado por un Mexicano (Carlos Jarque15) y Anil
Bera. El mismo se conoce como estadístico Jarque-Bera.
- Si desea profundizar en el tema de prueba de bondad de ajuste de diferentes
distribuciones de probabilidad puede usted consultar el libro de Levin y Rubin (2004, págs.
462-465) el cual resulta una excelente introducción al tema. El mismo no se desarrolla en
las presentes notas debido a que la lógica de razonamiento podría salirse, de manera
observable, de la lógica de presuponer que los datos con que se trabaja, están normal o
t-Student distribuidosl.
- Como ha visto hasta ahora, el análisis de prueba con técnica ji-cuadrada se enfoca a trabajar con
tablas de contingencias en donde se presentan las diferentes frecuencias observadas en las
diferentes combinaciones de variables. Sin embargo, cuando se tiene una serie de datos, no siempre
se puede hacer una tabla de frecuencias, salvo que sea el histograma, de los datos debido a que se
deben fijar clases o intervalos discrecionales. Existen algunas otras distribuciones de probabilidad
cómo la binomial, la Poisson u otras que se enfocan a eventos aleatorios discretos (Recuerde usted la
definición correspondiente) y en estas se puede hacer un análisis de bondad de ajuste con técnica
ji-cuadrada que no difiere mucho del anteriormente realizado.
- 5.1.5 Prueba de hipótesis ji-cuadrada para hacer inferencias sobre la varianza de una sola
población (o muestra).
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de datos
o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado ( 2 H 0 ). La
lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica clásica.
Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un valor
ji-cuadrada tanto para el intervalo superior como el inferior (valores críticos), según el caso que aplique
(si es prueba de una o dos colas).
- Otra diferencia obvia y fundamental de la prueba ji-cuadrada es que no emplea una distribución normal
o t-Student para fijar los mencionados valores críticos
- Para exponer la forma de realizar pruebas de hipótesis relativas a varianzas en una población se tiene
de nuevo el ejemplo de la empresaria de Chicago. Anteriormente buscó demostrar que la calidad
promedio de un embarque que le mandaron era igual a 3.8 Oz con un nivel de significancia () de 5%. Sin
embargo se percató de que, a pesar de esto, la variabilidad del peso de cada aguacate dentro de la
muestra respecto a su media muestral es muy alta. Por tanto, ahora buscó refinar su análisis y decir “Ok
el inventario tiene una calidad promedio igual a la buscada. Sin embargo, tal vez, por ser un promedio,
no se aprecie bien que hay piezas demasiado pesadas y otras demasiado ligeras por lo que la calidad
buscada no es uniforme”. Esta falta de uniformidad es aproximada con la varianza de los pesos.
- Usted puede replicar la prueba de hipótesis previamente estudiada si desea demostrar que la varianza
de la muestra es igual, mayor o diferente de 2 H 0 . Lo único que deberá hacer es obtener de las tablas
ji-cuadrada los valores del valor crítico o límite ya sea superior e/o inferior, según corresponda el tipo de
prueba (recuerde igualdad y desigualdad son pruebas de dos colas, inferioridad de cola inferior y
viceversa con superioridad).
- Usted puede replicar la prueba de hipótesis previamente estudiada si desea demostrar que la varianza
de la muestra es igual, mayor o diferente de 2 H 0 . Lo único que deberá hacer es obtener de las tablas
ji-cuadrada los valores del valor crítico o límite ya sea superior e/o inferior, según corresponda el tipo de
prueba (recuerde igualdad y desigualdad son pruebas de dos colas, inferioridad de cola inferior y
viceversa con superioridad).
- Para exponer la forma de realizar pruebas de hipótesis relativas a varianzas en una población se tiene
de nuevo el ejemplo de la empresaria de Chicago. Anteriormente buscó demostrar que la calidad
promedio de un embarque que le mandaron era igual a 3.8 Oz con un nivel de significancia () de 5%. Sin
embargo se percató de que, a pesar de esto, la variabilidad del peso de cada aguacate dentro de la
muestra respecto a su media muestral es muy alta. Por tanto, ahora buscó refinar su análisis y decir “Ok
el inventario tiene una calidad promedio igual a la buscada. Sin embargo, tal vez, por ser un promedio,
no se aprecie bien que hay piezas demasiado pesadas y otras demasiado ligeras por lo que la calidad
buscada no es uniforme”. Esta falta de uniformidad es aproximada con la varianza de los pesos.
- Otra diferencia obvia y fundamental de la prueba ji-cuadrada es que no emplea una distribución normal
o t-Student para fijar los mencionados valores críticos
- 5.1.6 Haciendo estimaciones de intervalos de varianzas.
- sí como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para
determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede
replicar el ejercicio en el caso de las varianzas.
- 5.2 Prueba ANOVA.
- Ahora toca revisar el segundo subtema de interés del presente: la prueba ANOVA (siglas de ANalisis Of
VAriance). En temas previos se hicieron comparaciones de medias muestrales respecto a un objetivo
hipotético o de diferencias entre dos muestras solamente. Lo propio se hizo para revisar la varianza de una
sola muestra. Es decir, para determinar si esta era igual, superior o inferior a un objetivo determinado.
- A pesar, de esto queda una pregunta en pie ¿Se pueden comparar medias o varianzas de dos o más
poblaciones al mismo tiempo? Es decir, comparar la media de tres poblaciones o muestras al unísono o
contrastar la magnitud de la varianza de dos o más de ellas.
- La prueba ANOVA es una prueba muy poderosa y muy simple de interpretar. La misma nos servirá para
comparar no solo dos medias a la vez sino más de dos medias de muestras que pueden ser independientes o
estar acopladas, apareadas o relacionadas y que pueden venir de tamaños de muestras totalmente
diferentes. Por ejemplo, piense usted que necesita comparar siete muestras diferentes correspondientes a
siete inventarios de aguacate.
- Los métodos de la técnica clásica serían bastante limitados si desea hacer pruebas de hipótesis (ya sea de muestras
acopladas o independientes). Incluso el hacer esto sería laborioso ya que le implicaría hacer 21 pruebas de hipótesis
diferentes. Es decir una prueba de hipótesis de la muestra 1 con la muestra 2 y así sucesivamente.
- Para reducir todo este trabajo, la prueba ANOVA viene al rescate e incluso quizá sea la más adecuada
en muchas aplicaciones de su futura vida profesional.
- Para poder dar validez a la afirmación anterior, es de necesidad observar que se presupondrá que las
muestras están normalmente distribuidas, por lo que, si desea comprobar este supuesto, deberá
aplicar la prueba de normalidad con la técnica ji-cuadrada previamente descrita
- Si se observa con detenimiento la gráfica 34, se puede notar que la desigualdad en la varianza de las
tres muestras se puede atribuir a dos factores:
- La varianza existente entre las medias muestrales. Es decir, qué tan
separadas están unas de otras respecto a un promedio de medias o
gran media X .
- La varianza conjunta existente entre todos los datos de las muestras
- Para ilustrar mejor la idea, observe la gráfica superior izquierda. Usted verá que prácticamente no
existe variabilidad o varianza entre las medias muestrales (son casi iguales) y, si la varianzas son
iguales, la variabilidad total (graficada con una línea roja como “todas las muestras”) es prácticamente
la misma que la existente entre las medias muestrales. De cumplirse esta posición, se llega a
distribuciones de probabilidad con medias y varianzas prácticamente sobrepuestas unas sobre otras.
- Ahora vea usted la gráfica superior derecha. En la misma son notorias las diferencias entre muestras
ya que las medias muestrales se encuentran muy separadas. Esto lleva a una varianza entre medias
muestrales observable (vea la gráfica inferior derecha en donde se exponen los valores de dichas
medias y contraste su valor con el de la izquierda). Como consecuencia de esta situación, la varianza
total de todos los datos de las tres muestras del lado derecho (función de probabilidad graficada con
rojo) es mucho mayor que la de las tres muestras iguales expuestas a la izquierda. Es entonces que se
llega a la noción intuitiva general de la prueba ANOVA:
- Nociones intuitivas de la prueba ANOVA: “Dos o más muestras serán iguales si
la varianza de sus medias muestrales es igual que la varianza total de los
datos de las tres muestras en conjunto”
- Nociones intuitivas de la prueba ANOVA: “Dos o más muestras serán iguales si
la varianza de sus medias muestrales es igual que la varianza total de los
datos de las tres muestras en conjunto”
- Ahora vea usted la gráfica superior derecha. En la misma son notorias las diferencias entre muestras
ya que las medias muestrales se encuentran muy separadas. Esto lleva a una varianza entre medias
muestrales observable (vea la gráfica inferior derecha en donde se exponen los valores de dichas
medias y contraste su valor con el de la izquierda). Como consecuencia de esta situación, la varianza
total de todos los datos de las tres muestras del lado derecho (función de probabilidad graficada con
rojo) es mucho mayor que la de las tres muestras iguales expuestas a la izquierda. Es entonces que se
llega a la noción intuitiva general de la prueba ANOVA:
- La varianza existente entre las medias muestrales. Es decir, qué tan
separadas están unas de otras respecto a un promedio de medias o
gran media X .
- Si se observa con detenimiento la gráfica 34, se puede notar que la desigualdad en la varianza de las
tres muestras se puede atribuir a dos factores:
- Para poder dar validez a la afirmación anterior, es de necesidad observar que se presupondrá que las
muestras están normalmente distribuidas, por lo que, si desea comprobar este supuesto, deberá
aplicar la prueba de normalidad con la técnica ji-cuadrada previamente descrita
- Para reducir todo este trabajo, la prueba ANOVA viene al rescate e incluso quizá sea la más adecuada
en muchas aplicaciones de su futura vida profesional.
- Los métodos de la técnica clásica serían bastante limitados si desea hacer pruebas de hipótesis (ya sea de muestras
acopladas o independientes). Incluso el hacer esto sería laborioso ya que le implicaría hacer 21 pruebas de hipótesis
diferentes. Es decir una prueba de hipótesis de la muestra 1 con la muestra 2 y así sucesivamente.
- La prueba ANOVA es una prueba muy poderosa y muy simple de interpretar. La misma nos servirá para
comparar no solo dos medias a la vez sino más de dos medias de muestras que pueden ser independientes o
estar acopladas, apareadas o relacionadas y que pueden venir de tamaños de muestras totalmente
diferentes. Por ejemplo, piense usted que necesita comparar siete muestras diferentes correspondientes a
siete inventarios de aguacate.
- A pesar, de esto queda una pregunta en pie ¿Se pueden comparar medias o varianzas de dos o más
poblaciones al mismo tiempo? Es decir, comparar la media de tres poblaciones o muestras al unísono o
contrastar la magnitud de la varianza de dos o más de ellas.
- 5.2.1 La función de probabilidad F.
- ¿Recuerda usted la distribución Ji-cuadrada? ¿Recuerda que la utilizábamos para calcular la probabilidad de
eventos que solo pueden tener valores positivos como es el caso de los valores que puede adoptar la
varianza de una variable aleatoria? Pues hagamos el siguiente silogismo o razonamiento:
- 1. Si la distribución ji-cuadrada se utiliza para determinar las
probabilidades de una varianza.
- 2. Si por otro lado es estadístico F es
la división entre dos varianzas (la
varianza entre muestras y entre el
total de datos).
