Description

|
|
Created by William Martinez Luevanos
over 5 years ago
|
|
- 1.2 Repaso de conceptos y
definiciones y Estadistica
- Estadística:
Annotations:
- Escenario de certeza: Escenario en el que el individuo sabe con seguridad las consecuencias de la decisión que tome. Escenario de riesgo:Escenario en el que elindividuo carece decerteza alguna y puedecuantificar o determinarlos diferentes resultadosfuturos de su decisión conla Estadística. Escenario de incertidumbre:Escenario en el que el individuo sabe que la Estadística no le será de utilidad ya que no puede cuantificar los diferentes resultados futuros de su decisión. Escenario de conflicto:Escenario en el que el individuo puede o no conocer los resultados futuros. Sin embargo, estos no dependen de cuestiones estadísticas; sino de los gustos e intenciones de otros individuos que no se pueden saber a ciencia cierta
- Estadística:
- 1.2.1 La probabilidad
¿Qué es y cómo se
cuantifica?
Annotations:
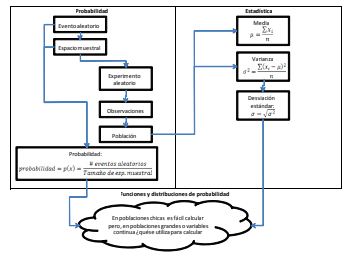
- Probabilidad: “Una medida numérica que cuantifica numéricamente la posibilidad de que un resultado o evento se presente”. Evento: “El futuro acontecimiento que resultará de cualquier acción tomada en el presente” Evento aleatorio: “Son los resultados o acontecimientos cuyo valor, dada una decisión previa, están sujetos al azar”. Experimento aleatorio: “Es una actividad sujeta a las leyes de la probabilidad en la que se puede obtener uno solo de los eventos aleatorios que conforman el espacio muestral”. Espacio muestral: “Es el conjunto de posibles eventos aleatorios (resultados) que pueden tenerse en un experimento aleatorio” Probabilidad subjetiva: Es una medida numérica que expresa un grado personal o teórico de que un evento suceda. Probabilidad objetiva: Es una medida numérica que cuantifica la posibilidad de que un evento aleatorio suceda en relación al total de eventos de un espacio muestral.
- 1.3 Medidas de tendencia
central y medidas de
dispersión.
- 1.3.1 La media, la mediana
y la moda
Annotations:
- Moda:Es el valor de evento muestral que presenta el mayor número de observaciones en la población estudiada. La mediana:Es el valor de la observación que, una vez ordenada la población de la menor observación a la mayor, que se encuentra exactamente a la mitad de la población. La media o promedio ( ):Es la medida de tendencia central que se obtiene de sumar los valores de todas las observaciones ( ) de la población y dividir dicha suma entre el número de observaciones ( ) Población:Conjunto de todas las observaciones posibles sobre una característica de interés observada.
- 1.3.2 La varianza y la desviación estándar
¿qué significan? y ¿Por qué la calculamos
la varianza elevando al cuadrado las
diferencias respecto a la media?
- Varianza:
Annotations:
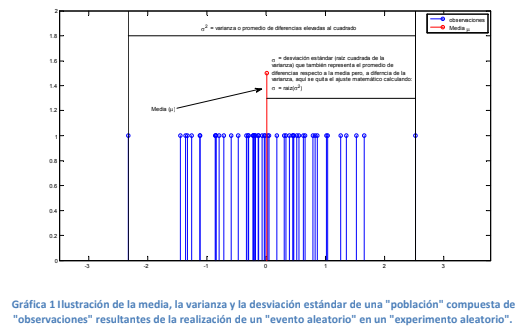
- La separación promedio que tienen las observaciones de una población respecto a su media.
- La varianza simplemente
determina la separación
promedio.
- Varianza:
- 1.3.3 Reglas de dedo para calcular la media
y la desviación estándar:
- Media:
Annotations:
- 1. Tome todas las observaciones de su población (o muestra como se verá en breve) 2. Sume los valores numéricos de las observaciones. 3. Cuente el número de observaciones que tiene. 4. Divida la suma de valores numéricos de las observaciones entre el número de las mismas.
- Desviación
estándar:
Varianza:
Annotations:
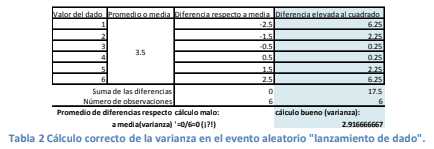
- 1. Recuerde que debe calcularse la varianza para obtener este valor. Por tanto, debe calcularse primero la media. 2. A cada valor numérico de cada observación se le resta el valor de la media (vea columna “diferencias respecto a la media” en la tabla 2). Es decir, se calcula la diferencia entre cada valor numérico de cada observación respecto a la media. 3. Las diferencias calculadas anteriormente se elevan al cuadrado (vea columna “diferencia elevada al cuadrado” en la tabla 2). 4. Se suman las diferencias calculadas. 5. Se divide esta suma entre el número de observaciones.
- Ahora sí, la
Desviación
estándar:
Annotations:
- 6. En los pasos A a F se calculó la varianza. Si usted quiere utilizarla, está bien pero es más recomendable utilizar la desviación estándar que se calcula simplemente sacando la raíz cuadrada de la varianza lograda en el paso F.
