Description
|
|
Created by Hector Lomas
over 5 years ago
|
|
- 1.1 ¿Para qué estudiamos esto?, ¿Cómo se come?, ¿Es un desperdicio de mi tiempo el estudiar Estadística
si soy contador, administrador o informático?
- Para dar una idea de esta relevancia, piense
usted en la empresa Apple Inc.
- Jobs retomó las riendas Macintosh, esta era una empresa que vendía
computadoras y tenía una tecnología más avanzada que las propias PC’s que trabajaban con
Windows.
- A lo largo de sus estudios le han enseñado muchas cosas como puede ser el manejo de los registros
contables y la información financiera de su empresa u organismo. También le han instruido cómo hacer
algunos estudios de mercado, algo de microeconomía aplicada a la empresa y se la ha dicho cómo son el
proceso administrativo y el de producción.
- La Estadística cobra importancia.
- Una idea de esta relevancia, piense usted en la empresa Apple Inc. Cuando el señor Jobs retomó las
riendas Macintosh , esta era una empresa que vendía computadoras y tenía una
tecnología más avanzada que las propias PC’s que trabajaban con Windows.
- Respecto a su muestra y demostrar una hipótesis: “Dado que una Mac cuesta lo mismo que una PC de
alto rendimiento, el usuario promedio prefiere una Mac a una PC porque su desempeño y su calidad es
superior.”
- Una idea de esta relevancia, piense usted en la empresa Apple Inc. Cuando el señor Jobs retomó las
riendas Macintosh , esta era una empresa que vendía computadoras y tenía una
tecnología más avanzada que las propias PC’s que trabajaban con Windows.
- La Estadística cobra importancia.
- A lo largo de sus estudios le han enseñado muchas cosas como puede ser el manejo de los registros
contables y la información financiera de su empresa u organismo. También le han instruido cómo hacer
algunos estudios de mercado, algo de microeconomía aplicada a la empresa y se la ha dicho cómo son el
proceso administrativo y el de producción.
- Era una empresa que vendía poco en relación a sus competidores y tenía pérdidas financieras,
debido a que los directivos anteriores veían a su empresa como proveedora de equipos de cómputo
avanzado para arquitectos, ingenieros y diseñadores. Es decir, se veían como una empresa de nicho y
apostaban a que la calidad prevalecería sobre el precio
- Jobs retomó las riendas Macintosh, esta era una empresa que vendía
computadoras y tenía una tecnología más avanzada que las propias PC’s que trabajaban con
Windows.
- 1.2 Repaso de conceptos y definiciones de Estadística I.
- “El conjunto de técnicas de recolección, presentación y correcto análisis de información numérica
relacionada con facilitar la toma decisiones frente a situaciones de riesgo”.
- Estadística: El conjunto de técnicas de recolección, presentación y correcto análisis de información
numérica relacionada con facilitar la toma decisiones frente a situaciones de riesgo
- Escenario de certeza: Escenario en el que el individuo sabe con seguridad las consecuencias de la
decisión que tome..
- Escenario de riesgo: Escenario en el que el individuo carece de certeza alguna y puede cuantificar o
determinar los diferentes resultados futuros de su decisión con la Estadística.
Annotations:
- Escenario de riesgo, este será en el que usted se contextualizará ya que utilizará la Estadística para aproximar los posibles resultados que tendrá usted al decidir por un proyecto, empresa, inversión o actividad.
- Escenario de incertidumbre: Escenario en el que el individuo sabe que la Estadística no le será de
utilidad ya que no puede cuantificar los diferentes resultados futuros de su decisión.
Annotations:
- Podría ser que usted intente determinar qué tan factible es que le caiga un meteorito a su nuevo restaurante. Eso, en algunos casos que no interesan a esta materia, podría determinarse.
- Escenario de conflicto: Escenario en el que el individuo puede o no conocer los resultados futuros. Sin
embargo, estos no dependen de cuestiones estadísticas; sino de los gustos e intenciones de otros
individuos que no se pueden saber a ciencia cierta.
Annotations:
- Pueden tenerse las negociaciones en la cámara de diputados. Por ejemplo, piense en un tema difícil como es una reforma fiscal. Algunos partidos propondrán algo y los otros quizá no cedan en su postura de aceptar o no dicha propuesta, por lo que los posibles resultados se podrían conocer, podrían modelarse con la Estadística pero, a decir verdad, el resultado no depende del modelado de un evento aleatorio sino de la voluntad de las partes en la negociación.
- Escenario de certeza: Escenario en el que el individuo sabe con seguridad las consecuencias de la
decisión que tome..
- 1.2.1 La probabilidad ¿Qué es y cómo se cuantifica?
- “Una medida numérica que cuantifica numéricamente la posibilidad de que un resultado o evento se
presente”.
- Probabilidad: “Una medida numérica que cuantifica numéricamente la posibilidad de que un
resultado o evento se presente”.
- En virtud de la definición de probabilidad dada, es de interés observar la definición de lo que se
conoce como “evento”.
- Evento: “El futuro acontecimiento que resultará de cualquier acción tomada en el presente”.
Annotations:
- Sin embargo, dado que la moneda lanzada y, en específico, el resultado que se logre, es algo sujeto al azar, se tiene que este evento es un “evento aleatorio” y el hecho de lanzar una moneda se conoce como “Experimento aleatorio” Todos los eventos que se estudien en esta materia se considerarán “eventos aleatorios” y las decisiones que deba tomar, desde un punto de vista Estadístico, se considerarán como un “Experimento aleatorio”. En este experimento aleatorio, todos los posibles eventos aleatorios que puedan existir en el mismo forman un conjunto llamado “Espacio muestral”.
- Evento aleatorio: “Son los resultados o acontecimientos cuyo valor, dada una decisión previa, están
sujetos al azar”.
- Experimento aleatorio: “Es una actividad sujeta a las leyes de la probabilidad en la que se puede obtener
uno solo de los eventos aleatorios que conforman el espacio muestral”.
- Espacio muestral: “Es el conjunto de posibles eventos aleatorios (resultados) que pueden tenerse en un
experimento aleatorio”.
- Espacio muestral: “Es el conjunto de posibles eventos aleatorios (resultados) que pueden tenerse en un
experimento aleatorio”.
- Experimento aleatorio: “Es una actividad sujeta a las leyes de la probabilidad en la que se puede obtener
uno solo de los eventos aleatorios que conforman el espacio muestral”.