- La probabilidad anterior se logra de la tabla de probabilidades F como la presentada en la plataforma
Moodle en el tema de la prueba ANOVA. Para determinar la misma se deben especificar los grados de
libertad del numerados, que corresponden el número de muestras (k ) empleadas menos 1 grado de
libertad y el total de datos en las muestras en conjunto ( T n ) menos un grado de libertad (para mayor
referencia, consulte en la tabla el ejemplo que se da).
- 1. Si la distribución ji-cuadrada se utiliza para determinar las
probabilidades de una varianza.
- 5.2.2 La prueba F
- Ahora que se observa que se tienen los múltiples datos necesarios
como los grados de libertad del numerador y los del denominador se
puede calcular el estadístico F y determinar un valor crítico F
empleando las tablas correspondientes al emplear los grados de
libertad del numerador y del denominador. Para ello será de necesidad
utilizar las tablas de valores F como la que se presenta en la plataforma
Moodle en el tema correspondiente a la prueba ANOVA.
- Para ilustrar la prueba de hipótesis con la técnica ANOVA retomemos el ejemplo de los empresarios
aguacateros de Morelia y Chicago. Lo que ellos quieren plantear es que el inventario que ellos reciben
por parte de su proveedor (que es el mismo), tienen la misma calidad. Esto los lleva a plantear la
siguiente hipótesis:
- La calidad de los dos inventarios es la misma. Esto es, : La calidad de los dos inventarios es la misma.
Esto es, Morelia Chicago a Morelia Chicago H
- La calidad de los dos inventarios es la misma. Esto es, : La calidad de los dos inventarios es la misma.
Esto es, Morelia Chicago a Morelia Chicago H
- Para ilustrar la prueba de hipótesis con la técnica ANOVA retomemos el ejemplo de los empresarios
aguacateros de Morelia y Chicago. Lo que ellos quieren plantear es que el inventario que ellos reciben
por parte de su proveedor (que es el mismo), tienen la misma calidad. Esto los lleva a plantear la
siguiente hipótesis:
- 5.2.3 Prueba ANOVA para probar la igualdad en la varianza entre dos muestras. El caso de la cola superior.
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la
ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar que
la prueba ANOVA es muy poderosa para contrastar igualdad entre medias.
- Adicional a la aplicación anterior, la prueba ANOVA puede ser utilizada para comprobar la igualdad estadística
de la varianza entre dos muestras (solo dos y objetivo que no se logra con la técnica jicuadrada).
- parámetros poblacionales como la suposición de normalidad o algún tipo de función de probabilidad en los
datos aleatorios. Sin embargo, como se verá más adelante, existen otro tipo de pruebas a emplear cuando se
desconoce la distribución de probabilidad, las cuales se denominan pruebas no paramétricas.
- Baste con ahora seguir suponiendo que los datos se distribuyen de manera normal y que la Estadística con
que se trabaja es paramétrica.
- Baste con ahora seguir suponiendo que los datos se distribuyen de manera normal y que la Estadística con
que se trabaja es paramétrica.
- parámetros poblacionales como la suposición de normalidad o algún tipo de función de probabilidad en los
datos aleatorios. Sin embargo, como se verá más adelante, existen otro tipo de pruebas a emplear cuando se
desconoce la distribución de probabilidad, las cuales se denominan pruebas no paramétricas.
- Adicional a la aplicación anterior, la prueba ANOVA puede ser utilizada para comprobar la igualdad estadística
de la varianza entre dos muestras (solo dos y objetivo que no se logra con la técnica jicuadrada).
- 6 Estadística multivariada: Regresión lineal simple y multivariada.
- Conceptos de estadística multivariada. Hasta el momento se ha trabajado con el contraste de
muestras o poblaciones que tienen una distribución de probabilidad identidad y, en algunos casos,
que tienen un comportamiento dependiente una de la otra. En la vida cotidiana, existen pocos
fenómenos que no tienen algún tipo de relación estadística por lo que la probabilidad de suceso de
dos o más eventos conjuntos debe de determinarse.
- Un claro ejemplo en las ciencias económico-administrativas se puede encontrar en el comportamiento
de los rendimientos pagados por una acción que cotiza en bolsa. Suponga usted que tiene un histórico
de las variaciones porcentuales diarias del precio o rendimientos de dos acciones que cotizan en la
bolsa han tenido a lo largo de un año. Supongamos que se trata de las empresas América Móvil (AMX) y
Coca-Cola Femsa (KOF).
- Note usted cómo se tienen dos probabilidades llamadas “marginales” Estas no son más que las
distribuciones de probabilidad gaussianas de la variación porcentual del precio de AMX y de KOF
respectivamente. Es decir las probabilidades de que AMX varíe un X% o de que KOF lo haga en un Y%
independientemente del comportamiento de otras acciones. Sin embargo, la superficie en forma de
campana o “montaña” colorida que se tiene al centro cuantifica la probabilidad de que AMX vería un X%
dado o por la influencia de que KOF varía a su vez y al mismo tiempo un Y%.
- Para poder calcular una probabilidad conjunta entre dos o más variables aleatorias es necesario suponer
que ambas están relacionadas o acopladas. Es decir que no son independientes por lo que adicional a la
media y la varianza (o desviación estándar) que se utilizan para calcular las funciones de probabilidad, debe
entrar una nueva medida estadística de dispersión que cuantifique la variación conjunta e influenciada
entre las dos variables aleatorias que nos interesan. Esta medida se conoce como la covarianza. Así como se
definió a la varianza como el grado de separación promedio de las observaciones de una variable aleatoria
respecto a su media, la covarianza se puede definir como
- Covarianza: “Grado de separación promedio que tiene una
variable aleatoria respecto a su media dado el grado de
separación promedio que otra variable aleatoria tiene
también respecto a su media”.
- Ya que se tiene la covarianza ente la variable 1 y la 2, se calcula otra covarianza entre la variable 2 y la 1 y
que se calcularon las correspondientes varianzas de la variable 1 y la variable 2, se está en capacidad de
determinar el cálculo de una varianza total entre variables aleatorias destinando el mismo peso a cada
variable aleatoria. Es decir, si se tienen dos variables, el peso ( w ) será de w 1/ 2 0.5 . Si son 3, será de w
1/ 3 0.33333... y así sucesivamente.
- Covarianza: “Grado de separación promedio que tiene una
variable aleatoria respecto a su media dado el grado de
separación promedio que otra variable aleatoria tiene
también respecto a su media”.
- Para poder calcular una probabilidad conjunta entre dos o más variables aleatorias es necesario suponer
que ambas están relacionadas o acopladas. Es decir que no son independientes por lo que adicional a la
media y la varianza (o desviación estándar) que se utilizan para calcular las funciones de probabilidad, debe
entrar una nueva medida estadística de dispersión que cuantifique la variación conjunta e influenciada
entre las dos variables aleatorias que nos interesan. Esta medida se conoce como la covarianza. Así como se
definió a la varianza como el grado de separación promedio de las observaciones de una variable aleatoria
respecto a su media, la covarianza se puede definir como
- Un claro ejemplo en las ciencias económico-administrativas se puede encontrar en el comportamiento
de los rendimientos pagados por una acción que cotiza en bolsa. Suponga usted que tiene un histórico
de las variaciones porcentuales diarias del precio o rendimientos de dos acciones que cotizan en la
bolsa han tenido a lo largo de un año. Supongamos que se trata de las empresas América Móvil (AMX) y
Coca-Cola Femsa (KOF).
- 6.1 El coeficiente de correlación y su interacción con la covarianza.
- Si usted observa detenidamente la fórmula de cálculo de la covarianza pude
preguntarse ¿Y qué hace que dos variables aleatorias se muevan en conjunto?:
- Para ilustrar la idea usted piense en la luna y la tierra. La luna se mueve
alrededor de la tierra y no del sol dado que la gravedad o grado de
atracción entre ambas es mayor que el existente entre el sol y la luna.
Por eso la luna no ha dejado a la tierra para irse con el sol. En las
variables aleatorias sucede algo similar. Cuando estas son dependientes
debe existir un grado de correlación o gravedad entre ellas para que
puedan covariar. De lo contrario no existirá la covarianza y no existirá
dependencia entre ellas.
- Vea usted el coeficiente de correlación como el “pegamento” entre
variables. Con este pegamento o nivel de gravedad usted puede calcular la
covarianza como sigue:
- En la expresión anterior, el coeficiente de correlación
de Pearson o simplemente coeficiente de correlación
x y, (En donde x y y x , , ) es esa gravedad o
pegamento del que se habla. Note usted cómo se
tiene, de inicio, esa variabilidad individual de cada
caso (x y y ) y se relaciona con ese pegamento. Por
tanto, la variable de interés es el coeficiente de
correlación x y, . El coeficiente puede tener valores
de -1 a 1. Es decir, un valor de , 1 x y implicaría
que con cada 1% que suba AMX, KOF baje 1% y
viceversa. Cuando , 1 x y el precio de AMX sube 1%
cuando KOF hace lo propio y viceversa. Al
incorporarse la variabilidad individual en cada caso
(x y y ) se llega a la covarianza que se presentó en
la fórmula 39:
- Vea usted el coeficiente de correlación como el “pegamento” entre
variables. Con este pegamento o nivel de gravedad usted puede calcular la
covarianza como sigue:
- 6.2 El modelo regresión lineal simple para establecer relaciones
estadísticas entre variables y hacer pronósticos básicos.
- En este punto estamos entrando a una de las aplicaciones más importantes (sino la más importante) de la
Estadística inferencial: la regresión. Con esta se logrará establecer la relación estadística entre variables de la
forma:
- Esto quiere decir que la variable y se determina por una ecuación matemática en donde a una constante (que
puede ser de cero o de otro valor positivo o negativo) se le suma un valor de x multiplicado por un número o
constante (que puede ser de cero o de otro valor positivo o negativo). Si usted observa detenidamente el
modelo de regresión, podrá apreciar que será capaz de hacer estimaciones del tipo “por cada valor de x se
tendrá un valor de y dado por x “. Es decir ya podrá decir cuánto valdrá y dado el de x . La clave aquí
estará en calcular los coeficientes y . Esto es lo que determinaremos a continuación y a lo que le daremos
una explicación gráfica.
- 6.2.1 Determinación de los coeficientes del modelo de regresión.
- Para determinar los coeficientes de regresión, siendo esta el modelo
resultante de la interacción entre las dos variables, se ocupa la
covarianza que es la que cuantifica el grado de variación promedio
conjunta entre variables, la varianza de la variable regresora ( x ) 16,
y la media muestral de la regresada (Y ):
- Para determinar los coeficientes de regresión, siendo esta el modelo
resultante de la interacción entre las dos variables, se ocupa la
covarianza que es la que cuantifica el grado de variación promedio
conjunta entre variables, la varianza de la variable regresora ( x ) 16,
y la media muestral de la regresada (Y ):
- En este punto estamos entrando a una de las aplicaciones más importantes (sino la más importante) de la
Estadística inferencial: la regresión. Con esta se logrará establecer la relación estadística entre variables de la
forma:
- Si usted observa detenidamente la fórmula de cálculo de la covarianza pude
preguntarse ¿Y qué hace que dos variables aleatorias se muevan en conjunto?:
- Conceptos de estadística multivariada. Hasta el momento se ha trabajado con el contraste de
muestras o poblaciones que tienen una distribución de probabilidad identidad y, en algunos casos,
que tienen un comportamiento dependiente una de la otra. En la vida cotidiana, existen pocos
fenómenos que no tienen algún tipo de relación estadística por lo que la probabilidad de suceso de
dos o más eventos conjuntos debe de determinarse.