- Media:
- 1.4 Cálculo de probabilidades:
los histogramas, las funciones
y distribuciones de
probabilidad.
- 1.4.1 Mapa mental de lo
hasta ahora visto
- 1.4.2 Eventos aleatorios
(variables aleatorias)
discretos y continuos
- Evento aleatorio
discreto:
Annotations:
- Es aquel cuyo conjunto de posibles resultados o acontecimientos tienen una cantidad que se puede contar aunque sea esta muy grande.
- Evento aleatorio
continuo:
Annotations:
- Es aquel cuyo conjunto de posibles resultados o acontecimientos tienen una cantidad que no se puede contar ya que esta es un número infinito.
- Evento aleatorio = Variable aleatoria (en
Matemáticas)
- Evento aleatorio
discreto:
- 1.4.3 Cálculo de probabilidades
en variables aleatorias
discretas: El histograma.
- Histograma de
frecuencias:
Annotations:
- Representación gráfica de una distribución de frecuencia de una variable aleatoria continua.
- Histograma de
frecuencias:
- 1.4.4 Distribuciones de
probabilidad.
- 1.4.5 Funciones de densidad de
probabilidad
- Hasta ahora se ha hablado de una
distribución de probabilidad obtenida
totalmente de los datos de la población
y vemos que se debe seguir la siguiente
receta:
Annotations:
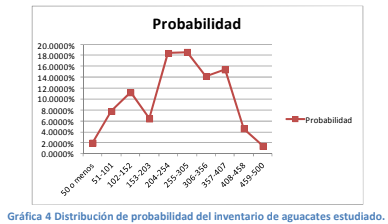
- 1. Obtener todos los datos u observaciones de la población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que se acomode a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala entre el número de intervalos que desee calcular y con eso logra el rango: En donde V pob max representa el valor máximo de la población, V pob min el valor mínimo y el número de intervalos o grupos que desea calcular. 5. Clasifique todas las observaciones en cada uno de los n intervalos que creó con la fórmula 5. 6. Cuente el número de observaciones en cada clasificación o intervalo. 7. Cuente el número total de observaciones. 8. Calcule la probabilidad de suceso que tiene cada intervalo al utilizar la fórmula 1 como sigue:
- Función de densidad
de probabilidad:
Annotations:
- función matemática que nos sirve para calcular probabilidades de manera más simple (con menos pasos) que con los histogramas. Son más exactas y sirven para cuando tenemos muchos datos o los posibles valores de las observaciones pueden ser infinitamente diferentes.
- Función de densidad de
probabilidad normal o
gaussiana:
Annotations:
- Función de densidad de probabilidad que es la más utilizada y requiere de solo tres parámetros para su cálculo, el valor aleatorio ( i x ) al que se le determinará la probabilidad, la media () y la desviación estándar ().
- Hasta ahora se ha hablado de una
distribución de probabilidad obtenida
totalmente de los datos de la población
y vemos que se debe seguir la siguiente
receta:
- 1.4.5.1 Cálculo de probabilidades
con función de densidad de
probabilidad normal o
gaussiana.
- 1. De todos los datos que se tienen se
calcula la media utilizando la fórmula 2:
- 2. Con la media se calcula la desviación
estándar observando que primero debe
calcularse la varianza con la fórmula 3:
- 3. Ya que se tienen estos dos simples
cálculos que puede hacerlos Excel (como
veremos en breve), se aplica la formulita
de probabilidad conocida como función de
densidad de probabilidad gaussiana:
- 1. De todos los datos que se tienen se
calcula la media utilizando la fórmula 2:
- 1.4.6 La función de densidad de
probabilidad normal estándar.
Annotations:
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables aleatorias que, por naturaleza o escala de medida, son diferentes. Por tanto, lo que se hace es ajustar los datos del inventario de aguacates en las diferentes escalas a valores que sean comparables al aplicar el siguiente ajuste o estandarización.
- 1.4.6.1 Regla de dedo para
comprender por qué utilizar una
distribución normal estándar:
Annotations:
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las mismas o, peor aún, cuando no se tienen desviaciones estándar comparables, se debe utilizar ya no una función de densidad de probabilidad normal común y corriente; sino una estandarizada. 2. Para poder utilizar una distribución normal estándar, es necesario ya no utilizar los valores originales de nuestro inventario sino más bien hacer una operación que se conoce como “Estandarizar los valores de la variable”. 3. La estandarización de valoresse logra con la fórmula 6:
- 1.4.7 El cálculo de la probabilidad
utilizando la normal estándar y
las tablas correspondientes.
Annotations:
- Ahora usted ha visto la principal función de densidad de probabilidad que se utiliza en la Estadística para ciencias administrativas: La distribución normal estándar.
- 1.4.7.1 Diferentes formas de
calcular una probabilidad. Los
valores de probabilidad
acumulada.
Annotations:
- 1. Calcular la probabilidad de que el nivel de llenado se encuentre el nivel de la media (μ=901 ml) y el de 940 ml: p ml p z ( 940 ) ( 0.39840637) 15.45% i 2. Calcular la probabilidad de que el nivel de llenado tenga una magnitud entre el nivel de la media (μ=901 ml) y el de 960 ml: p ml p z ( 960 ) ( 0.66401062) 24.66% i 3. Restar a la probabilidad mayor, la probabilidad menor y, con esto, se tiene la probabilidad de que la botella tenga un nivel de llenado entre 940 ml y 960 ml: (940 960 ) ( 960 ) ( 940 ) p ml x ml p ml p ml i 24.66% 15.45% 9.18%
- 1.4.1 Mapa mental de lo
hasta ahora visto
- 2 Teoría del muestreo
- Población:
Annotations:
- Conjunto de todas las observaciones posibles sobre una característica de interés observada.