- Probabilidad subjetiva: Es una medida numérica que expresa un grado personal o teórico de que un
evento suceda.
Annotations:
- Por ejemplo usted puede creer que una señora embarazada tiene 50% de probabilidades de dar a luz una niña o 50% de lograr un niño.
- Probabilidad objetiva: Es una medida numérica que cuantifica la posibilidad de que un evento aleatorio
suceda en relación al total de eventos de un espacio muestral.
Annotations:
- En un español más plano, la cantidad de veces que usted puede lograr un “tres” al lanzar un dado es uno. Es decir usted solo puede lograr un tres si lanza un dado ya que el dado solo tiene impreso dicho número una vez. Sin embargo el dado tiene seis números. Es decir, en nuestra terminología estadística, el experimento aleatorio de lanzar un dado tiene un espacio muestral consistente en seis eventos aleatorios
Annotations:
- Esto significa que la medida numérica de la posibilidad de obtener un 3 en el lanzamiento del dado es de 16.6666% que se logra de dividir el número de eventos aleatorios de interés (# ) entre el tamaño del espacio muestral que es de 6.
- Evento: “El futuro acontecimiento que resultará de cualquier acción tomada en el presente”.
- En virtud de la definición de probabilidad dada, es de interés observar la definición de lo que se
conoce como “evento”.
- “Una medida numérica que cuantifica numéricamente la posibilidad de que un resultado o evento se
presente”.
- 1.3 Medidas de tendencia central y medidas de dispersión.
- 1.3.1 La media, la mediana y la moda
- Ahora recuerde usted el evento aleatorio de la línea de producción de botellas de agua previamente
mencionado. Usted no sabe ni sabrá con seguridad cuáles serán los posibles resultados del espacio
muestral del nivel de llenado de sus botellas.
- Este puede ser tan grande como: espacio muestral= {0 l., 0.00000001 l., 0.0000023 l., 0.55647726 l., 1 l.,...}
- Por ejemplo, usted simplemente se dedica a medir el nivel llenado de todas las botellas de agua
producidas a lo largo de la vida de su fábrica y el conjunto de datos que logre de todas sus botellas se
llama población.
Annotations:
- Población: Conjunto de todas las observaciones posibles sobre una característica de interés observada.
- Por ejemplo, usted simplemente se dedica a medir el nivel llenado de todas las botellas de agua
producidas a lo largo de la vida de su fábrica y el conjunto de datos que logre de todas sus botellas se
llama población.
- Este puede ser tan grande como: espacio muestral= {0 l., 0.00000001 l., 0.0000023 l., 0.55647726 l., 1 l.,...}
- Las medidas de tendencia central son, como su nombre lo dice, aquellas que identifican el
comportamiento más común en la característica buscada y las tres más empleadas son la media (o
promedio), la mediana y la moda.
- La mediana: Es el valor de la observación que, una vez ordenada la población de la menor observación a
la mayor, que se encuentra exactamente a la mitad de la población.
Annotations:
- La condición necesaria para que exista la mediana es que, al establecerse la misma, se cuente el mismo número de observaciones arriba y debajo de la misma. Por ejemplo piense en la siguiente población de números: X ={1, 2,3, 4,5, 6, 7,8,9}
- Moda: Es el valor de evento muestral que presenta el mayor número de observaciones en la población
estudiada.
Annotations:
- Siguiendo el ejemplo de los 10 lanzamientos de dados, X ={1, 4, 2,3, 4, 4,5, 6} se observa que la moda sería el 4 ya que es el número que más veces aparece en la población
- 1.3.2 La varianza y la desviación estándar ¿qué significan? y ¿Por qué la calculamos la varianza
elevando al cuadrado las diferencias respecto a la media?
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de
aplicaciones. La misma simplemente se dedica a medir el tamaño promedio de separación que las
diferentes observaciones de la población tienen respecto a u media.
- Varianza: La separación promedio que tienen las observaciones de una población respecto a su media.
Annotations:
- La varianza simplemente determina la separación promedio. Es decir, el promedio de -0.11 l, 0.11 l y 0.02 l.
- Para dar una mayor idea, recuerde ahora el ejemplo de los dados y la población de posibles resultados:
Annotations:
- Cuando se calculan las diferencias de cada resultado respecto a la media o promedio de resultados, se puede observar que realmente existen diferentes separaciones del valor de cada observación respecto a la media. Sin embargo, como medida de dispersión, a usted no le interesa saber todas las diferencias sino su valor promedio. Es decir, el grado de separación medio.
- fórmula 2
- Aquí se puede usted llevar una mala sorpresa al ver que la suma da cero y, al calcular la diferencia
media, el cálculo nos dice que no existe separación alguna. Si se revisa la tabla
estudiada y los valores de las diferencias podrá observar que no. Para
calcular la varianza, simplemente se eleva al cuadrado las diferencias respecto a la media expuestas
en la columna derecha de la tabla anterior, se suman y se dividen entre el número de observaciones.
- Fórmula 3:
- Este número está un poco raro ya que a usted no le hace sentido elevar al cuadrado las diferencias. Sin
embargo, en la Matemática se pueden hacer cambios y trucos discrecionales sin que la realidad
cambie y esto que se realiza se trata de un mero “ajustito” matemático para que salgan las cuentas.
- Para ahorrarle la crisis existencial, una vez que se calcula la varianza, lo que muchas veces se hace (y
no será la excepción aquí) es simplemente calcular la raíz cuadrada de la varianza para obtener la
desviación estándar
- Para ahorrarle la crisis existencial, una vez que se calcula la varianza, lo que muchas veces se hace (y
no será la excepción aquí) es simplemente calcular la raíz cuadrada de la varianza para obtener la
desviación estándar
- Este número está un poco raro ya que a usted no le hace sentido elevar al cuadrado las diferencias. Sin
embargo, en la Matemática se pueden hacer cambios y trucos discrecionales sin que la realidad
cambie y esto que se realiza se trata de un mero “ajustito” matemático para que salgan las cuentas.