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la
ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar que
la prueba ANOVA es muy poderosa para contrastar igualdad entre medias.
- Ahora que se observa que se tienen los múltiples datos necesarios
como los grados de libertad del numerador y los del denominador se
puede calcular el estadístico F y determinar un valor crítico F
empleando las tablas correspondientes al emplear los grados de
libertad del numerador y del denominador. Para ello será de necesidad
utilizar las tablas de valores F como la que se presenta en la plataforma
Moodle en el tema correspondiente a la prueba ANOVA.
- ¿Recuerda usted la distribución Ji-cuadrada? ¿Recuerda que la utilizábamos para calcular la probabilidad de
eventos que solo pueden tener valores positivos como es el caso de los valores que puede adoptar la
varianza de una variable aleatoria? Pues hagamos el siguiente silogismo o razonamiento:
- Ahora toca revisar el segundo subtema de interés del presente: la prueba ANOVA (siglas de ANalisis Of
VAriance). En temas previos se hicieron comparaciones de medias muestrales respecto a un objetivo
hipotético o de diferencias entre dos muestras solamente. Lo propio se hizo para revisar la varianza de una
sola muestra. Es decir, para determinar si esta era igual, superior o inferior a un objetivo determinado.
- sí como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para
determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede
replicar el ejercicio en el caso de las varianzas.
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de datos
o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado ( 2 H 0 ). La
lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica clásica.
Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un valor
ji-cuadrada tanto para el intervalo superior como el inferior (valores críticos), según el caso que aplique
(si es prueba de una o dos colas).
- hora se revisará uno de los usos más comunes que tiene la prueba con distribución ji-cuadrada:
Determinar si el comportamiento de un grupo de datos se explica con alguna función de densidad
determinada.
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan:
- Recuerde usted que las distribuciones normal (gaussiana) y t-Student son simétricas e incluyen valores
de probabilidad tanto a la izquierda como a la derecha del cero. Estas distribuciones de probabilidad
son muy útiles para muchos fenómenos como los revisados. Sin embargo, cuando se trata con valores
que solo son positivos, será de mucho interés tener una distribución de probabilidad que nunca tenga
valores negativos en su distribución de probabilidad
- Ahora se revisará el empleo de la técnica Ji-Cuadrada para determinar si los atributos de dos o más
variables en una muestra o población son independientes o no. Por ejemplo, Steve Jobs pudo hacer una
encuesta más amplia y detallada que la previamente vista en donde se asignaron calificaciones, y ahora
preguntar a diferentes individuos de los cuatro segmentos o estratospreviamente estudiados14 si
preferirían Mac dados algunos atributos de la misma como son rapidez de arranque, el tamaño de la
computadora y la compatibilidad con Windows. Después de preguntar esto, Jobs pudo sospechar que
los diferentes resultados de cada atributo se relacionan a las necesidades profesionales o personales de
cada individuo en cada estrato realizado. Es entonces que pudo plantearse el cuestionamiento de si
¿Realmente los atributos estudiados y el estrato al que pertenece el individuo muestreado tienen
relación cercana para determinar la preferencia de los individuos
- Hasta ahora se ha visto el caso en el que se realizan pruebas de hipótesis comprobando medias
muestrales respecto a una media poblacional o una media hipotética. A su vez, se hicieron
comparaciones de diferencias de medias muestrales entre dos poblaciones diferentes.
- n este caso específico ya no se busca demostrar que los parámetros de una muestra se ajustan a los
de una población o a un valor hipotético dado por H 0 . Más bien se busca comparar su media,
buscando probar que estas sean iguales, mayor en la muestra A respecto a la B o viceversa.
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar
poblacional o se supone una partiendo de la experiencia propia. Por ejemplo, la
empresaria de chicago partió de lo que ha observado con su proveedor, en el sentido
de fijar la desviación estándar del peso de aguacates que ha recibido a lo largo de la
historia como de 1.1Oz. Sin embargo, no siempre se conoce este valor por lo que debe
calcularse para poder determinar los estadísticos Z o t.
- Hasta el momento se ha observado que una de las variantes que puede tener la comprobación de
hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada,
lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra. Sin embargo, poco se ha
dicho sobre el criterio para utilizar una escala u otra. En realidad, no existen reglas generales para
decidir. Más bien la selección se da en función del tipo de problema y las preferencias del analista.
- Note usted cómo se empleó, para las pruebas anteriores, la escala original y el valor Z ya sea para
realizar las estimaciones de intervalo o para definir el estadístico de prueba en una escala
estandarizada. Sin embargo ¿Qué hubiera sucedido si la empresaria hubiera tomado sólo 15 aguacates
en lugar de 30 y hubiese decidido emplear la escala original (onzas)? En este punto, la muestra sería
pequeña y la media muestralsería ahora de X 5.1318:
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una
escala estandarizada. Es decir, se aplicará la fórmula del cálculo del valor Z dada
en la fórmula 9 a la media muestral a contrastar, considerando que es muestra
grande.
- De entrada, la comerciante de Chicago tiene el siguiente inventario, al cual
se le establecen la media hipotética de 3.8 . Ho Oz y una desviación
estándar poblacional, determinada con la experiencia previa de la
empresaria, de 1.1 .
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media objetivo
o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la comerciante de
Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar mejor el empleo de la
prueba de hipótesis en diferentes circunstancias.
- Para exponer el concepto de la prueba de hipótesis se
deben recordar tanto la forma de hacer estimaciones
como el cálculo de probabilidades empleando valores
Z o valores t. Para iniciar con la exposición de la idea
recordemos al ejemplo de los comerciantes de
aguacate. En concreto, centremos la atención de la
empresaria de Chicago. Suponga usted que ella busca
definir que la calidad de su inventario (recordemos
que este concepto está medido a través del peso de
cada fruta) debe ser mayor a 3.8 onzas (Oz.) para decir
que tiene buena calidad. Suponga que la empresaria
toma una muestra de 30 aguacates de su inventario
total de 5,000 y la experiencia de inventarios previos le
dice que la desviación estándar en el peso de los
aguacates es de 1.1 Oz. Es decir, aquí no se tiene
medida la desviación estándar de una población pero
se supone que ésta desviación estándar, que se logra
con la experiencia de inventarios previos, es una
aproximación adecuada13 .
- Hasta ahora se ha visto una de las aplicaciones de la Estadística inferencial que es la estimación de
valores futuros dados los datos muestrales con que se cuenta. Ahora se revisará una de las técnicas
más útiles y necesarias de la misma, la cual no será excepción en aplicaicones de su empresa y futuras
materias de su carrera como pueden ser Producción, Administración de la calidad o Finanzas. Esta
técnica de la que se habla es: la prueba de hipótesis.
- Ya para finalizar el tema de la Teoría del muestreo es necesario completar
un poco más una pregunta que se planteó previamente ¿Qué tan grande
debe ser la muestra para tener un estudio estadístico adecuado? Esta
pregunta se respondió en una primera instancia con el Teorema del límite
central que sugiere que la muestra sea mayor o igual a 30 observaciones
para poder suponer que los datos se distribuyen normalmente. Sin
embargo, el mismo se aplica cuando la población de datos del fenómeno
en estudio es muy grande y, por ende, se desconoce el verdadero valor de
la desviación estándar poblacional (σ).
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el
nivel de confianza que se imprimirá a las estimaciones de intervalo.
Sin embargo, estas salen de la óptica y grado de exigencia del curso ya
que en el mismo se le enseñará a dominar las principales técnicas
estadísticas de utilidad para su vida profesional. Si usted desea
profundizar en esto, puede cursar una maestría en administración o
una en finanzas que logre ese grado de profundización o puede
consultar fuentes más avanzadas en Econometría o análisis de datos
multivariante.
- Para poder calcular las estimaciones de intervalo de diferencias de muestras independientes, lo único
que debe cambiar es la forma de calcular estándar de las mismas
- Como se vio previamente para trabajar con estimaciones de
muestra pequeñas, las fórmulas de cálculo del límite superior e
inferior de la estimación de intervalo siguen siendo los
mismos.
- Recuerde usted que, por el Teorema del Límite central, se puede considera una muestra como “grande” si tiene
más de 30 observaciones e incluso se puede suponer que está distribuida si el tamaño de dicha muestra es
menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se tienen 4 grupos
de 20 individuos que dan un total de 80 diferencias o diferencias de calificaciones entr aceptar el supuesto de
que es muestra grande y de que está normalmente distribuida.
- Se ha visto previamente que la distribución normal, a
parte del valor de la variable aleatoria i x , necesita solo
dos simples parámetros o estadísticas12 que son la
media y la desviación estándar. Para el caso de la
distribución t-Student se siguen utilizando estos dos más
uno llamado Grados de libertad (denotado como GL o ).
- Hasta ahora se ha trabajado con el supuesto de que los datos
(sean de población o de muestra) están normalmente distribuidos
ya sea porque así nos conviene o porque hemos trabajado con
muestras con más de 30 datos, situación que satisface el Teorema
del Límite Central previamente revisado.
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que
reconoce que este valor puede cambiar de muestra en muestra y que
tiene el cálculo del error estándar de la muestra calculado con la fórmula
11, procederá usted a hacer una afirmación de este tipo: “El precio de la
acción se estima que sea de $26.4666 y, con un 95% de confianza, se
espera que ese valor oscile entre $26.6533 y $28.2802.” Si usted observa la
gráfica 26, quizá no le sea muy preciso el pronóstico en el sentido de que
el precio esperado y su intervalo están muy abajo. Con el análisis de
regresión podremos mejorar la precisión. Baste con suponer, de
momento, que la media muestral es buen pronóstico del valor futuro.
- Sin embargo, algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la
desviación estándar de la población y en realidad lo que se está calculando la de una muestra.
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se exponen
las 30 muestras aleatorias en comparación a la media poblacional.
- En el tema anterior se introdujo el concepto de que la media muestral puede ser diferente respecto a la
poblacional e incluso entre muestras. Eso llevó a observar como momentáneamente válida la aproximación
de dicha media poblacional a través de la media de la muestra con que se trabaja x . Sin embargo, sigue
presente el efecto de la incertidumbre que se genera al ver fluctuar x . Aquí es donde las estimaciones
puntuales y de intervalo cobran vida como conceptos
- Para finalizar la revisión de la Teoría del muestreo que
contempla este segundo tema del curso de Estadística
II. Es de interés observar algo más del cálculo del
error estándar
- Hasta ahora se ha trabajado con el supuesto de que
las variables aleatorias que se estudian están
normalmente distribuidas. Sin embargo puede darse
el caso de que esto no sea así. Cuando usted, con
técnicas de las que se revisarán algunas en temas
posteriores, detecta que los datos con que trabaja
no están normalmente distribuidos, puede seguir
manejando el supuesto de normalidad si incrementa
el número de datos de su muestra.