- Muestra:
Annotations:
- subconjunto de una población de la cual se deriva.
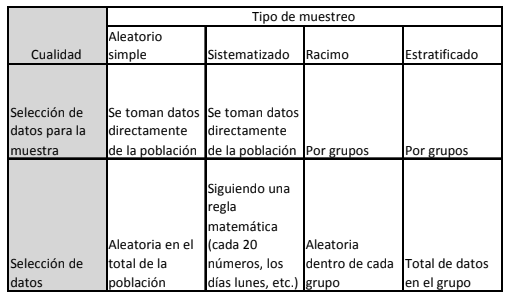
- 2.1 Tipos de muestreo
Annotations:
- 1. Muestreo aleatorio simple. 2. Muestreo sistemático. 3. Muestreo de racimo. 4. Muestreo estratificado.
- 2.2 Muestreo aleatorio
simple
Annotations:
- Como su nombre lo indica, consiste en seleccionar, de manera aleatoria, una serie de observaciones, objetos o datos de una población sin seguir algún tipo de agrupamiento específico. Un ejemplo simple, retomando el caso de los niveles de llenado de las botellas, sería ir una directamente de la línea de producción, luego dos y luego una y así sucesivamente hasta llegar a un número determinado de botellas u observaciones. Por ejemplo, 500.
- 2.3 Muestreo
sistemático
Annotations:
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos predeterminados. Por ejemplo, piense usted que tiene 2,000 cajas de aguacate foliadas todas y listas para empacarse a Estados Unidos. Ahora elige primero la caja número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una muestra de 100 cajas a las que le puede realizar el estudio estadístico que necesita.
- 2.4 Muestreo
estratificado.
Annotations:
- En este tipo de muestreo, se divide la población de datos en grupos homogéneos (mujeres y hombres, intervalo de pesos, etc.) y se determina qué proporción representa cada estrato o grupo. Cuando se analizan las características y parámetros como media, desviación estándar, etc., se ponderan los mismos en función de su representación o proporción de peso respecto la población total y con esa ponderación se obtienen los parámetros y probabilidades totales de dicha población con este tipo de muestra.
- 2.5 Muestreo de
racimo.
Annotations:
- Esta forma de muestrear se parece a la anterior, con la diferencia de que primero se hacen estratos y luego se seleccionan miembros, datos u observaciones de cada uno de los estratos de una manera aleatoria. Por ejemplo, usted desea saber cuántas televisiones existen en la ciudad de Morelia. Entonces, usted divide la ciudad en colonias y elige, de cada colonia y de manera aleatoria, una serie de casas, toca la puerta y pregunta el número de televisiones que hay en cada una. Con esto toma muestras aleatorias no de la totalidad de la población sino de cada uno de los grupos que usted formó.
- 2.6 Diferencias operativas en cada
uno de los tipos de muestreo y
determinación del empleado en
Estadística Inferencial.
- 2.7 Diseño de un experimento: el
proceso que se sigue para tomar
decisiones.
Annotations:
- 1. Definir el objetivo: Los comerciantes definieron como objetivo determinar que la calidad de sus inventarios es la misma. 2. Definir lo que se medirá: Aquí los comerciantes definieron “calidad” como el peso de sus aguacates. En pocas palabras pusieron una hipótesis dada por: “Si nuestros inventarios de aguacates tienen el mismo peso, comparten la misma calidad”. 3. Definir el tamaño de muestra: Aquí los comerciantes decidieron no trabajar con la totalidad de su inventario porque son miles de aguacates pero acordaron tomar una muestra de 200 aguacates (cómo definir este número lo veremos en breve). 4. Analizar los datos: Aquí se emplean técnicas estadísticas, como es la comprobación de hipótesis, para concluir si el objetivo planteado se cumple o no. Por ejemplo, los comerciantes determinaron, con técnicas estadísticas, que sus inventarios son iguales. 5. Conclusión y toma de decisiones: En este punto, en base al diseño del experimento seguido hasta ahora, se concluye que los inventarios tienen la misma calidad y toman la decisión de no reclamar al proveedor.
- 2.8 Distribuciones de
probabilidad muestrales
Annotations:
- Distribución muestral. En estadística, ladistribución muestral es lo que resulta de considerar todas las muestras posibles que pueden ser tomadas de una población. Su estudio permite calcular la probabilidad que se tiene, dada una sola muestra, de acercarse al parámetro de la población.
- 2.8.1 Las estadísticas necesarias para
calcular la distribución normal
muestral
Annotations:
- Cuando usted trabaja con poblaciones, las medidas que son insumos necesarios para el cálculo de probabilidades se llaman Parámetros. Es decir, si los datos que usted tiene para analizar son la media y la desviación estándar. A estos dos se les denomina parámetros de su función de probabilidad. Sin embargo, para una función de probabilidad cuando usted tiene muestras, los insumos son los mismos y se llaman ahora estadísticas o medidas estadísticas. Y estas estadísticas son la media y el error estándar (recuerde que así le llamamos a la desviación estándar cuando tenemos datos de muestras).