- Fórmula 4:
- “En el lanzamiento de un dado, el valor promedio de los seis posibles resultados (media) es de 3.5 el
cual tiene variaciones potenciales de ±1.70. Es decir, en promedio esperaríamos tener un 3.5 con
posibilidad de sacar al menos un 1.8 o un 5.2”
- “En el lanzamiento de un dado, el valor promedio de los seis posibles resultados (media) es de 3.5 el
cual tiene variaciones potenciales de ±1.70. Es decir, en promedio esperaríamos tener un 3.5 con
posibilidad de sacar al menos un 1.8 o un 5.2”
- El ejemplo del dado se presenta para ilustrarle a usted la forma de cálculo de media y desviación
estándar.
- algo más palpable, un corredor de bolsa. Este individuo quiere especular con el valor de una acción
de telecomunicaciones y desea saber qué precio tendrá la misma el día de mañana en tres
escenarios: uno factible, uno optimista y uno pesimista. Lo que este individuo realiza entonces es
obtener el una muestra del precio histórico de esa acción del último mes o últimos 30 días y calcular
el promedio con la fórmula 1 y la desviación estándar con las fórmulas 3 y luego la 4.
Annotations:
- con este ejemplo es que se logre entender que la media es el resultado promedio que podría esperar en un evento aleatorio, dada la población de observaciones y que la varianza o si prefiere la desviación estándar, que es más fácil de interpretar, miden simplemente el grado de separación promedio que todas las observaciones de la población tienen respecto a la media.
- En términos gráficos esto sería:
Annotations:
- Ya que se repasó lo que es la media, la varianza y la desviación estándar, es de necesidad observar lo siguiente: En la mayoría de los casos se utiliza la media como medida tendencia central y la desviación estándar para hacer análisis estadístico y esto, salvo en los casos que se exprese lo contrario, será aplicable en la materia.
- algo más palpable, un corredor de bolsa. Este individuo quiere especular con el valor de una acción
de telecomunicaciones y desea saber qué precio tendrá la misma el día de mañana en tres
escenarios: uno factible, uno optimista y uno pesimista. Lo que este individuo realiza entonces es
obtener el una muestra del precio histórico de esa acción del último mes o últimos 30 días y calcular
el promedio con la fórmula 1 y la desviación estándar con las fórmulas 3 y luego la 4.
- Aquí se puede usted llevar una mala sorpresa al ver que la suma da cero y, al calcular la diferencia
media, el cálculo nos dice que no existe separación alguna. Si se revisa la tabla
estudiada y los valores de las diferencias podrá observar que no. Para
calcular la varianza, simplemente se eleva al cuadrado las diferencias respecto a la media expuestas
en la columna derecha de la tabla anterior, se suman y se dividen entre el número de observaciones.
- 1.3.3 Reglas de dedo para calcular la media y la desviación estándar:
- Media:
Annotations:
- 1. Tome todas las observaciones de su población 2. Sume los valores numéricos de las observaciones. 3. Cuente el número de observaciones que tiene. 4. Divida la suma de valores numéricos de las observaciones entre el número de las mismas.
- Desviación estándar:
- Varianza:
Annotations:
- 1. Recuerde que debe calcularse la varianza para obtener este valor. Por tanto, debe calcularse primero la media. 2. A cada valor numérico de cada observación se le resta el valor de la media . Es decir, se calcula la diferencia entre cada valor numérico de cada observación respecto a la media. 3. Las diferencias calculadas anteriormente se elevan al cuadrado. 4. Se suman las diferencias calculadas. 5. Se divide esta suma entre el número de observaciones.
- Ahora sí, la Desviación estándar:
Annotations:
- 6. En los pasos A a F se calculó la varianza. Si usted quiere utilizarla, está bien pero es más recomendable utilizar la desviación estándar que se calcula simplemente sacando la raíz cuadrada de la varianza lograda en el paso F.
- Varianza:
- Media:
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de
aplicaciones. La misma simplemente se dedica a medir el tamaño promedio de separación que las
diferentes observaciones de la población tienen respecto a u media.
- Ahora recuerde usted el evento aleatorio de la línea de producción de botellas de agua previamente
mencionado. Usted no sabe ni sabrá con seguridad cuáles serán los posibles resultados del espacio
muestral del nivel de llenado de sus botellas.
- 1.4 Cálculo de probabilidades: los histogramas, las funciones y distribuciones
de probabilidad.
- 1.4.1 Mapa mental de lo hasta ahora visto
- 1.4.2 Eventos aleatorios (variables aleatorias) discretos y continuos
Annotations:
- Cuando la población de observaciones que se tiene es la de un experimento aleatorio sencillo como es el lanzamiento de una o dos monedas, el lanzamiento de uno o dos dados, los resultados de un juego de cartas o las calificaciones de un grupo de clase.
- Formula 1
Annotations:
- Sin embargo, en poblaciones grandes o eventos continuos , la forma de hacer esto es diferente. Antes de hablar de ello, es necesario saber qué es un evento aleatorio discreto o un evento discreto y qué es un evento continuo.
- Evento aleatorio discreto:
Annotations:
- Es aquel cuyo conjunto de posibles resultados o acontecimientos tienen una cantidad que se puede contar aunque sea esta muy grande.
- Ejemplo: dado revisado, el número de mujeres profesionistas de la contabilidad en la ciudad de
Morelia o el número de butacas rotas en la universidad. Estos tres ejemplos de poblaciones tienen
eventos que se pueden contar. Es decir son finitos.
- Evento aleatorio continuo:
Annotations:
- Es aquel cuyo conjunto de posibles resultados o acontecimientos tienen una cantidad que no se puede contar ya que esta es un número infinito.
- Ejemplo: los posibles valores que puede tomar la
temperatura en Morelia en cierto día. Puede tener valores como 10.51°, 10.53243°, etc. Otro ejemplo
serían los rendimientos diarios o por hora que puede tener el índice de la bolsa de valores. Dado que
los posibles resultados en estos eventos pueden ser prácticamente infinitos, se dice que estos
eventos son continuos.
- Evento aleatorio = Variable aleatoria (en Matemáticas)
- 1.4.3 Cálculo de probabilidades en variables aleatorias discretas: El histograma.
- Fórmula 1:
- Existen ocasiones en que las variables aleatorias arrojan observaciones que se repiten. Por ejemplo,
piense en el número de coches de cinco posibles colores: blanco, negro, rojo, azul y verde.