- Para calcular la probabilidad en una muestra
se sigue utilizando la misma tabla de
distribución normal estándar y se siguen los
mismos métodos de cálculo previamente
vistos. Lo único que cambia es la fórmula 6 a
la que se le sustituye la desviación estándar
por el error estándar
- En el sub tema anterior se dijo que el tamaño de la muestra no influía en el
cálculo de la media muestral y que sería la misma media para población
que para muestra. Sin embargo, en el caso de la desviación estándar
aplicable a una muestra, mejor conocida como error estándar, la cosa
cambia.
- Como puede apreciar, la función de probabilidad normal estándar sigue
utilizándose. Lo único que cambian son la forma de calcular la media y la
desviación estándar.
- Hasta ahora se ha revisado cómo se genera una función de
probabilidad normal estándar y se ha hecho énfasis en
observar que esta se revisó suponiendo que los datos con
que se trabaja son poblaciones. Sin embargo, usted tendrá
en su poder para trabajar, y salvo que el problema que usted
resuelva sea diferente, muestras.
- Hasta ahora, se ha trabajado con el supuesto de que los
datos que se han estudiado pertenecen a una población.
Es decir, se ha supuesto que los datos con que se trabaja
es la totalidad que se pueden tener. Sin embargo, al
introducirnos en este nuevo tema de Teoría del
muestreo, hemos visto que, en la mayoría de las
ocasiones, es difícil obtener y manipular todos los datos
de una población.
- En Estadística aplicada a los negocios, es importante conducir de
manera apropiada la toma de decisiones. Si usted a esta altura ya llevó
una clase de Métodos de investigación o metodología de la
investigación, recordará el método científico. Aunque éste último es
más apropiado para la generación de conocimiento científico, la forma
en cómo se llega a una conclusión y a la toma de decisiones en los
negocios es muy similar.
- De los 4 tipos de muestro vistos, el que se utilizará en Estadística inferencial es el aleatorio simple. La afirmación
anterior surge del hecho de que los otros tres tipos no son más que técnicas específicas de recolección de datos
que derivan en una muestra a la que se calcularán probabilidades muestrales y con los cuales usted, como
profesionista tomador de decisiones, deberá realizar el análisis estadístico que requiera. En pocas palabras, los
diferentes métodos de muestreo se aproximan al muestreo aleatorio.
- De los 4 tipos de muestro vistos, el que se utilizará en Estadística inferencial es el aleatorio simple. La afirmación
anterior surge del hecho de que los otros tres tipos no son más que técnicas específicas de recolección de datos
que derivan en una muestra a la que se calcularán probabilidades muestrales y con los cuales usted, como
profesionista tomador de decisiones, deberá realizar el análisis estadístico que requiera. En pocas palabras, los
diferentes métodos de muestreo se aproximan al muestreo aleatorio.
- 2.7 Diseño de un experimento: el proceso que se sigue
para tomar decisiones.
- Esta forma de muestrear se parece a la
anterior, con la diferencia de que
primero se hacen estratos y luego se
seleccionan miembros, datos u
observaciones de cada uno de los
estratos de una manera aleatoria. Por
ejemplo, usted desea saber cuántas
televisiones existen en la ciudad de
Morelia. Entonces, usted divide la
ciudad en colonias y elige, de cada
colonia y de manera aleatoria, una serie
de casas, toca la puerta y pregunta el
número de televisiones que hay en cada
una. Con esto toma muestras aleatorias
no de la totalidad de la población sino
de cada uno de los grupos que usted
formó.
- En este tipo de muestreo, se divide la población de datos en grupos
homogéneos (mujeres y hombres, intervalo de pesos, etc.) y se determina qué
proporción representa cada estrato o grupo. Cuando se analizan las
características y parámetros como media, desviación estándar, etc., se
ponderan los mismos en función de su representación o proporción de peso
respecto la población total y con esa ponderación se obtienen los parámetros y
probabilidades totales de dicha población con este tipo de muestra.
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos
predeterminados. Por ejemplo, piense usted que tiene 2,000 cajas de aguacate
foliadas todas y listas para empacarse a Estados Unidos. Ahora elige primero la caja
número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una
muestra de 100 cajas a las que le puede realizar el estudio estadístico que necesita.
- Como su nombre lo indica, consiste en seleccionar, de manera aleatoria, una
serie de observaciones, objetos o datos de una población sin seguir algún tipo de
agrupamiento específico
- En este tema simplemente se explorarán las características
relacionadas a la forma de hacer muestras. En el siguiente tema: la
inferencia, se observará que el cálculo de parámetros como la media
y la desviación estándar cambian en una muestra respecto a una
población.
- De entrada, es de necesidad observar que en todo lo
revisado hasta ahora se ha supuesto que el conjunto
de datos con que se trabaja son muestras. Sin
embargo, en la realidad es difícil trabajar con
poblaciones enteras sino, más bien, con muestras.
Para ilustrar esto, se recuerda la definición de
población:
- 1.1 ¿Para qué estudiamos esto?, ¿Cómo se come?, ¿Es un desperdicio de
mi tiempo el estudiar Estadística si soy contador, administrador o
informático?
- Un primer impulso que todos los alumnos tienen es creer que, por el hecho de estudiar para contadores,
administradores o informáticos, la Estadística sirve solo para rellenar la currícula que se ofrece en la universidad y
que nunca la utilizarán en su vida futura. Esto es realmente tanto falso como trágico ya que, como futuros
profesionistas independientes, investigadores, dueños de empresas o cabezas de gobierno (por citar casos de dónde
se ejercerá su maravillosa profesión y en donde se necesita de esta materia) deberán tomar decisiones.
- En otros casos usted se deberá saber si lo que se está haciendo es o será realmente apropiado, por lo que es de
necesidad conocer si lo que se planea realizar; como puede ser un negocio, la apertura de una empresa o línea de
producto, la realización de una inversión, la implementación de un sistema informático o el diseño de una campaña
política o social, le será necesario e incluso rentable tener información debidamente procesada para planear,
decidir, ejecutar y controlar de manera exitosa
- En este punto es donde la Estadística cobra importancia. Para dar una idea de esta relevancia, piense usted en la
empresa Apple Inc. Cuando el señor Jobs retomó las riendas Macintosh (así se llamaba antes), esta era una empresa
que vendía computadoras y tenía una tecnología más avanzada que las propias PC’s que trabajaban con Windows.
Sin embargo, era una empresa que vendía poco en relación a sus competidores y tenía pérdidas financieras, debido
a que los directivos anteriores veían a su empresa como proveedora de equipos de cómputo avanzado para
- Sin embargo, Steve Jobs apostó a otro segmento de mercado que poco había sido explotado o de interés para ellos:
El del ciudadano promedio (estudiante, ama de casa, joven, anciano, fotógrafo etc.). La facilidad de uso de la PC en
comparación a una Macintosh era algo que necesitaban sortear. La primera propuesta que Jobs hizo fue cambiar el
microprocesador propio de Mac por los producidos por la empresa Intel. Esto de tal forma que Apple Inc. redujera
costos de producción y lograra que los nuevos usuarios de Mac pudieran utilizar Windows y sus aplicaciones que
solo funcionaban en dicho sistema operativo, ya que detectaron que pocos programas o aplicaciones de la vida
cotidiana corrían o se diseñaban para Mac.
- Sin embargo, Steve Jobs apostó a otro segmento de mercado que poco había sido explotado o de interés para ellos:
El del ciudadano promedio (estudiante, ama de casa, joven, anciano, fotógrafo etc.). La facilidad de uso de la PC en
comparación a una Macintosh era algo que necesitaban sortear. La primera propuesta que Jobs hizo fue cambiar el
microprocesador propio de Mac por los producidos por la empresa Intel. Esto de tal forma que Apple Inc. redujera
costos de producción y lograra que los nuevos usuarios de Mac pudieran utilizar Windows y sus aplicaciones que
solo funcionaban en dicho sistema operativo, ya que detectaron que pocos programas o aplicaciones de la vida
cotidiana corrían o se diseñaban para Mac.
- En este punto es donde la Estadística cobra importancia. Para dar una idea de esta relevancia, piense usted en la
empresa Apple Inc. Cuando el señor Jobs retomó las riendas Macintosh (así se llamaba antes), esta era una empresa
que vendía computadoras y tenía una tecnología más avanzada que las propias PC’s que trabajaban con Windows.
Sin embargo, era una empresa que vendía poco en relación a sus competidores y tenía pérdidas financieras, debido
a que los directivos anteriores veían a su empresa como proveedora de equipos de cómputo avanzado para
- En otros casos usted se deberá saber si lo que se está haciendo es o será realmente apropiado, por lo que es de
necesidad conocer si lo que se planea realizar; como puede ser un negocio, la apertura de una empresa o línea de
producto, la realización de una inversión, la implementación de un sistema informático o el diseño de una campaña
política o social, le será necesario e incluso rentable tener información debidamente procesada para planear,
decidir, ejecutar y controlar de manera exitosa
- 1.2 Repaso de conceptos y definiciones de Estadística I
- De entrada hay que recordar que la Estadística es una rama de la Matemática consistente en “El conjunto de
técnicas de recolección, presentación y correcto análisis de información numérica relacionada con facilitar la toma
decisiones frente a situaciones de riesgo (falta de certeza)”. Aquí usted podrá identificar un elemento y
circunstancia de la vida real: Los individuos, en lo cotidiano, estamos sujetos a tomar decisiones con falta de
certeza. Y aquí es donde hacemos un primer paréntesis.
- Estadística: El conjunto de técnicas de recolección,
presentación y correcto análisis de información
numérica relacionada con facilitar la toma decisiones
frente a situaciones de riesgo (falta de certeza).
- En la vida en general, según lo sugiere la teoría matemática de la decisión, se conciben cuatro escenarios en los que
tomamos decisiones los individuos:
- 1. Escenario de certeza: En este escenario el individuo sabe con seguridad las consecuencias de la decisión
que tome. 2. Escenario de riesgo: En este escenario el individuo carece de certeza alguna y puede cuantificar
o determinar los diferentes resultados futuros de su decisión. 3. Escenario de incertidumbre: Aquí el
individuo carece también de certeza pero sabe que la Estadística no le será de utilidad, por tanto, no puede
cuantificar los diferentes resultados futuros de su decisión. 4. Escenario de conflicto: En el mismo se pueden
o no conocer los resultados futuros. Sin embargo, estos no dependen de cuestiones estadísticas sino de los
gustos e intenciones de otros individuos que no se pueden saber a ciencia cierta
- En relación al escenario de certeza se puede decir que, en nuestro
universo y vida en general, este escenario es prácticamente teórico
(por no decir que inexistente). Sin embargo, en algunos casos, podría
decirse que casi existe la “certeza” de lo que suceda cuando
decidamos. Por ejemplo, podemos saber que en Morelia es de noche a
las 11:00 PM. Aunque esto puede ser diferente en ciudades como Oslo
donde en el verano se tiene un sol de las 11:00 de la mañana cuando
son las 11:00 PM, en el contexto de un moreliano, la afirmación
anterior es casi cierta.
- Escenario de certeza: Escenario en el que
el individuo sabe con seguridad las
consecuencias de la decisión que tome.
- Escenario de riesgo: Escenario en el que el individuo
carece de certeza alguna y puede cuantificar o
determinar los diferentes resultados futuros de su
decisión con la Estadística
- Escenario de incertidumbre: Escenario en el que el individuo sabe que la Estadística
no le será de utilidad ya que no puede cuantificar los diferentes resultados futuros
de su decisión.