- 2.8.2 Media muestral
Annotations:
- Como puede apreciar, la función de probabilidad normal estándar sigue utilizándose. Lo único que cambian son la forma de calcular la media y la desviación estándar. Para el caso de la media muestral, que ahora se denota como x , simplemente se calcula igual para todos los datos repitiendo la fórmula 1:
- 2.8.3 Error estándar
Annotations:
- separación que la media de su muestra tiene respecto a la verdadera media de la población y este se aproxima muy bien al simplemente dividir la desviación estándar de su muestra entre la raíz cuadrada del número de observaciones que integran su muestra.
- 2.8.4 Cálculo de probabilidades
con muestras.
Annotations:
- Para calcular la probabilidad en una muestra se sigue utilizando la misma tabla de distribución normal estándar y se siguen los mismos métodos de cálculo previamente vistos. Lo único que cambia es la fórmula 6 a la que se le sustituye la desviación estándar por el error estándar. Esto es:
- 2.9 El teorema del límite central y
una primera forma de determinar
el tamaño adecuado de la muestra
Annotations:
- “Una muestra de datos que no tenga una distribución de probabilidad normal podrá suponerse que está normalmente distribuida si su número de datos es mayor o igual a 30. si se conoce el tamaño total de la población (y estas es muy grande), su número de datos es menor o igual al 5% de la población total...”
- 2.10El multiplicador de población finita
Annotations:
- Para finalizar la revisión de la Teoría del muestreo que contempla este segundo tema del curso de Estadística II. Es de interés observar algo más del cálculo del error estándar. Líneas atrás se le observó que, cuando se trabaja con muestras, no se utiliza la desviación estándar sino el error estándar y que este se calcula simplemente al dividir la desviación estándar de su muestra entre la raíz cuadrada del número de observaciones en la misma:
- Población:
- 3 Estimaciones puntuales y de intervalo. La base de
la inferencia estadística.
- Estimaciones puntuales:
Annotations:
- Es un solo número que se utiliza para estimar un parámetro de la población: la media poblacional.
- Estimación de intervalo:
Annotations:
- Es un rango de valores que se utiliza para estimar un parámetro de la población.
- 3.1 Consideraciones para calcular
verdaderas estimaciones de intervalo
Annotations:
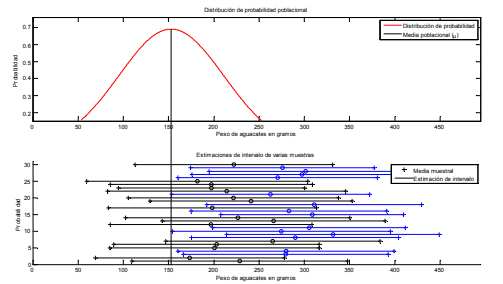
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y diferentes intervalos dados por lim.sup x erior x y lim.inf x erior x . Si se recuerda que la media muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se exponen las 30 muestras aleatorias en comparación a la media poblacional.
- 3.1.1 El verdadero cálculo del error muestral
cuando se desconoce la desviación
estándar de la población.
Annotations:
- Sin embargo, algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la desviación estándar de la población y en realidad lo que se está calculando la de una muestra. En el caso de muestras, lo que debe de hacerse es hacer un pequeño ajuste para calcular la desviación estándar muestral que ahora se denota como s:
- 3.1.2 La estimación de intervalo.
Annotations:
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que reconoce que este valor puede cambiar de muestra en muestra y que tiene el cálculo del error estándar de la muestra calculado con la fórmula 11, procederá usted a hacer una afirmación de este tipo: “El precio de la acción se estima que sea de $26.4666 y, con un 95% de confianza, se espera que ese valor oscile entre $26.6533 y $28.2802.” Si usted observa la gráfica 26, quizá no le sea muy preciso el pronóstico en el sentido de que el precio esperado y su intervalo están muy abajo. Con el análisis de regresión podremos mejorar la precisión. Baste con suponer, de momento, que la media muestral es buen pronóstico del valor futuro.
- 3.2 ¿Qué pasa cuando nuestra muestra
de datos no es grande? La distribución
t-Student
Annotations:
- No siempre se tienen muestras con una cantidad de datos u observaciones mayor o igual a 30. Cuando esto sucede, los datos no están normalmente distribuidos pero se pueden hacer estimaciones de intervalo utilizando la distribución t-Student.
- 3.2.1 Los parámetros para calcular la
distribución t-Student y su empleo
para el cálculo de estimaciones de
intervalo.
Annotations:
- Se ha visto previamente que la distribución normal, a parte del valor de la variable aleatoria i x , necesita solo dos simples parámetros o estadísticas12 que son la media y la desviación estándar. Para el caso de la distribución t-Student se siguen utilizando estos dos más uno llamado Grados de libertad (denotado como GL o ).
- Grados de libertad:
Annotations:
- Número de valores de una muestra que podemos especificar libremente, una vez que se sabe la media de la muestra.