- Si cuenta todos los casos posibles en el estacionamiento de la universidad podrá tener resultados
como este:
- ejercicio:
Annotations:
- Dada una población total de 91 automóviles, usted se pone afuera de su aula o salón de clase y hace un juego con sus compañer@s consistente en adivinar de qué color será el próximo coche que entre al estacionamiento. ¿Qué color elegiría? Muy simple, dadas sus capacidades como estadístico que viene a aprender, simplemente calcula la probabilidad de cada uno de los colores aplicando la fórmula 1 en los valores de la tabla cuatro. Por ejemplo, existen 10 coches blancos en la universidad y, dividiendo esta cantidad entre el total de coches que es 91, se llega a una probabilidad de suceso de 10.99%.
Annotations:
- Si desea ganarle a sus amig@s simplemente dirá que el siguiente coche será o rojo o negro ya que son los dos casos que mayor probabilidad de suceso o de ocurrencia tienen.
- piense en un comerciante teórico que separa los aguacates de la siguiente manera: Pone los aguacates
que pesan de 50 gramos o menos en una caja, los de 51 a 101 en otra, los de 102 a 152 gramos en otra y
así sucesivamente hasta crear 10 grupos o intervalos de 50 gramos de rango que lleguen hasta los 500
g (vea tabla 6 para observar cómo quedaron los grupos o intervalos). Suponga que usted se encuentra
con el comerciante comprando aguacates y este le dice que le venderá en 78 pesos tres aguacates si le
permite a dicho comerciante elegir de manera aleatoria en las diez cajas. Ahora suponga que el
comerciante tiene un total de 1,000 aguacates en inventario repartido de la manera que se presenta en
el cuadro siguiente:
Annotations:
- Como se puede apreciar, la tabla anterior es muy parecida a la tabla 3 en donde se presenta la frecuencia del número de automóviles dado un color. Lo único que cambia aquí es que la clasificación no es en función de una cualidad como el color sino en función del peso que puede ser, como se dijo antes, una variable aleatoria continua. Por ejemplo, en el primer grupo o intervalo puede haber un aguacate de 48.5 g, otro de 30.5, otro de 49.98 y así sucesivamente en los 20 miembros de la caja o intervalo.
- Si usted desea saber qué rango de peso es más probable que resulte cuando el comerciante seleccione
el primero de 10 aguacates, simplemente repite el cálculo de la tabla 4 y divide el número de aguacates
que se encuentran en cada caja o intervalo entre el total que tiene el comerciante en inventario (1,000).
Por ejemplo, para el grupo o intervalo de aguacates que pesan de 153 a 203 gramos, la probabilidad de
que el comerciante le de una fruta de este grupo se daría por:
Annotations:
- La tabla 7 representa lo que se conoce como una tabla de frecuencias y la representación gráfica se da en la gráfica 2. Esta gráfica se conoce como histograma de frecuencias y se utiliza mucho en Estadística para analizar visualmente datos o en lo que más adelante conoceremos como Estadística no paramétrica. En esta es donde no se calculan parámetros como la media o la desviación estándar previamente revisados. Eso se deja para una discusión posterior.
Annotations:
- Los histogramas de frecuencias no son más que la representación gráfica de la tabla de frecuencias y nos dan una idea de cuáles son los valores con mayores probabilidades de ser observados.
- Una definición más formal se puede dar por:
- Histograma de frecuencias:
Annotations:
- Representación gráfica de una distribución de frecuencia de una variable aleatoria continua.
- Histograma de frecuencias:
- ejercicio:
- Si cuenta todos los casos posibles en el estacionamiento de la universidad podrá tener resultados
como este:
- 1.4.4 Distribuciones de probabilidad.
- En la definición de histograma se acaba de identificar un término que será fundamental en la
Estadística inferencial: La distribución de frecuencias. Esta no es más que la forma en que se
acomodan las diferentes frecuencias de suceso de los eventos aleatorios dado un intervalo dado.
- en la gráfica 2 cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés
para usted como contador, administrador o informático:
Annotations:
- “El proveedor del comerciante solo produce aguacates de peso alto ya que las mayores frecuencias se encuentran entre los 204 y los 407 gramos. Ya la mayor parte de los aguacates se distribuye en estas cajas o intervalos.
- Es entonces que llegamos a la distribución de probabilidad. Quizá esa línea toda quebrada nos dice
cosas muy parciales y es fácil intuir que los pesos más probables de encontrar en los 10 aguacates
que nos venda el comerciante sean entre 204 y 407 gramos. Pero ¿Qué pasa ahora si cambiamos un
poco las frecuencias o el inventario es un poco diferente? Vea usted la gráfica 5.
- Es entonces que llegamos a la distribución de probabilidad. Quizá esa línea toda quebrada nos dice
cosas muy parciales y es fácil intuir que los pesos más probables de encontrar en los 10 aguacates
que nos venda el comerciante sean entre 204 y 407 gramos. Pero ¿Qué pasa ahora si cambiamos un
poco las frecuencias o el inventario es un poco diferente? Vea usted la gráfica 5.
- en la gráfica 2 cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés
para usted como contador, administrador o informático:
- 1.4.5 Funciones de densidad de probabilidad
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de
la población y vemos que se debe seguir la siguiente receta:
Annotations:
- 1. Obtener todos los datos u observaciones de la población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que se acomode a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala entre el número de intervalos que desee calcular y con eso logra el rango:En donde V pob max representa el valor máximo de la población, V pob min el valor mínimo y el número de intervalos o grupos que desea calcular. 5. Clasifique todas las observaciones en cada uno de los n intervalos que creó con la fórmula 6. Cuente el número de observaciones en cada clasificación o intervalo. 7. Cuente el número total de observaciones. 8. Calcule la probabilidad de suceso que tiene cada intervalo al utilizar la fórmula 1 como sigue: 9. Ya que tiene estos valores, realice una gráfica como la 4 y con esto tendrá la distribución de probabilidad:
- Paso 8
- Paso 9 (Tabla 7)
- Estas formulitas simples se llaman funciones de densidad de probabilidad y existen muchas en la
Estadística. Sin embargo, en esta materia veremos solo cuatro de ellas por el uso práctico que se dará
en sus labores como profesionista:
Annotations:
- 1. La función de densidad de probabilidad “gaussiana” o “normal”. 2. La distribución t-Student. 3. La distribución Xi cuadrada. 4. La distribución F.