- Escenario de conflicto: Escenario en el que el individuo puede o no conocer los resultados
futuros. Sin embargo, estos no dependen de cuestiones estadísticas; sino de los gustos e
intenciones de otros individuos que no se pueden saber a ciencia cierta.
- Por tanto y para fines de la materia, todas las decisiones que deba usted efectuar en su negocio, las
realizará en un contexto de riesgo.
- Escenario de certeza: Escenario en el que
el individuo sabe con seguridad las
consecuencias de la decisión que tome.
- 1. Escenario de certeza: En este escenario el individuo sabe con seguridad las consecuencias de la decisión
que tome. 2. Escenario de riesgo: En este escenario el individuo carece de certeza alguna y puede cuantificar
o determinar los diferentes resultados futuros de su decisión. 3. Escenario de incertidumbre: Aquí el
individuo carece también de certeza pero sabe que la Estadística no le será de utilidad, por tanto, no puede
cuantificar los diferentes resultados futuros de su decisión. 4. Escenario de conflicto: En el mismo se pueden
o no conocer los resultados futuros. Sin embargo, estos no dependen de cuestiones estadísticas sino de los
gustos e intenciones de otros individuos que no se pueden saber a ciencia cierta
- Estadística: El conjunto de técnicas de recolección,
presentación y correcto análisis de información
numérica relacionada con facilitar la toma decisiones
frente a situaciones de riesgo (falta de certeza).
- 1.2.1 La probabilidad ¿Qué es y cómo se cuantifica?
- Ya que se estableció el tipo de escenario en donde usted tomará decisiones, es de necesidad recordar un
elemento de importancia: La probabilidad. Esta se define como “Una medida numérica que cuantifica
numéricamente la posibilidad de que un resultado o evento se presente”
- En un español más simple, la probabilidad es un número que indica a quien lo utiliza qué posibilidad se tiene de
que algo suceda. El ejemplo más común se escucha en los noticieros: “El día de hoy se tendrán nublados con una
probabilidad de precipitación pluvial de 80%”. Esto indica que el día de hoy es muy posible que llueva.
- Probabilidad: “Una medida numérica que cuantifica
numéricamente la posibilidad de que un resultado
o evento se presente”.
- En virtud de la definición de probabilidad dada, es de interés observar la definición de lo que se conoce como
“evento”. Como se estableció previamente, la probabilidad es el número que determina qué tan posible es que se
de ese evento. Por tanto el mismo se define como:
- Evento: “El futuro acontecimiento que
resultará de cualquier acción tomada en el
presente”.
- Sin embargo, dado que la moneda lanzada y, en específico, el resultado que se logre, es algo sujeto al azar, se
tiene que este evento es un “evento aleatorio” y el hecho de lanzar una moneda se conoce como “Experimento
aleatorio”
- Todos los eventos que se estudien en esta materia se considerarán “eventos aleatorios” y las decisiones que deba
tomar, desde un punto de vista Estadístico, se considerarán como un “Experimento aleatorio”. En este
experimento aleatorio, todos los posibles eventos aleatorios que puedan existir en el mismo forman un conjunto
llamado “Espacio muestral”. En el caso de la moneda que estudiamos previamente, el experimento aleatorio es
jugar al “volado”, el espacio muestral es un conjunto de solo dos eventos aleatorios: tener cara o tener sol.
- Evento aleatorio: “Son los resultados o acontecimientos cuyo valor, dada una
decisión previa, están sujetos al azar”.
- Experimento aleatorio: “Es una actividad sujeta a las leyes de la probabilidad en la
que se puede obtener uno solo de los eventos aleatorios que conforman el
espacio muestral”.
- Espacio muestral: “Es el conjunto de posibles eventos aleatorios
(resultados) que pueden tenerse en un experimento aleatorio”
- Algo que es importante saber ahora que se definió lo que es un evento aleatorio, un experimento aleatorio y la
probabilidad, es que existen dos tipos de probabilidades:
- Probabilidad subjetiva: Es una medida
numérica que expresa un grado personal
o teórico de que un evento suceda.
- Por ejemplo usted puede creer que una señora embarazada tiene 50% de probabilidades de dar a luz una niña o
50% de lograr un niño.
- Probabilidad objetiva: Es una medida numérica que
cuantifica la posibilidad de que un evento aleatorio suceda
en relación al total de eventos de un espacio muestral.
- La diferencia radica en que la subjetiva se basa en cuestiones teóricas, como es la creencia de la probabilidad de
que un recién nacido nazca mujer u hombre. La objetiva se basa en definir, a la luz de posibles resultados
previamente definidos y con daros observados, la posibilidad de que un evento aleatorio se presente dado el
número de veces que puede suceder en relación al número de veces que este y el número del resto de resultados
puede acontecer (como en la fórmula 1).
- La diferencia radica en que la subjetiva se basa en cuestiones teóricas, como es la creencia de la probabilidad de
que un recién nacido nazca mujer u hombre. La objetiva se basa en definir, a la luz de posibles resultados
previamente definidos y con daros observados, la posibilidad de que un evento aleatorio se presente dado el
número de veces que puede suceder en relación al número de veces que este y el número del resto de resultados
puede acontecer (como en la fórmula 1).
- Probabilidad objetiva: Es una medida numérica que
cuantifica la posibilidad de que un evento aleatorio suceda
en relación al total de eventos de un espacio muestral.
- Probabilidad subjetiva: Es una medida
numérica que expresa un grado personal
o teórico de que un evento suceda.
- Evento aleatorio: “Son los resultados o acontecimientos cuyo valor, dada una
decisión previa, están sujetos al azar”.
- Todos los eventos que se estudien en esta materia se considerarán “eventos aleatorios” y las decisiones que deba
tomar, desde un punto de vista Estadístico, se considerarán como un “Experimento aleatorio”. En este
experimento aleatorio, todos los posibles eventos aleatorios que puedan existir en el mismo forman un conjunto
llamado “Espacio muestral”. En el caso de la moneda que estudiamos previamente, el experimento aleatorio es
jugar al “volado”, el espacio muestral es un conjunto de solo dos eventos aleatorios: tener cara o tener sol.
- Evento: “El futuro acontecimiento que
resultará de cualquier acción tomada en el
presente”.
- Probabilidad: “Una medida numérica que cuantifica
numéricamente la posibilidad de que un resultado
o evento se presente”.
- En un español más simple, la probabilidad es un número que indica a quien lo utiliza qué posibilidad se tiene de
que algo suceda. El ejemplo más común se escucha en los noticieros: “El día de hoy se tendrán nublados con una
probabilidad de precipitación pluvial de 80%”. Esto indica que el día de hoy es muy posible que llueva.
- 1.3.1 La media, la mediana y la moda
- Hasta ahora se ha dado una definición introductoria de la probabilidad de que suceda un evento aleatorio o
resultado esperado y se han dado dos ejemplos sencillos. Ahora recuerde usted el evento aleatorio de la línea de
producción de botellas de agua previamente mencionado. Usted no sabe ni sabrá con seguridad cuáles serán los
posibles resultados del espacio muestral del nivel de llenado de sus botellas. Este puede ser tan grande como:
- espacio muestral= {0 l., 0.00000001 l., 0.0000023 l., 0.55647726 l., 1 l.,…}
- Es entonces que usted, para organizar la vasta información que tiene y tener un par de números en la cabeza que
le resuman todos los datos, recurre a otro tipo de medidas que vio en Estadística I y que se conocen como
medidas descriptivas. Las medidas descriptivas a las que se refiere esto son las medidas de tendencia central y
las de dispersión y, para esto, se requiere una observación de diferentes elementos de una población o conjunto
de características buscadas en un grupo de objetos que la presentan.
- Población: Conjunto de todas las observaciones
posibles sobre una característica de interés
observada.
- Las medidas de tendencia central son, como su nombre lo dice, aquellas que identifican el comportamiento más
común en la característica buscada y las tres más empleadas son la media (o promedio), la mediana y la moda
- La media o promedio ( ): Es la medida de tendencia central que se obtiene de sumar los valores de todas las
observaciones ( ) de la población y dividir dicha suma entre el número de observaciones ( ). Fórmula 2:
- La mediana: Es el valor de la observación que, una vez
ordenada la población de la menor observación a la
mayor, que se encuentra exactamente a la mitad de la
población.
- condición necesaria para que exista la mediana es que, al
establecerse la misma, se cuente el mismo número de
observaciones arriba y debajo de la misma.
- Moda: Es el valor de evento muestral que presenta el mayor
número de observaciones en la población estudiada.
- Las medidas de dispersión, como su nombre lo indican, determinan el nivel de separación (dispersión) que todas
las observaciones de una población tienen respecto a una de sus medidas de tendencia central.
- Moda: Es el valor de evento muestral que presenta el mayor
número de observaciones en la población estudiada.
- La mediana: Es el valor de la observación que, una vez
ordenada la población de la menor observación a la
mayor, que se encuentra exactamente a la mitad de la
población.
- La media o promedio ( ): Es la medida de tendencia central que se obtiene de sumar los valores de todas las
observaciones ( ) de la población y dividir dicha suma entre el número de observaciones ( ). Fórmula 2:
- Población: Conjunto de todas las observaciones
posibles sobre una característica de interés
observada.
- espacio muestral= {0 l., 0.00000001 l., 0.0000023 l., 0.55647726 l., 1 l.,…}
- 1.3.2 La varianza y la desviación estándar ¿qué significan? y ¿Por qué la calculamos la varianza elevando al cuadrado las
diferencias respecto a la media?
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de aplicaciones.
La misma simplemente se dedica a medir el tamaño promedio de separación que las diferentes
observaciones de la población tienen respecto a u media ().
- Varianza: La separación promedio que tienen las observaciones
de una población respecto a su media
- Si se piensa de nuevo en nuestro ejemplo del nivel de llenado de las botellas de agua, se puede apreciar que
nuestros millones de botellas tienen diferentes separaciones respecto al llenado promedio. Para ilustrar esto
suponga usted que la población de observaciones de botellas lleva a un nivel de llenado promedio de 0.89l (
0.89l ) y que tiene solo una población de tres botellas producidas con 0.78 l, 0.92 l y 0.84 l. La separación
respectiva respecto a la media en cada caso es de -0.11 l, 0.11 l y 0.02 l. La varianza simplemente determina la
separación promedio. Es decir, el promedio de -0.11 l, 0.11 l y 0.02 l.
- Esto le estaría diciendo erróneamente que la varianza o desviación promedio respecto a la media no existe.
Cosa que claramente no es cierta. Para dar una mayor idea, recuerde ahora el ejemplo de los dados y la
población de posibles resultados:
- Retomando la fórmula 2 puesta en página previas, usted tendrá que sumar las diferencias respecto a la media
(columna de la derecha). Sin embargo, aquí se puede usted llevar una mala sorpresa al ver que la suma da cero y,
al calcular la diferencia media, el cálculo nos dice que no existe separación alguna. ¿Será cierto eso? Si usted
revisa la tabla estudiada y los valores de las diferencias podrá observar que no. Entonces ¿Qué se sugiere hacer?