- 3.3 estimaciones de intertvalo para comparar medias
3.3.1 Estimacion de intervalo para muestras apareaadas
grandes y pequeñas 3.3.1.1 Estimacion de intervalo para
muestras apareadas grandes
Annotations:
- Recuerde usted que, por el Teorema del Límite central, se puede considera una muestra como “grande” si tiene más de 30 observaciones e incluso se puede suponer que está normalmente distribuida si el tamaño de dicha muestra es menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se tienen 4 grupos de 20 individuos que dan un total de ). Por tanto, se puede aceptar el supuesto de que es muestra grande y de que está normalmente distribuida.
- 3.3.1.2 Estimación de intervalo para muestras
apareadas pequeñas
Annotations:
- Como se vio previamente para trabajar con estimaciones de muestra pequeñas, las fórmulas de cálculo del límite superior e inferior de la estimación de intervalo siguen siendo los mismos. Lo único que cambiaba en la fórmula es el valor i Z por el valor i t en la fórmula 18:
- 3.3.2 Estimaciones de intervalo para
muestras independientes
Annotations:
- Estimaciones de intervalo para muestras independientes. Para poder calcular las estimaciones de intervalo de diferencias de muestras independientes, lo único que debe cambiar es la forma de calcular tanto la media de las diferencias como . Esto es:
- 3.4 ¿Cómo determinar el intervalo de
confianza?
Annotations:
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el nivel de confianza que se imprimirá a las estimaciones de intervalo. Sin embargo, estas salen de la óptica y grado de Derechos de autor: Dr. Oscar Valdemar De la Torre Torres. (Registro en trámite) exigencia del curso ya que en el mismo se le enseñará a dominar las principales técnicas estadísticas de utilidad para su vida profesional. Si usted desea profundizar en esto, puede cursar una maestría en administración o una en finanzas que logre ese grado de profundización o puede consultar fuentes más avanzadas en Econometría o análisis de datos multivariante. Para usted, sea suficiente saber que un nivel de confianza de 90% o mayor es más que suficiente y que no debe de bajar de dicho valor para poder generar buenas estimaciones.
- 3.5 ¿Cómo determinar el tamaño de muestra cuando
se busca incrementar la precisión del intervalo de
confianza?
- Estimaciones puntuales:
- 4 Prueba de hipótesis: La técnica
clásica
Annotations:
- 1. Definir el objetivo: Definir el objetivo de la decisión que se va a hacer. Por ejemplo, determinar si la calidad del inventario es buena o no, si el número de piezas desperdiciadas es mayor a cierta cantidad, si el número de trimestres con pérdida es mayor a cierto objetivo o si el número de conexiones fallidas en un sistema de cómputo es mayor a determinada cantidad objetivo que se define en los estándares de calidad de la empresa de comunicaciones. Estos ejemplos se dan por citar algunos casos de lo que podría presentársele en su vida cotidiana. 2. Definir lo que se medirá: Aquí usted definirá cuál será la variable que delimitará la toma de sus decisiones. Por ejemplo “La cantidad de desperdicio” o el número de trimestres con pérdidas”. 3. Definir el tamaño de muestra: Esto es de vital importancia y se ha revisado en temas anteriores. Si usted no conoce el verdadero tamaño de la población ni sus parámetros como son la media y la desviación estándar, entonces apelará al teorema del límite central. Si se encuentra al caso contrario, usted empleará la fórmula 22 si y solo si se le proporciona algún valor que corresponda a la desviación estándar de dicha población. 4. Analizar los datos: Aquí se pueden utilizar varias técnicas de análisis. De entrada pueden ser lastécnicas de estimación (puntual y de intervalo) y la comprobación de hipótesis. 5. Conclusión y toma de decisiones: Para fines del tema que interesa, una vez que se aplica la comprobación de hipótesis, se tiene una conclusión de la que se toma una decisión en la empresa.
- 4.1 Comprobación de hipótesis de una
sola muestra.
Annotations:
- Definición de prueba de hipótesis: Método para evaluar creencias o afirmaciones sobre la realidad en base en la evidencia estadística, de tal forma que se determine la validez de dichas creencias o afirmaciones.
- 4.1.1 Ejemplos de los diferentes tipos de prueba de
hipótesis con técnica clásica aplicados a una
muestra simple.
Annotations:
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media objetivo o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la comerciante de Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar mejor el empleo de la prueba de hipótesis en diferentes circunstancias.
- 4.1.1.1 Pruebas de hipótesis para demostrar
igualdad de la media muestral con una media
poblacional conocida o hipotética.
Annotations:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) igual a 3.8 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa: 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad (recuerde que es un 95% de confianza o 5% de significancia que se determina con 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma al ser prueba de dos colas). Esto le lleva a un valor Z de 1.9599. 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una igualdad: 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una igualdad: 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir los valores críticos (IC IC, ) correspondientes al intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar los siguientes valores críticos: 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba de dos colas) se definió, en la gráfica anterior y como zona de aceptación, a todos los valores de X que se encuentren entre IC IC y . Esto lleva a la siguiente regla de aceptación: Aceptar H0 : Si IC X IC . Aceptar Ha : Si X IC IC X o . 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 4.1.1.1.2 Prueba de hipótesis para demostración de
igualdad empleando una muestra grande y una
escala estandarizada.
Annotations:
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada. Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a contrastar, considerando que es muestra grande. Esto lleva al cálculo de los estadísticos de la forma en que se expresa en la fórmula 24 para muestra grande:
- 4.1.1.2.1 Prueba de hipótesis para demostración de
desigualdad empleando muestras grandes y
escala original.