- Función de densidad de probabilidad:
Annotations:
- función matemática que nos sirve para calcular probabilidades de manera más simple que con los histogramas. Son más exactas y sirven para cuando tenemos muchos datos o los posibles valores de las observaciones pueden ser infinitamente diferentes.
- Función de densidad de probabilidad normal o gaussiana:
Annotations:
- Función de densidad de probabilidad que es la más utilizada y requiere de solo tres parámetros para su cálculo, el valor aleatorio al que se le determinará la probabilidad, la media y la desviación estándar.
- Para ilustrar la función de densidad gaussiana o normal, vea usted de nuevo la gráfica 4 del inventario
de aguacates, la cual se organiza con un histograma de frecuencias conformado de 10 grupos o
intervalos dados en la tabla 7:
Annotations:
- Si quisiéramos incrementar la precisión de nuestro cálculo de probabilidades, podríamos incrementar el número de intervalos de 10 a 20. Con esto, tendríamos la tabla de distribución de frecuencias y distribución de probabilidad dada en la tabla 8, así como la gráfica de distribución de probabilidad de la gráfica 6:
- Tabla 8, Grafica 6
- 1.4.5.1 Cálculo de probabilidades con función de densidad de probabilidad normal o gaussiana
- 1.4.6 La función de densidad de probabilidad normal estándar.
Annotations:
- Para continuar con el tema de probabilidades y la introducción de esta materia, hay que hacer una última abstracción y hablar de un tipo de función de densidad que es la misma que la gaussiana o la normal;solo que se presenta en otro “idioma” o forma de interpretación
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables
aleatorias que, por naturaleza o escala de medida, son diferentes
- Por tanto, lo que se hace es ajustar los datos del inventario de aguacates en las diferentes escalas a
valores que sean comparables al aplicar el siguiente ajuste o estandarización
Annotations:
- Para apreciar el efecto de la estandarización, véase el cambio de función de densidad de probabilidad del comerciante de aguacates mexicano
- Como puede apreciar en la gráfica 8, la media se convierte de un valor de 264 gramos a
un cero y todos los valores cambian de escala de -3 a 3. Es decir, pierden medidas de
unidad y se convierten en númerosreales comparables.
- Por ejemplo, suponga ahora que tanto la comerciante de Chicago como el comerciante de Morelia,
estandarizan su inventario de aguacates y comparan la función de densidad de probabilidad normal
estándar. Entonces podrían llegar a una gráfica como la siguiente:
- Una característica peculiar de los datos es que estos, en lugar de estar unos en gramos y otros en libras,
se miden en términos de desviaciones estándar o valores Zi y es entonces que los inventarios de
aguacates de los dos comerciantes pueden ser medidos con las mismas unidades para que los dos
puedan contestar la pregunta del problema que se plantearon
Annotations:
- Definir si la calidad del aguacate, medida por su peso, es la misma. De entrada, se puede ver que las distribuciones de probabilidad no son la misma. Si fueran la misma, estarían una sobre la otra. Este tipo de circunstancias son lo que da entrada a lo que en dos temas más por revisar se llama “comprobación de hipótesis”. En este caso, se busca comprobar la hipótesis de que los dos inventarios de los comerciantes tienen la misma calidad
- Para terminar de platicar sobre la distribución normal estándar, simplemente se describe cómo se
transformaron los datos o la distribución de probabilidad de los dos inventarios con medias y desviaciones
estándar en unidades diferentes (gramos y onzas) a unidades más similares como son “desviaciones
estándar” o valores i Z .
- Una característica peculiar de los datos es que estos, en lugar de estar unos en gramos y otros en libras,
se miden en términos de desviaciones estándar o valores Zi y es entonces que los inventarios de
aguacates de los dos comerciantes pueden ser medidos con las mismas unidades para que los dos
puedan contestar la pregunta del problema que se plantearon
- Por ejemplo, suponga ahora que tanto la comerciante de Chicago como el comerciante de Morelia,
estandarizan su inventario de aguacates y comparan la función de densidad de probabilidad normal
estándar. Entonces podrían llegar a una gráfica como la siguiente:
- Por tanto, lo que se hace es ajustar los datos del inventario de aguacates en las diferentes escalas a
valores que sean comparables al aplicar el siguiente ajuste o estandarización
- 1.4.6.1 Regla de dedo para comprender por qué utilizar una distribución normal estándar:
Annotations:
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las mismas o, peor aún, cuando no se tienen desviaciones estándar comparables, se debe utilizar ya no una función de densidad de probabilidad normal común y corriente; sino una estandarizada. 2. Para poder utilizar una distribución normal estándar, es necesario ya no utilizar los valores originales de nuestro inventario sino más bien hacer una operación que se conoce como “Estandarizar los valores de la variable”. 3. La estandarización de valoresse logra con la fórmula 6:
- Formula 6
- 1.4.7 El cálculo de la probabilidad utilizando la normal estándar y las tablas correspondientes.
Annotations:
- Ahora usted ha visto la principal función de densidad de probabilidad que se utiliza en la Estadística para ciencias administrativas: La distribución normal estándar. Ya que usted estandarice los valores de sus variables aleatorias, estará usted en capacidad de saber cómo se calculan probabilidades de eventos cuando se tienen solamente los datos de las observaciones de la población con que se trabaja al utilizar la distribución de probabilidad normal estánda
- Cuando tiene usted el valor estandarizado o Zi , simplemente se remite a la tabla como la citada en la
liga anterior y determina la probabilidad de suceso. Para dar un ejemplo de cómo hacer esto, piense
usted de nuevo en el ejemplo del nivel de llenado de las botellas de agua que se citó previamente.
Suponga ahora que el llenado medio de las últimas 2,000 botellas ha sido de μ=910 ml con una
desviación estándar de σ=75.3 ml. Conociendo estos dossimples datos, diga ahora usted ¿Cuál es la
probabilidad de que la siguiente botella que se tome aleatoriamente de la línea de producción tenga
un llenado de i x = 970 ml?