Para calcular la varianza, simplemente se eleva al cuadrado las diferencias respecto a la media expuestas en la
columna derecha de la tabla anterior, se suman y se dividen entre el número de observaciones. Esto sería:
- Retomando la fórmula 2 puesta en página previas, usted tendrá que sumar las diferencias respecto a la media
(columna de la derecha). Sin embargo, aquí se puede usted llevar una mala sorpresa al ver que la suma da cero y,
al calcular la diferencia media, el cálculo nos dice que no existe separación alguna. ¿Será cierto eso? Si usted
revisa la tabla estudiada y los valores de las diferencias podrá observar que no. Entonces ¿Qué se sugiere hacer?
Para calcular la varianza, simplemente se eleva al cuadrado las diferencias respecto a la media expuestas en la
columna derecha de la tabla anterior, se suman y se dividen entre el número de observaciones. Esto sería:
- Esto le estaría diciendo erróneamente que la varianza o desviación promedio respecto a la media no existe.
Cosa que claramente no es cierta. Para dar una mayor idea, recuerde ahora el ejemplo de los dados y la
población de posibles resultados:
- Varianza: La separación promedio que tienen las observaciones
de una población respecto a su media
- 1.3.3 Reglas de dedo para calcular la media y la desviación estándar:
- Media: 1. Tome todas las observaciones de su población (o muestra como se verá en breve) 2. Sume los valores
numéricos de las observaciones. 3. Cuente el número de observaciones que tiene. 4. Divida la suma de valores
numéricos de las observaciones entre el número de las mismas.
- Desviación estándar: Varianza: 1. Recuerde que debe calcularse la varianza para obtener este valor. Por tanto,
debe calcularse primero la media. 2. A cada valor numérico de cada observación se le resta el valor de la media
(vea columna “diferencias respecto a la media” en la tabla 2). Es decir, se calcula la diferencia entre cada valor
numérico de cada observación respecto a la media.3. Las diferencias calculadas anteriormente se elevan al
cuadrado (vea columna “diferencia elevada al cuadrado” en la tabla 2). 4. Se suman las diferencias calculadas. 5.
Se divide esta suma entre el número de observaciones.
- Ahora sí, la Desviación estándar: 6. En los pasos A a F se calculó la varianza. Si usted quiere utilizarla, está bien
pero es más recomendable utilizar la desviación estándar que se calcula simplemente sacando la raíz cuadrada
de la varianza lograda en el paso F.
- Ahora sí, la Desviación estándar: 6. En los pasos A a F se calculó la varianza. Si usted quiere utilizarla, está bien
pero es más recomendable utilizar la desviación estándar que se calcula simplemente sacando la raíz cuadrada
de la varianza lograda en el paso F.
- Desviación estándar: Varianza: 1. Recuerde que debe calcularse la varianza para obtener este valor. Por tanto,
debe calcularse primero la media. 2. A cada valor numérico de cada observación se le resta el valor de la media
(vea columna “diferencias respecto a la media” en la tabla 2). Es decir, se calcula la diferencia entre cada valor
numérico de cada observación respecto a la media.3. Las diferencias calculadas anteriormente se elevan al
cuadrado (vea columna “diferencia elevada al cuadrado” en la tabla 2). 4. Se suman las diferencias calculadas. 5.
Se divide esta suma entre el número de observaciones.
- 1.4.1 Mapa mental de lo hasta ahora visto
- Hasta ahora hemos visto qué es un evento aleatorio, cómo se calcula, de manera básica e intuitiva la probabilidad
y, por otro lado, separado pero relacionado, hemos visitado las dos medidas o estadísticas que más utilizaremos:
la media y la desviación estándar. En términos del tema que nos interesa esto es
- 1.4.2 Eventos aleatorios (variables aleatorias) discretos y continuos
- Cuando la población de observaciones que se tiene es la de un experimento aleatorio sencillo como es el
lanzamiento de una o dos monedas, el lanzamiento de uno o dos dados, los resultados de un juego de cartas o las
calificaciones de un grupo de clase, es muy simple aplicar la fórmula 1:
- Sin embargo, en poblaciones grandes o eventos continuos (ahorita conocerá el término), la forma de hacer esto
es diferente. Antes de hablar de ello, es necesario saber qué es un evento aleatorio discreto o un evento
discreto y qué es un evento continuo
- Evento aleatorio discreto: Es aquel cuyo conjunto de posibles
resultados o acontecimientos tienen una cantidad que se puede
contar aunque sea esta muy grande.
- Evento aleatorio continuo:
Es aquel cuyo conjunto de
posibles resultados o
acontecimientos tienen una
cantidad que no se puede
contar ya que esta es un
número infinito.
- Un ejemplo de evento aleatorio discreto puede ser el dado revisado, el número de mujeres profesionistas de la
contabilidad en la ciudad de Morelia o el número de butacas rotas en la universidad. Estos tres ejemplos de
poblaciones tienen eventos (ser mujer profesionista de la contabilidad, ser butaca rota) que se pueden contar.
Es decir son finitos.
- Un ejemplo de un evento aleatorio continuo serían los posibles valores que puede tomar la temperatura en
Morelia en cierto día. Puede tener valores como 10.51°, 10.53243°, etc. Otro ejemplo serían los rendimientos
diarios o por hora que puede tener el índice de la bolsa de valores. Dado que los posibles resultados en estos
eventos pueden ser prácticamente infinitos, se dice que estos eventos son continuos.
- Un ejemplo de un evento aleatorio continuo serían los posibles valores que puede tomar la temperatura en
Morelia en cierto día. Puede tener valores como 10.51°, 10.53243°, etc. Otro ejemplo serían los rendimientos
diarios o por hora que puede tener el índice de la bolsa de valores. Dado que los posibles resultados en estos
eventos pueden ser prácticamente infinitos, se dice que estos eventos son continuos.
- Evento aleatorio discreto: Es aquel cuyo conjunto de posibles
resultados o acontecimientos tienen una cantidad que se puede
contar aunque sea esta muy grande.
- 1.4.3 Cálculo de probabilidades en variables aleatorias discretas: El histograma
- Existen ocasiones en que las variables aleatorias arrojan observaciones que se repiten. Por ejemplo, piense en
el número de coches de cinco posibles colores: blanco, negro, rojo, azul y verde. Si cuenta todos los casos
posibles en el estacionamiento de la universidad podrá tener resultados como este:
- Para ilustrar un ejemplo, piense en un comerciante teórico que separa los
aguacates de la siguiente manera: Pone los aguacates que pesan de 50 gramos
o menos en una caja, los de 51 a 101 en otra, los de 102 a 152 gramos en otra y
así sucesivamente hasta crear 10 grupos o intervalos de 50 gramos de rango
que lleguen hasta los 500 g (vea tabla 6 para observar cómo quedaron los
grupos o intervalos). Suponga que usted se encuentra con el comerciante
comprando aguacates y este le dice que le venderá en 78 pesos tres aguacates
si le permite a dicho comerciante elegir de manera aleatoria en las diez cajas.
Ahora suponga que el comerciante tiene un total de 1,000 aguacates en
inventario repartido de la manera que se presenta en el cuadro siguiente:
- Histograma de frecuencias: Representación gráfica de una distribución de
frecuencia de una variable aleatoria continua.
- Para cerrar el tema del histograma, se ve que esta herramienta, que parte de la tabla de frecuencias, es de utilidad para
organizar muchas observaciones o datos de una población y convertir un problema de variables aleatorias continuas en
uno de variables discretas.
- Histograma de frecuencias: Representación gráfica de una distribución de
frecuencia de una variable aleatoria continua.
- Para ilustrar un ejemplo, piense en un comerciante teórico que separa los
aguacates de la siguiente manera: Pone los aguacates que pesan de 50 gramos
o menos en una caja, los de 51 a 101 en otra, los de 102 a 152 gramos en otra y
así sucesivamente hasta crear 10 grupos o intervalos de 50 gramos de rango
que lleguen hasta los 500 g (vea tabla 6 para observar cómo quedaron los
grupos o intervalos). Suponga que usted se encuentra con el comerciante
comprando aguacates y este le dice que le venderá en 78 pesos tres aguacates
si le permite a dicho comerciante elegir de manera aleatoria en las diez cajas.
Ahora suponga que el comerciante tiene un total de 1,000 aguacates en
inventario repartido de la manera que se presenta en el cuadro siguiente:
- 1.4.4 Distribuciones de probabilidad
- En la definición de histograma se acaba de identificar un término que será fundamental en la Estadística inferencial: La
distribución de frecuencias. Esta no es más que la forma en que se acomodan las diferentes frecuencias de suceso de los
eventos aleatorios dado un intervalo dado.
- Nótese en la gráfica 2 cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés para usted como
contador, administrador o informático: “El proveedor del comerciante solo produce aguacates de peso alto ya que las
mayores frecuencias se encuentran entre los 204 y los 407 gramos. Ya la mayor parte de los aguacates se distribuye en
estas cajas o intervalos
- Qué pasa ahora si en lugar de graficar el histograma se presenta una línea donde se muestra la distribución de
probabilidades calculadas en la tabla 6? Observe usted:
- ¿Le dice a usted algo esta distribución de probabilidad? Ahora tenemos dos posibles valores de peso de aguacate: 153-203
gramos y 405-458. ¿Podría usted fijar un patrón estadístico con esto? La respuesta es que sí se podría pero la estadística
que se utilice no será paramétrica. Utilizar la misma es muy sencillo pero eso se verá posteriormente.
- Qué pasa ahora si en lugar de graficar el histograma se presenta una línea donde se muestra la distribución de
probabilidades calculadas en la tabla 6? Observe usted:
- Nótese en la gráfica 2 cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés para usted como
contador, administrador o informático: “El proveedor del comerciante solo produce aguacates de peso alto ya que las
mayores frecuencias se encuentran entre los 204 y los 407 gramos. Ya la mayor parte de los aguacates se distribuye en
estas cajas o intervalos
- 1.4.5 Funciones de densidad de probabilidad
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de la
población y vemos que se debe seguir la siguiente receta: 1. Obtener todos los datos u observaciones de la
población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que se acomode
a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala entre el número de
intervalos que desee calcular y con eso logra el rango:
- En donde V pob max representa el valor máximo de la población, V pob min el valor mínimo y el número de
intervalos o grupos que desea calcular. 5. Clasifique todas las observaciones en cada uno de los n intervalos
que creó con la fórmula 5. 6. Cuente el número de observaciones en cada clasificación o intervalo. 7. Cuente
el número total de observaciones. 8. Calcule la probabilidad de suceso que tiene cada intervalo al utilizar la
fórmula 1 como sigue:
- Estas formulitas simples se llaman funciones de densidad de probabilidad y existen muchas en la Estadística.
Sin embargo, en esta materia veremos solo cuatro de ellas por el uso práctico que se dará en sus labores
como profesionista:
- 1. La función de densidad de probabilidad
“gaussiana” o “normal”. 2. La distribución
t-Student. 3. La distribución Xi cuadrada. 4. La
distribución F
- Función de densidad de probabilidad: función matemática que nos sirve para calcular probabilidades de
manera más simple (con menos pasos) que con los histogramas. Son más exactas y sirven para cuando
tenemos muchos datos o los posibles valores de las observaciones pueden ser infinitamente diferentes.
- Función de densidad de probabilidad normal o gaussiana: Función de densidad de probabilidad que es la más
utilizada y requiere de solo tres parámetros para su cálculo, el valor aleatorio ( i x ) al que se le determinará la
probabilidad, la media () y la desviación estándar ().