Annotations:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) diferente a 8.9 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una desigualdad: 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la gaussiana (normal estándar) y, por ende, se emplea un valor Z. 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad (recuerde que es un 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma). Esto le lleva a un valor Z de 1.9599. 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir los valores críticos (IC IC, ) del intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar los siguientes valores críticos: 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de desigualdad (prueba de dos colas) se definió, como zona de aceptación, a todos los valores de X que se encuentren entre IC IC y . Esto lleva a la siguiente regla de aceptación: 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 4.1.1.2.2 Prueba de hipótesis para demostración de
desigualdad empleando una muestra grande y una
escala estandarizada.
Annotations:
- Por tanto, en base a los datos que tiene la empresaria de Chicago, ella llega a la misma conclusión de la prueba de hipótesis anterior, con la diferencia de que se utilizó una escala diferente. Esto es, la calidad de la muestra es diferente al objetivo de 8.9Oz, por tanto debe aceptarse el embarque.
- 4.1.1.2.3 Prueba de hipótesis para un caso de
demostración de desigualdad con una muestra
pequeña con escala original.
Annotations:
- : Con lo anterior, la empresaria de Chicago puede aceptar el embarque enviado ya que la calidad del mismo es diferente al objetivo establecido de 8.9 Oz.
- 4.1.1.2.4 Prueba de hipótesis para demostración de
desigualdad empleando una muestra pequeña y una
escala estandarizada.
Annotations:
- Por tanto, en base a los datos que tiene la empresaria de Chicago, ella llega a la misma conclusión de la prueba de hipótesis anterior, con la diferencia de que se utilizó una escala diferente. Es decir, una estandarizada
- 4.1.1.3 Ejemplos de pruebas de hipótesis de
cola superior.
Annotations:
- Ahora se harán los 4 casos previamente vistos consistentes en diferentes escalas (original o estandarizada) así como diferentes tamaños de muestra (grande y pequeña). Para ello, se seguirán manejando las mismas muestras, la misma desviación estándar poblacional de 1.1. Lo único que cambiará es el objetivo de la empresaria. Ella buscará demostrar que la calidad mínima que debe tener el embarque para ser aceptado es de 2.5Oz. Es decir, hará una prueba de hipótesis de cola superior y demostrará que el peso del embarque tiene una calidad superior a 259Oz. Ahora se analizará cada caso específico
- 4.1.1.3.1 Prueba de hipótesis de cola superior
empleando muestra grande y escala original.
Annotations:
- En base a los datos que tiene la empresaria de Chicago, ella puede concluir que el embarque de 5,000 aguacates cumple con los estándares de calidad que tiene establecidos ya que la media de una muestra aleatoria de 30 aguacates es estadísticamente superior al peso objetivo planteado de Ho .
- 4.1.1.3.2 Prueba de hipótesis de cola superior
empleando muestra grande y escala estandarizada
Annotations:
- : Por tanto, en base a los datos que tiene la empresaria de Chicago, ella llega a la misma conclusión de la prueba de hipótesis anterior, con la diferencia de que se utilizó una escala diferente.
- 4.1.1.3.3 Prueba de hipótesis de cola superior
con muestra pequeña y escala original.
Annotations:
- Con lo anterior la empresaria de Chicago puede aceptar el embarque enviado ya que la calidad del mismo essuperior al objetivo de calidad establecido de 2.5 Oz
- 4.1.1.3.4 Prueba de hipótesis de cola superior
con muestra pequeña y escala de
estandarizada
Annotations:
- Se llega a la misma conclusión del caso anterior, con la diferencia de que se empleó una escala estandarizada para realizar a prueba
- 4.1.1.4 Ejemplos de pruebas de hipótesis de
cola inferior.
Annotations:
- Para el caso de la prueba de hipótesis de cola inferior se tiene la misma lógica de análisis que las pruebas de cola inferior, con la diferencia de que las reglas de decisión para aceptar la hipótesis nula () se dan por el renglón o ID 3 de la tabla 16:
- 4.2 ¿Cuándo se utiliza la escala original y
cuándo la estandarizada?
Annotations:
- Hasta el momento se ha observado que una de las variantes que puede tener la comprobación de hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada, lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra. Sin embargo, poco se ha dicho sobre el criterio para utilizar una escala u otra. En realidad, no existen reglas generales para decidir. Más bien la selección se da en función del tipo de problema y las preferencias del analista. Sin embargo, algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta sirve para homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve más para comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a inherente al analis
- 4.3 ¿Qué se hace cuando se desconoce la
desviación estándar poblacional?
Annotations:
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar poblacional o se supone una partiendo de la experiencia propia. Por ejemplo, la empresaria de chicago partió de lo que ha observado con su proveedor, en el sentido de fijar la desviación estándar del peso de aguacates que ha recibido a lo largo de la historia como de 1.1Oz. Sin embargo, no siempre se conoce este valor por lo que debe calcularse para poder determinar los estadísticos Z o t.
- 4.4 Pruebas de hipótesis para comparar
muestras.