Annotations:
- Esto llevaría a observar que la probabilidad de tener un nivel de llenado de 970 ml es de 22.88%, la cual se puede representar como en la gráfica 11 en donde se relaciona ahora el punto del valor Zi del valor que se desea buscar con la función de densidad de probabilidad normal estándar
- 1.4.7.1 Diferentes formas de calcular una probabilidad. Los valores de probabilidad acumulada
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea saber
cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado específico de 970 ml. Sin
embargo, en la vida cotidiana, las probabilidades se determinan en base a intervalos de dato
- Esto implica que lo que en realidad nos está dando la tabla es la probabilidad de que la siguiente
botella de agua tenga un nivel de llenado de 910 ml a 970 ml. Esto es así ya que la
fórmula de cálculo de la función de densidad de probabilidad así lo pide
- Si deseamos conocer la probabilidad de tener valores iguales a 910 ml (μ) usted podrá observar en la
tabla que da una probabilidad de cero. Por tanto las probabilidades de la desviación normal estándar
trabajan con intervalos de valores y no con valores puntuales.
- or ejemplo, la probabilidad de tener niveles de llenado iguales o mayores que el nivel medio de μ=910
ml es de 50%. Esto se ilustra en la parte inferior de la gráfica 12. En la superior se expone el caso
contrario: El nivel de llenado es menor o igual a la media de 910 ml. Como se puede notar, el valor
total del área de la superficie sombreada tiene una magnitud de 50%. Es decir, la probabilidad de
tener ya sea valores mayores e iguales que la media o menores e iguales que la media.
- En base a lo previamente descrito, en la vida
cotidiana se pueden tener los siguientes casos de
cuantificación de probabilidades :
Annotations:
- 1. La probabilidad de que el valor del evento aleatorio sea menor o igual a b (por ejemplo que sea mayor o igual a 970 ml). 2. La probabilidad de que el valor del evento aleatorio sea mayor o igual a b por ejemplo que sea menor o igual a 970 ml). 3. La probabilidad de que el valor del evento se encuentre entre a y b (por ejemplo que el valor futuro se encuentre entre el valor medio de 910 ml y 970 ml)
- Para poder responder estas preguntas, primero observe la tabla de probabilidades que tiene a mano
y que bajó de la liga previamente mencionada páginas atrás. Usted podrá apreciar que solo le dan
los valores i Z positivos o a la derecha del cero
- ¿Qué pasaría ahora si lo que usted desea calcular es la probabilidad de tener un nivel de llenado de
850 ml partiendo de la misma media de μ=910 ml y σ=75.3 ml? Ahora usted tendría un valor i Z de:
- Para responder esto, es de necesidad observar que la probabilidad de tener eventos menores o iguales
a la media de la población o mayores o iguales a dicho valor siempre será, como se vio en la gráfica 12,
de 50% en la distribución normal estándar:
- ara resolver el problema ¿cuál es la probabilidad de que el nivel de llenado de la botella de agua sea
menor o igual a 970 ml? Se calcularía la probabilidad como sigue
Annotations:
- 1. Se sabe que el valor que se busca determinar como objetivo es mayor a la media. Por lo tanto, se tiene la probabilidad de que una variable aleatoria adopte valores menores o iguales la media que, de antemano por lo visto en la parte superior de la gráfica 12, se sabe es de 50%. O sea p X( ) 50% . 2. Se sabe, por el ejercicio previo, que la probabilidad de que la botella tenga un nivel entre la media (μ=910 ml) y 970 ml es de 22.88%. O sea p x ( ) 22.88% . 3. Por tanto, si se suman las probabilidades de tener un valor menor o igual a la media (μ) y el valor puntual de tener un llenado entre la media (μ=910 ml) y 970 ml, se llega entonces a una probabilidad total de:
Annotations:
- 1. Se sabe que el valor que se busca determinar como objetivo ( i x ) es menor a la media. Por lo tanto, se tiene la probabilidad de que una variable aleatoria adopte valores mayores o iguales la media que, de antemano, se conoce como de 50% por lo visto en la parte inferior de la gráfica 12. O sea p X( ) 50% 2. Se sabe, por el ejercicio previo, que la probabilidad de que la botella tenga un nivel puntual o específico de 850 ml es de 22.88%. O sea p x( ) 22.88% 3. Por tanto, si se suman las probabilidades de tener un valor mayor o igual a la media (μ) y el valor puntual de tener un llenado de 850 ml, se llega entonces a una probabilidad total de:
Annotations:
- 1. Se sabe, por el ejercicio previo, que la probabilidad de que la botella tenga un nivel puntual o específico de 970 ml es de 22.88%. O sea p x ( ) 22.88% . 2. Se sabe, por el ejercicio previo, que la probabilidad de que la botella tenga un nivel puntual o específico de 850 ml es de 22.88%. O sea p x( ) 22.88% i 3. Por tanto, se suman las dos probabilidades de suceso
- ara resolver el problema ¿cuál es la probabilidad de que el nivel de llenado de la botella de agua sea
menor o igual a 970 ml? Se calcularía la probabilidad como sigue
- Para responder esto, es de necesidad observar que la probabilidad de tener eventos menores o iguales
a la media de la población o mayores o iguales a dicho valor siempre será, como se vio en la gráfica 12,
de 50% en la distribución normal estándar:
- ¿Qué pasaría ahora si lo que usted desea calcular es la probabilidad de tener un nivel de llenado de
850 ml partiendo de la misma media de μ=910 ml y σ=75.3 ml? Ahora usted tendría un valor i Z de:
- En base a lo previamente descrito, en la vida
cotidiana se pueden tener los siguientes casos de
cuantificación de probabilidades :
- or ejemplo, la probabilidad de tener niveles de llenado iguales o mayores que el nivel medio de μ=910
ml es de 50%. Esto se ilustra en la parte inferior de la gráfica 12. En la superior se expone el caso
contrario: El nivel de llenado es menor o igual a la media de 910 ml. Como se puede notar, el valor
total del área de la superficie sombreada tiene una magnitud de 50%. Es decir, la probabilidad de
tener ya sea valores mayores e iguales que la media o menores e iguales que la media.
- Si deseamos conocer la probabilidad de tener valores iguales a 910 ml (μ) usted podrá observar en la
tabla que da una probabilidad de cero. Por tanto las probabilidades de la desviación normal estándar
trabajan con intervalos de valores y no con valores puntuales.