- Para ilustrar la función de densidad gaussiana o normal, vea usted de nuevo la gráfica 4 del inventario de
aguacates, la cual se organiza con un histograma de frecuencias conformado de 10 grupos o intervalos dados
en la tabla 7:
- Para ilustrar la función de densidad gaussiana o normal, vea usted de nuevo la gráfica 4 del inventario de
aguacates, la cual se organiza con un histograma de frecuencias conformado de 10 grupos o intervalos dados
en la tabla 7:
- Función de densidad de probabilidad normal o gaussiana: Función de densidad de probabilidad que es la más
utilizada y requiere de solo tres parámetros para su cálculo, el valor aleatorio ( i x ) al que se le determinará la
probabilidad, la media () y la desviación estándar ().
- 1. La función de densidad de probabilidad
“gaussiana” o “normal”. 2. La distribución
t-Student. 3. La distribución Xi cuadrada. 4. La
distribución F
- 1.4.6 La función de densidad de probabilidad normal estándar.
- Para continuar con el tema de probabilidades y la introducción de esta materia, hay que hacer una última
abstracción y hablar de un tipo de función de densidad que es la misma que la gaussiana o la normal;solo
que se presenta en otro “idioma” o forma de interpretación.
- Para exponer la idea de la distribución de probabilidad normal estándar, imagine usted ahora a dos
comerciantes que venden aguacates. Uno vive aquí en Morelia y el otro es una prima de él que vive en
Chicago. Los dos tienen el mismo proveedor de fruta y, un día hablando por teléfono, quisieron saber si la
calidad de aguacates que les vendía el proveedor (que es el mismo para ambos) era la misma. Para definir si
la calidad es la misma, utilizaron una función de densidad de probabilidad gaussiana o normal (por que los
dos tienen un inventario de miles de aguacates y les da flojera hacer histogramas).
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables aleatorias
que, por naturaleza o escala de medida, son diferentes.
- Por tanto, lo que se hace es ajustar los datos del inventario de aguacates en las diferentes escalas a valores
que sean comparables al aplicar el siguiente ajuste o estandarización.
- Por ejemplo, suponga ahora que tanto la comerciante de
Chicago como el comerciante de Morelia, estandarizan su
inventario de aguacates y comparan la función de densidad
de probabilidad normal estándar. Entonces podrían llegar a
una gráfica como la siguiente:
- ara terminar de platicar sobre la distribución normal estándar, simplemente se describe
cómo se transformaron los datos o la distribución de probabilidad de los dos inventarios
con medias y desviaciones estándar en unidades diferentes (gramos y onzas) a unidades
más similares como son “desviaciones estándar” o valores i
- Por tanto, lo que se hace es ajustar los datos del inventario de aguacates en las diferentes escalas a valores
que sean comparables al aplicar el siguiente ajuste o estandarización.
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables aleatorias
que, por naturaleza o escala de medida, son diferentes.
- Para exponer la idea de la distribución de probabilidad normal estándar, imagine usted ahora a dos
comerciantes que venden aguacates. Uno vive aquí en Morelia y el otro es una prima de él que vive en
Chicago. Los dos tienen el mismo proveedor de fruta y, un día hablando por teléfono, quisieron saber si la
calidad de aguacates que les vendía el proveedor (que es el mismo para ambos) era la misma. Para definir si
la calidad es la misma, utilizaron una función de densidad de probabilidad gaussiana o normal (por que los
dos tienen un inventario de miles de aguacates y les da flojera hacer histogramas).
- 1.4.6.1 Regla de dedo para comprender por qué utilizar una
distribución normal estándar:
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las
mismas o, peor aún, cuando no se tienen desviaciones estándar comparables, se debe
utilizar ya no una función de densidad de probabilidad normal común y corriente; sino
una estandarizada. 2. Para poder utilizar una distribución normal estándar, es necesario
ya no utilizar los valores originales de nuestro inventario sino más bien hacer una
operación que se conoce como “Estandarizar los valores de la variable”. 3. La
estandarización de valoresse logra con la fórmula 6:
- 1.4.7 El cálculo de la probabilidad utilizando la normal
estándar y las tablas correspondientes.
- Ahora usted ha visto la principal función de densidad de probabilidad
que se utiliza en la Estadística para ciencias administrativas: La
distribución normal estándar. Ya que usted estandarice los valores de sus
variables aleatorias, estará usted en capacidad de saber cómo se
calculan probabilidades de eventos cuando se tienen solamente los datos
de las observaciones de la población con que se trabaja al utilizar la
distribución de probabilidad normal estándar.
- Como se dijo antes en la regla de dedo recién expuesta, para poder trabajar con distribuciones de
probabilidad normal estándar, será necesario convertir los valores de las variables aleatorias en valores
estandarizados utilizando la fórmula 6.
- Como se dijo antes en la regla de dedo recién expuesta, para poder trabajar con distribuciones de
probabilidad normal estándar, será necesario convertir los valores de las variables aleatorias en valores
estandarizados utilizando la fórmula 6.
- 1.4.7.1 Diferentes formas de calcular una probabilidad.
Los valores de probabilidad acumulada.
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea
saber cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado
específico de 970 ml. Sin embargo, en la vida cotidiana, las probabilidades se determinan en base a
intervalos de datos.
- Si deseamos conocer la probabilidad de tener valores iguales a 910 ml (μ) (o sea entre 910 ml y 910 ml) usted
podrá observar en la tabla que da una probabilidad de cero (probabilidad de un valor Zi =0 es cero en la ilustración
1 que corresponde a la tabla de probabilidades). Por tanto las probabilidades de la desviación normal estándar
trabajan con intervalos de valores y no con valores puntuales.
- Por ejemplo, la probabilidad de tener niveles de llenado iguales o mayores que el nivel medio de μ=910 ml es de
50%. Esto se ilustra en la parte inferior de la gráfica 12. En la superior se expone el caso contrario: El nivel de
llenado es menor o igual a la media de 910 ml. Como se puede notar, el valor total del área de la superficie
sombreada tiene una magnitud de 50%. Es decir, la probabilidad de tener ya sea valores mayores e iguales que la
media o menores e iguales que la media.
- En base a lo previamente descrito, en la vida cotidiana se pueden tener los siguientes casos de cuantificación
de probabilidades (sigamos con el ejemplo del nivel de llenado de botellas):
- 1. La probabilidad de que el
valor del evento aleatorio
sea menor o igual a b (por
ejemplo que sea mayor o
igual a 970 ml). 2. La
probabilidad de que el valor
del evento aleatorio sea
mayor o igual a b por
ejemplo que sea menor o
igual a 970 ml). 3. La
probabilidad de que el valor
del evento se encuentre
entre a y b (por ejemplo que
el valor futuro se encuentre
entre el valor medio de 910
ml y 970 ml).
- Para responder esto, es de necesidad observar que la probabilidad de tener eventos menores o iguales a la
media de la población o mayores o iguales a dicho valor siempre será, como se vio en la gráfica 12, de 50% en
la distribución normal estándar:
- 1. La probabilidad de que el
valor del evento aleatorio
sea menor o igual a b (por
ejemplo que sea mayor o
igual a 970 ml). 2. La
probabilidad de que el valor
del evento aleatorio sea
mayor o igual a b por
ejemplo que sea menor o
igual a 970 ml). 3. La
probabilidad de que el valor
del evento se encuentre
entre a y b (por ejemplo que
el valor futuro se encuentre
entre el valor medio de 910
ml y 970 ml).
- Por ejemplo, la probabilidad de tener niveles de llenado iguales o mayores que el nivel medio de μ=910 ml es de
50%. Esto se ilustra en la parte inferior de la gráfica 12. En la superior se expone el caso contrario: El nivel de
llenado es menor o igual a la media de 910 ml. Como se puede notar, el valor total del área de la superficie
sombreada tiene una magnitud de 50%. Es decir, la probabilidad de tener ya sea valores mayores e iguales que la
media o menores e iguales que la media.
- Si deseamos conocer la probabilidad de tener valores iguales a 910 ml (μ) (o sea entre 910 ml y 910 ml) usted
podrá observar en la tabla que da una probabilidad de cero (probabilidad de un valor Zi =0 es cero en la ilustración
1 que corresponde a la tabla de probabilidades). Por tanto las probabilidades de la desviación normal estándar
trabajan con intervalos de valores y no con valores puntuales.
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea
saber cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado
específico de 970 ml. Sin embargo, en la vida cotidiana, las probabilidades se determinan en base a
intervalos de datos.
- Ahora usted ha visto la principal función de densidad de probabilidad
que se utiliza en la Estadística para ciencias administrativas: La
distribución normal estándar. Ya que usted estandarice los valores de sus
variables aleatorias, estará usted en capacidad de saber cómo se
calculan probabilidades de eventos cuando se tienen solamente los datos
de las observaciones de la población con que se trabaja al utilizar la
distribución de probabilidad normal estándar.
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las
mismas o, peor aún, cuando no se tienen desviaciones estándar comparables, se debe
utilizar ya no una función de densidad de probabilidad normal común y corriente; sino
una estandarizada. 2. Para poder utilizar una distribución normal estándar, es necesario
ya no utilizar los valores originales de nuestro inventario sino más bien hacer una
operación que se conoce como “Estandarizar los valores de la variable”. 3. La
estandarización de valoresse logra con la fórmula 6:
- Para continuar con el tema de probabilidades y la introducción de esta materia, hay que hacer una última
abstracción y hablar de un tipo de función de densidad que es la misma que la gaussiana o la normal;solo
que se presenta en otro “idioma” o forma de interpretación.
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de la
población y vemos que se debe seguir la siguiente receta: 1. Obtener todos los datos u observaciones de la
población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que se acomode
a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala entre el número de
intervalos que desee calcular y con eso logra el rango:
- En la definición de histograma se acaba de identificar un término que será fundamental en la Estadística inferencial: La
distribución de frecuencias. Esta no es más que la forma en que se acomodan las diferentes frecuencias de suceso de los
eventos aleatorios dado un intervalo dado.
- Existen ocasiones en que las variables aleatorias arrojan observaciones que se repiten. Por ejemplo, piense en
el número de coches de cinco posibles colores: blanco, negro, rojo, azul y verde. Si cuenta todos los casos
posibles en el estacionamiento de la universidad podrá tener resultados como este:
- Cuando la población de observaciones que se tiene es la de un experimento aleatorio sencillo como es el
lanzamiento de una o dos monedas, el lanzamiento de uno o dos dados, los resultados de un juego de cartas o las
calificaciones de un grupo de clase, es muy simple aplicar la fórmula 1:
- Hasta ahora hemos visto qué es un evento aleatorio, cómo se calcula, de manera básica e intuitiva la probabilidad
y, por otro lado, separado pero relacionado, hemos visitado las dos medidas o estadísticas que más utilizaremos:
la media y la desviación estándar. En términos del tema que nos interesa esto es
- Media: 1. Tome todas las observaciones de su población (o muestra como se verá en breve) 2. Sume los valores
numéricos de las observaciones. 3. Cuente el número de observaciones que tiene. 4. Divida la suma de valores
numéricos de las observaciones entre el número de las mismas.
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de aplicaciones.
La misma simplemente se dedica a medir el tamaño promedio de separación que las diferentes
observaciones de la población tienen respecto a u media ().