Annotations:
- En este caso específico ya no se busca demostrar que los parámetros de una muestra se ajustan a los de una población o a un valor hipotético dado por H 0 . Más bien se busca comparar su media, buscando probar que estas sean iguales, mayor en la muestra A respecto a la B o viceversa
- 5 Prueba de hipótesis: Las técnicas Ji-
cuadrada y ANOVA
Annotations:
- En este tema específico utilizaremos un tipo de técnica de comprobación de hipótesis conocido como la técnica Ji-Cuadrada, la cual nos servirá para realizar dos cosas: 1. Determinar si dos o más variables o atributos de interés son independientes en base a los datos obtenidos en la muestra. 2. Determinar si el comportamiento de los datos con que se cuenta se explican o no con una distribución de probabilidad determinada como puede ser la normal, la t-Student u otro tipo de casos como son la F, la binomial, la Weibull, la Gumbel, la Poisson, la uniforme u otras. 3. Determinar si la varianza de una muestra es igual, inferior o superior a sierto valor hipotético, poblacional u objetivo.
- 5.1 La técnica Ji-Cuadrada 5.1.1 Prueba de hipótesis
para demostrar independencia.
Annotations:
- El enunciado de la hipótesis a plantear en este caso sería: “Las variables atributo de la computadora y estrato profesional están relacionadas entre sí y, por tanto pueden influir en la preferencia del usuario de la computadora.” Para fines de comprobación de hipótesis debe plantearse la hipótesis nula Ho
- 5.1.2 Distribución de probabilidad
ji-cuadrada.
Annotations:
- Recuerde usted que las distribuciones normal (gaussiana) y t-Student son simétricas e incluyen valores de probabilidad tanto a la izquierda como a la derecha del cero. Estas distribuciones de probabilidad son muy útiles para muchos fenómenos como los revisados. Sin embargo, cuando se trata con valores que solo son positivos, será de mucho interés tener una distribución de probabilidad que nunca tenga valores negativos en su distribución de probabilidad. Por ejemplo, el precio de una acción nuca tendrá valores negativos pero, en repetidas ocasiones de nuestros ejercicios, las estimaciones de intervalo llevaban a límites inferiores negativos que no era lógico que existan.
- 5.1.3 Algunas consideraciones a tomar
con la prueba ji-cuadrada.
Annotations:
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica ji-cuadrada para los tres usos que interesan: 1. Nunca se deben trabajar con tablas de contingencia que tengan frecuencias menores a 5. Es decir, que el valor de una celda sea menor a 5. Si en algún momento se presentara este caso en dos o más celdas, podemos eliminar algunas categorías (renglón o columna) y combinar los valores de la (s) eliminada (s) con otra que esté en el mismo caso y así lograr frecuencias mayores o iguales a 5. Sin embargo, esto tiene la limitante de la pérdida de una o varias categorías y el examen de independencia entre variables quedaría muy parcial. 2. Si, por alguna circunstancia, el valor ji-cuadrada derivado con la fórmula 24 diera cero, debe sospecharse del resultado ya que se puede estar en presencia de un problema de una inapropiada recolección de datos.
- 5.1.4 Prueba de hipótesis ji cuadrada para
bondad de ajuste (determinar la función de
probabilidad a emplear en un grupo de datos).
Annotations:
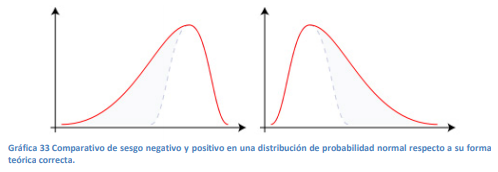
- Cuando la cola mes más larga a la izquierda se dice que se tiene un sesgo negativo ya que es mayor la probabilidad de tener valores más negativos que positivos. En caso contrario, se dice que se tiene un sesgo positivo (Gráfica de la derecha) por que se tienen mayores probabilidades de tener valores más positivos que negativos. Recuerde usted que una distribución de probabilidad normal debe ser simétrica, es decir, que se tengan la misma cantidad y probabilidades en los valores tanto positivos como negativos
- 5.1.5 Prueba de hipótesis ji-cuadrada para
hacer inferencias sobre la varianza de una
sola población (o muestra).
Annotations:
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de datos o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado ( 2 H 0 ). La lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica clásica. Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un valor ji-cuadrada tanto para el intervalo superior como el inferior (valores críticos), según el caso que aplique (si es prueba de una o dos colas)
- 5.1.6 Haciendo estimaciones de intervalos
de varianzas
Annotations:
- Así como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede replicar el ejercicio en el caso de las varianzas. Lo único que se tiene que hacer es calcular los correspondientes intervalos de confianza a través de la siguiente expresión
- 5.2 Prueba ANOVA.
Annotations:
- Nociones intuitivas de la prueba ANOVA: “Dos o más muestras serán iguales si la varianza de sus medias muestrales es igual que la varianza total de los datos de las tres muestras en conjunto”
- 5.2.1 La función de probabilidad F.
Annotations:
- ¿Recuerda usted la distribución Ji-cuadrada? ¿Recuerda que la utilizábamos para calcular la probabilidad de eventos que solo pueden tener valores positivos como es el caso de los valores que puede adoptar la varianza de una variable aleatoria? Pues hagamos el siguiente silogismo o razonamiento: 1. Si la distribución ji-cuadrada se utiliza para determinar las probabilidades de una varianza. 2. Si por otro lado es estadístico F es la división entre dos varianzas (la varianza entre muestras y entre el total de datos). 3. Entonces la función de probabilidad F se da por la siguiente expresión:
- 5.2.2 La prueba F.