- Esto implica que lo que en realidad nos está dando la tabla es la probabilidad de que la siguiente
botella de agua tenga un nivel de llenado de 910 ml a 970 ml. Esto es así ya que la
fórmula de cálculo de la función de densidad de probabilidad así lo pide
- Como un último tipo de problema de cálculo de probabilidades que podría presentarse en su vida
cotidiana se tiene el siguiente ejemplo: Determine usted cuál es la probabilidad de que la siguiente
botella que tome de muestra tenga un nivel de llenado entre 940 y 960 ml. Como puede apreciar, los
dos valores buscados se encuentran arriba de la media. Por tanto, lo que debe calcular son los dos
valores Z de cada caso y luego restar las probabilidades. Esto es, siguiendo la tabla de
probabilidades dada:
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea saber
cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado específico de 970 ml. Sin
embargo, en la vida cotidiana, las probabilidades se determinan en base a intervalos de dato
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de
la población y vemos que se debe seguir la siguiente receta:
- En la definición de histograma se acaba de identificar un término que será fundamental en la
Estadística inferencial: La distribución de frecuencias. Esta no es más que la forma en que se
acomodan las diferentes frecuencias de suceso de los eventos aleatorios dado un intervalo dado.
- Fórmula 1:
- 1.4.1 Mapa mental de lo hasta ahora visto
- 1.3.1 La media, la mediana y la moda
- “El conjunto de técnicas de recolección, presentación y correcto análisis de información numérica
relacionada con facilitar la toma decisiones frente a situaciones de riesgo”.
- Para dar una idea de esta relevancia, piense
usted en la empresa Apple Inc.
- 2 Teoría del muestreo
Annotations:
- De entrada, es de necesidad observar que en todo lo revisado hasta ahora se ha supuesto que el conjunto de datos con que se trabaja son muestras. Sin embargo, en la realidad es difícil trabajar con poblaciones enteras sino, más bien, con muestras. Para ilustrar esto, se recuerda la definición de población:
- Población:
Annotations:
- Conjunto de todas las observaciones posibles sobre una característica de interés observada.
- Muestra
Annotations:
- Subconjunto de una población de la cual se deriva
- 2.1 Tipos de muestreo
Annotations:
- se explorarán las características relacionadas a la forma de hacer muestras. En el siguiente tema: la inferencia, se observará que el cálculo de parámetros como la media y la desviación estándar cambian en una muestra respecto a una població
- Una parte de importancia a observar es que una muestra, según el tipo de estudio que se haga, se
realiza de diferentes formas. Por ejemplo, la muestra de un grupo de aguacates en inventario o la que
se obtiene con las botellas de agua extraídas de una línea de producción se forma de manera diferente
a la que emplea una empresa de mercadotecnia para probar la demanda de un producto. Esta
diferencia radica en el uso que se dará a los datos. Por ejemplo, el tener que saber cuántas botellas de
agua no satisfacen los estándares de calidad es una aplicación diferente a saber ¿cuál es la demanda de
bebidas alcohólicas en el sector de clase media de una sociedad tanto en mujeres como en hombres?
- En virtud de esto, se tienen cuatro tipos de
muestreo o forma de hacer muestras comúnmente
utilizados
Annotations:
- 1. Muestreo aleatorio simple. 2. Muestreo sistemático. 3. Muestreo de racimo. 4. Muestreo estratificado
- En virtud de esto, se tienen cuatro tipos de
muestreo o forma de hacer muestras comúnmente
utilizados
- 2.2 Muestreo aleatorio simple
Annotations:
- consiste en seleccionar, de manera aleatoria, una serie de observaciones, objetos o datos de una población sin seguir algún tipo de agrupamiento específico. Un ejemplo simple, retomando el caso de los niveles de llenado de las botellas, sería ir una directamente de la línea de producción, luego dos y luego una y así sucesivamente hasta llegar a un número determinado de botellas u observaciones
- Ejemplo, 500.
Annotations:
- Otra forma de hacer muestras aleatorias sería, por ejemplo usted desea hacer una muestra de afiliados al seguro social y elige de manera aleatoria a estos en función de los últimos tres números de folio de afiliación. Para esto, usted utiliza un generador de números aleatorios, como el que tiene Excel y elije primero al usuario cuyo número de seguro social termina en 472, luego corre otro número y elije al usuario con número 589 y así sucesivamente hasta que tenga un número determinado de usuarios
- Este tipo de muestreo es el más común pero tiene la
limitante de que se elijen muestras aleatorias y algún tipo
de característica puede no ser tomada en cuenta
- 2.3 Muestreo sistemático
Annotations:
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos predeterminados. Por ejemplo, piense usted que tiene 2,000 cajas de aguacate foliadas todas y listas para empacarse a Estados Unidos. Ahora elige primero la caja número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una muestra de 100 cajas a las que le puede realizar el estudio estadístico que necesita.
- El muestreo sistemático es muy útil. Tiene una limitante llamada introducción de sesgo.
Para ilustrar la idea, se le da un ejemplo: Es dueño de una cadena de farmacias y
desea muestrear el nivel de ventas de sus sucursales en Morelia haciendo el muestreo solo los días
lunes. De entrada esto puede ser bueno y práctico. Puede tener la limitante de que el
patrón de consumo de sus clientes es bajo los días lunes ya que es inicio de semana y desean gastar
en otras cosas su dinero. Claramente, de hacer este tipo de muestreo, usted estaría estimando ventas
menores y correría el riesgo de tomar decisiones mal informadas.
- 2.4 Muestreo estratificado
Annotations:
- En este tipo de muestreo, se divide la población de datos en grupos homogéneos y se determina qué proporción representa cada estrato o grupo. Cuando se analizan las características y parámetros como media, desviación estándar, etc., se ponderan los mismos en función de su representación o proporción de peso respecto la población total y con esa ponderación se obtienen los parámetros y probabilidades totales de dicha población con este tipo de muestra.
- Por ejemplo, piense usted que desea saber el número medio de personas que entran a sus farmacias
en función de su edad. Por ejemplo, tendría usted una tabla como la siguiente:
- 2.5 Muestreo de racimo.
Annotations:
- Esta forma de muestrear se parece a la anterior, con la diferencia de que primero se hacen estratos y luego se seleccionan miembros, datos u observaciones de cada uno de los estratos de una manera aleatoria. Por ejemplo, usted desea saber cuántas televisiones existen en la ciudad de Morelia. Entonces, usted divide la ciudad en colonias y elige, de cada colonia y de manera aleatoria, una serie de casas, toca la puerta y pregunta el número de televisiones que hay en cada una. Con esto toma muestras aleatorias no de la totalidad de la población sino de cada uno de los grupos que usted formó.