- Hasta ahora se ha dado una definición introductoria de la probabilidad de que suceda un evento aleatorio o
resultado esperado y se han dado dos ejemplos sencillos. Ahora recuerde usted el evento aleatorio de la línea de
producción de botellas de agua previamente mencionado. Usted no sabe ni sabrá con seguridad cuáles serán los
posibles resultados del espacio muestral del nivel de llenado de sus botellas. Este puede ser tan grande como:
- Ya que se estableció el tipo de escenario en donde usted tomará decisiones, es de necesidad recordar un
elemento de importancia: La probabilidad. Esta se define como “Una medida numérica que cuantifica
numéricamente la posibilidad de que un resultado o evento se presente”
- De entrada hay que recordar que la Estadística es una rama de la Matemática consistente en “El conjunto de
técnicas de recolección, presentación y correcto análisis de información numérica relacionada con facilitar la toma
decisiones frente a situaciones de riesgo (falta de certeza)”. Aquí usted podrá identificar un elemento y
circunstancia de la vida real: Los individuos, en lo cotidiano, estamos sujetos a tomar decisiones con falta de
certeza. Y aquí es donde hacemos un primer paréntesis.
- Un primer impulso que todos los alumnos tienen es creer que, por el hecho de estudiar para contadores,
administradores o informáticos, la Estadística sirve solo para rellenar la currícula que se ofrece en la universidad y
que nunca la utilizarán en su vida futura. Esto es realmente tanto falso como trágico ya que, como futuros
profesionistas independientes, investigadores, dueños de empresas o cabezas de gobierno (por citar casos de dónde
se ejercerá su maravillosa profesión y en donde se necesita de esta materia) deberán tomar decisiones.
Media attachments
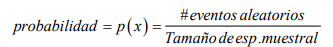{kind=link}
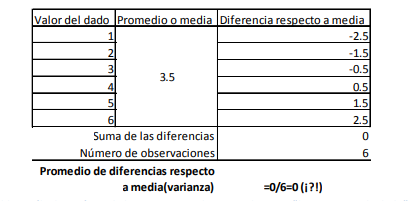{kind=link}
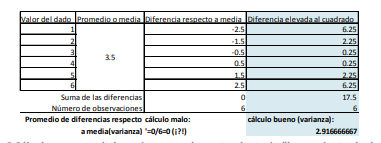{kind=link}
{kind=link}
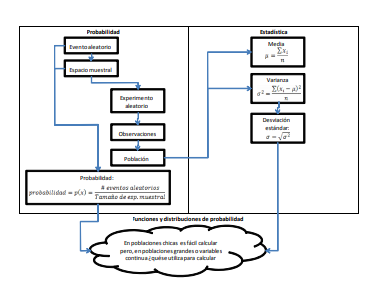{kind=link}
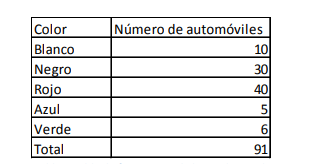{kind=link}
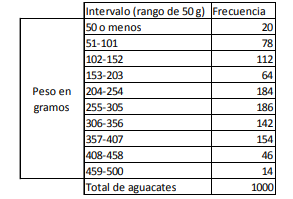{kind=link}
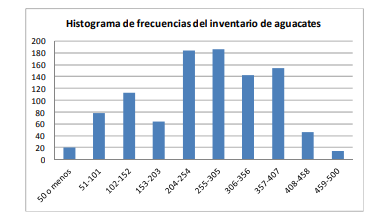{kind=link}
{kind=link}
{kind=link}
{kind=link}
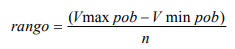{kind=link}
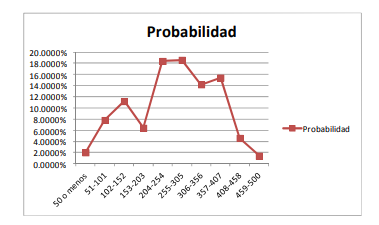{kind=link}
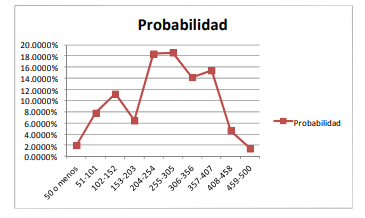{kind=link}
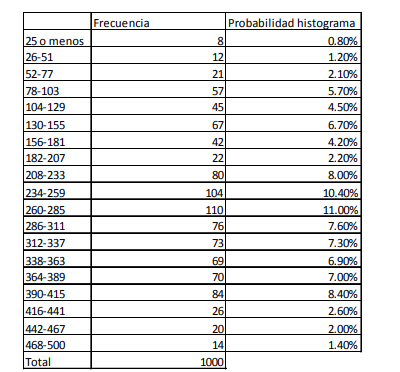{kind=link}
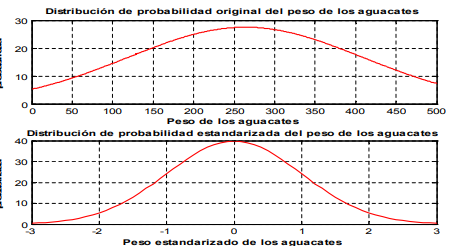{kind=link}
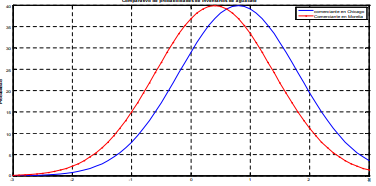{kind=link}
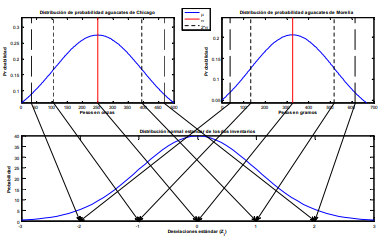{kind=link}
{kind=link}
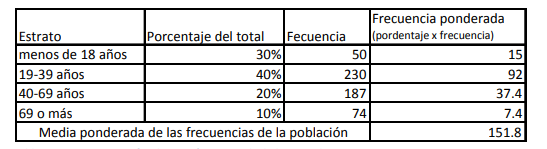{kind=link}
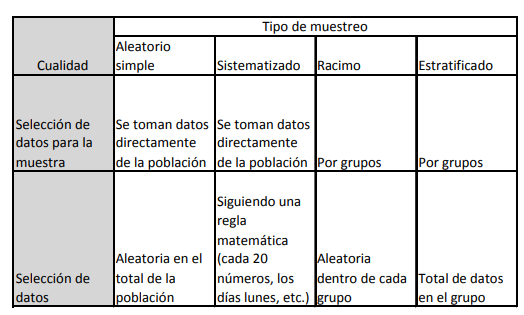{kind=link}
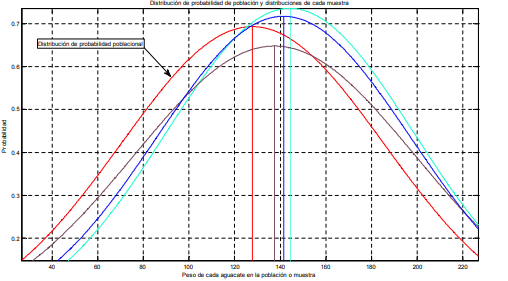{kind=link}
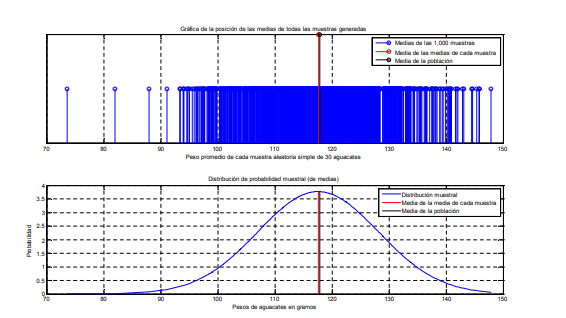{kind=link}
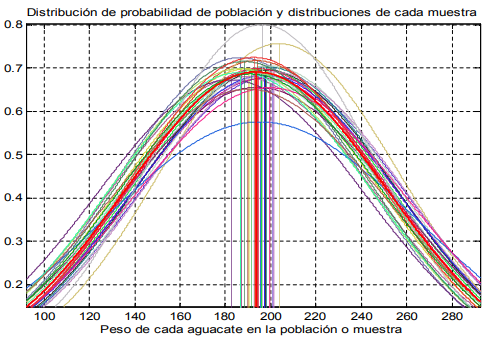{kind=link}
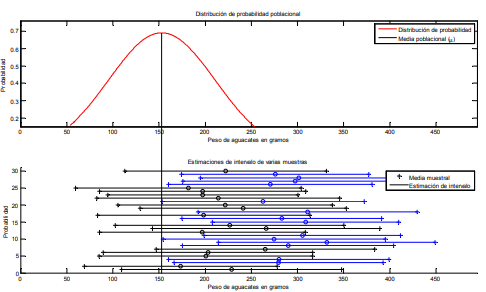{kind=link}
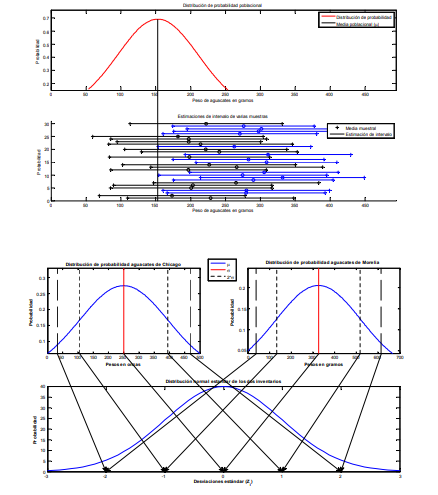{kind=link}
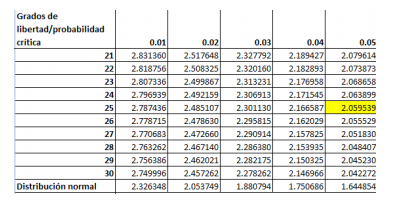{kind=link}
{kind=link}
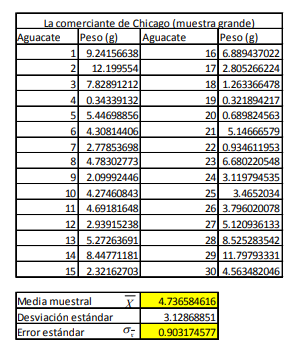{kind=link}
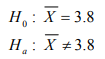{kind=link}
{kind=link}
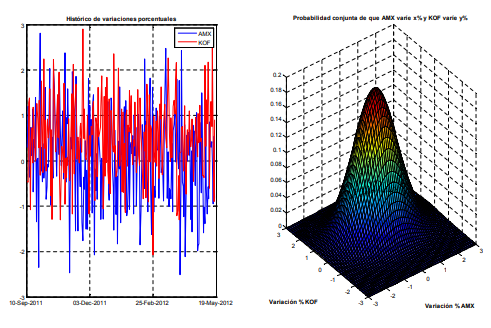{kind=link}
{kind=link}
{kind=link}
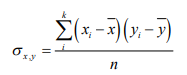{kind=link}
{kind=link}
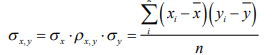{kind=link}
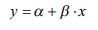{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.