Annotations:
- Ahora que se observa que se tienen los múltiples datos necesarios como los grados de libertad del numerador y los del denominador se puede calcular el estadístico F y determinar un valor crítico F empleando las tablas correspondientes al emplear los grados de libertad del numerador y del denominador. Para ello será de necesidad utilizar las tablas de valores F como la que se presenta en la plataforma Moodle en el tema correspondiente a la prueba ANOVA.
- 5.2.3 Prueba ANOVA para probar la igualdad en
la varianza entre dos muestras. El caso de la
cola superio
Annotations:
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar que la prueba ANOVA es muy poderosa para contrastar igualdad entre medias
- 6 Estadística multivariada: Regresión lineal simple
y multivariada.
Annotations:
- Covarianza: “Grado de separación promedio que tiene una variable aleatoria respecto a su media dado el grado de separación promedio que otra variable aleatoria tiene también respecto a su media” En donde la covarianza se denota como x y, . Como se puede apreciar la covarianza se determina de una manera muy sencilla: 1. Se calcula la diferencia entre el valor de cada observación de x menos su media por la diferencia de cada observación de y menos su media. 2. Se suman las multiplicaciones de cada i observación de x e y . 3. La sumatoria se divide entre n para calcular el valor promedio. A manera de reflexión respecto al método de cálculo, si observa detenidamente la fórmula 39, podrá observar que hay una estrecha relación entre la varianza de una variable aleatoria y la covarianza entre variables aleatorias. En específico usted podrá observar que si desea calcular la covarianza de la variable aleatoria 1 con la misma variable aleatoria 1, se llega a la covarianza:
- 6.1 El coeficiente de correlación y su
interacción con la covarianza
Annotations:
- Para ilustrar la idea usted piense en la luna y la tierra. La luna se mueve alrededor de la tierra y no del sol dado que la gravedad o grado de atracción entre ambas es mayor que el existente entre el sol y la luna. Por eso la luna no ha dejado a la tierra para irse con el sol. En las variables aleatorias sucede algo similar. Cuando estas son dependientes debe existir un grado de correlación o gravedad entre ellas para que puedan covariar. De lo contrario no existirá la covarianza y no existirá dependencia entre ellas. Vea usted el coeficiente de correlación como el “pegamento” entre variables. Con este pegamento o nivel de gravedad usted puede calcular la covarianza como sigue:
- 6.2 El modelo regresión lineal simple para
establecer relaciones estadísticas entre
variables y hacer pronósticos básicos.
Annotations:
- En este punto estamos entrando a una de las aplicaciones más importantes (sino la más importante) de la Estadística inferencial: la regresión. Con esta se logrará establecer la relación estadística entre variables de la forma: Esto quiere decir que la variable y se determina por una ecuación matemática en donde a una constante (que puede ser de cero o de otro valor positivo o negativo) se le suma un valor de x multiplicado por un número o constante (que puede ser de cero o de otro valor positivo o negativo). Si usted observa detenidamente el modelo de regresión, podrá apreciar que será capaz de hacer estimaciones del tipo “por cada valor de x se tendrá un valor de y dado por x “. Es decir ya podrá decir cuánto valdrá y dado el de x . La clave aquí estará en calcular los coeficientes y . Esto es lo que determinaremos a continuación y a lo que le daremos una explicación gráfica.
- 6.2.1 Determinación de los coeficientes del
modelo de regresión.
Annotations:
- Para determinar los coeficientes de regresión, siendo esta el modelo resultante de la interacción entre las dos variables, se ocupa la covarianza que es la que cuantifica el grado de variación promedio conjunta entre variables, la varianza de la variable regresora ( x ) 16, y la media muestral de la regresada (Y
Media attachments
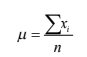{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
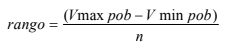{kind=link}
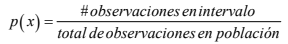{kind=link}
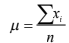{kind=link}
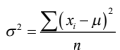{kind=link}
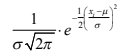{kind=link}
{kind=link}
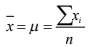{kind=link}
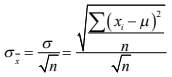{kind=link}
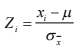{kind=link}
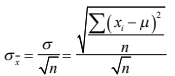{kind=link}
{kind=link}
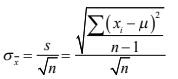{kind=link}
{kind=link}
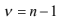{kind=link}
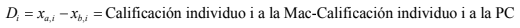{kind=link}
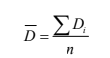{kind=link}
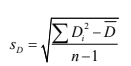{kind=link}
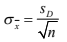{kind=link}
{kind=link}
{kind=link}
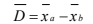{kind=link}
{kind=link}
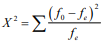{kind=link}
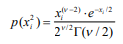{kind=link}
{kind=link}
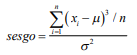{kind=link}
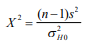{kind=link}
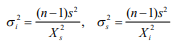{kind=link}
{kind=link}
{kind=link}
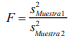{kind=link}
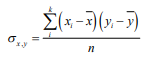{kind=link}
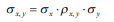{kind=link}
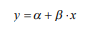{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.