- 2.6 Diferencias operativas en cada uno de los tipos de muestreo y determinación del empleado en Estadística
Inferencial.
- En el siguiente cuadro se destacan las principales
diferencias operativas o de ejecución de cada uno de los
tipos de muestreo estudiados
Annotations:
- De los 4 tipos de muestro vistos, el que se utilizará en Estadística inferencial es el aleatorio simple. La afirmación anterior surge del hecho de que los otros tres tipos no son más que técnicas específicas de recolección de datos que derivan en una muestra a la que se calcularán probabilidades muestrales y con los cuales usted, como profesionista tomador de decisiones, deberá realizar el análisis estadístico que requiera. En pocas palabras, los diferentes métodos de muestreo se aproximan al muestreo aleatorio
- 2.7 Diseño de un experimento: el proceso que se sigue para tomar
decisiones
Annotations:
- En Estadística aplicada a los negocios, es importante conducir de manera apropiada la toma de decisiones. Si usted a esta altura ya llevó una clase de Métodos de investigación o metodología de la investigación, recordará el método científico. Aunque éste último es más apropiado para la generación de conocimiento científico, la forma en cómo se llega a una conclusión y a la toma de decisiones en los negocios es muy similar
- El diseño de experimento o pasos del análisis estadístico a seguir son los siguientes
Annotations:
- 1. Definir el objetivo: Los comerciantes definieron como objetivo determinar que la calidad de sus inventarios es la misma. 2. Definir lo que se medirá: Aquí los comerciantes definieron “calidad” como el peso de sus aguacates. En pocas palabras pusieron una hipótesis dada por: “Si nuestros inventarios de aguacates tienen el mismo peso, comparten la misma calidad”. 3. Definir el tamaño de muestra: Aquí los comerciantes decidieron no trabajar con la totalidad de su inventario porque son miles de aguacates pero acordaron tomar una muestra de 200 aguacates. 4. Analizar los datos: Aquí se emplean técnicas estadísticas, como es la comprobación de hipótesis, para concluir si el objetivo planteado se cumple o no. Por ejemplo, los comerciantes determinaron, con técnicas estadísticas, que sus inventarios son iguales. 5. Conclusión y toma de decisiones: En este punto, en base al diseño del experimento seguido hasta ahora, se concluye que los inventarios tienen la misma calidad y toman la decisión de no reclamar al proveedor.
- A manera de síntesis de dedo, se presentan los pasos del diseño experimental o proceso de análisis
estadístico
Annotations:
- 1. Definir el objetivo. 2. Definir lo que se medirá. 3. Definir el tamaño de muestra. 4. Analizar los datos. 5. Conclusión y toma de decisiones.
- 2.8 Distribuciones de probabilidad muestrales
- ? Para responder esto imagine que tiene una población total de 5,000 aguacates con diferentes niveles de
peso en gramos. Esta población total tendrá una distribución de probabilidad determinada. Ahora, si se
extrae una muestra de 30 aguacates, esta tendrá un promedio y una desviación estándar y, a su vez una
distribución de probabilidad con una forma y valores determinados. SI se repite dos veces más el ejercicio de
muestreo, se verá que las medias, las desviaciones estándar y las distribuciones de probabilidad son
diferentes por lo que, si se está trabajando con una muestra, es muy probable que esta tenga fluctuaciones
en dicha media. Para ilustrar esto se tiene la siguiente gráfica:
Annotations:
- En la misma, se puede apreciar la diferencia en la forma de las distribuciones de probabilidad y las medias de las tres muestras generadas con el método de muestreo aleatorio simple (se tomaron 30 aguacates de manera aleatoria de un total de 5,000). Es decir, no son estables. Por lo tanto, el hacer un análisis estadístico con muestreo observando que tanto la media como la desviación estándar pueden ser diferentes de muestra en muestra, implica que se tiene incertidumbre o poca seguridad de tomar decisiones ya que la media y desviación estándar de la muestra no son la misma que la de la población
- Para dar mayor idea, suponga usted que se generan 1,000 muestras
diferentes de 30 aguacates cada una. El comportamiento de las medias y
distribuciones de probabilidad en cada caso se presentan en la gráfica 18.
- En la misma se aprecian todas las distribuciones de probabilidad
de las 1,000 muestras generadas con el método de muestreo
aleatorio simple. También se señala la distribución de
probabilidad poblacional.
- En la misma se aprecian todas las distribuciones de probabilidad
de las 1,000 muestras generadas con el método de muestreo
aleatorio simple. También se señala la distribución de
probabilidad poblacional.
- 2.8.1 Las estadísticas necesarias para calcular la distribución normal muestral
- Cuando usted trabaja con poblaciones, las medidas que son insumos necesarios para el cálculo de
probabilidades se llaman Parámetros. Es decir, si los datos que usted tiene para analizar son la media y la
desviación estándar. A estos dos se les denomina parámetros de su función de probabilidad
- Sin embargo, para una función de probabilidad cuando usted tiene muestras, los insumos son los mismos y se
llaman ahora estadísticas o medidas estadísticas. Y estas estadísticas son la media y el error estándar (recuerde
que así le llamamos a la desviación estándar cuando tenemos datos de muestras)
- Para afirmar la idea, se tiene el siguiente cuadro de resumen que el profesor espera le sea de utilidad para
memorizar
- Para afirmar la idea, se tiene el siguiente cuadro de resumen que el profesor espera le sea de utilidad para
memorizar
- Sin embargo, para una función de probabilidad cuando usted tiene muestras, los insumos son los mismos y se
llaman ahora estadísticas o medidas estadísticas. Y estas estadísticas son la media y el error estándar (recuerde
que así le llamamos a la desviación estándar cuando tenemos datos de muestras)
- 2.8.2 Media muestral
Annotations:
- Como puede apreciar, la función de probabilidad normal estándar sigue utilizándose. Lo único que cambian son la forma de calcular la media y la desviación estánda
Annotations:
- Para demostrar que la media poblacional puede aproximarse con la media de nuestra muestra observe usted de nuevo la parte superior e inferior de la gráfica 19 presentada de nuevo anteriormente. Note como, con 1,000 muestras, el promedio de cada una se acerca mucho a la media poblacional. Por tanto, si se hubieran corrido 10,000 muestras en lugar de 1,000, la aproximación hubiera sido mayor al grado de que la media de nuestra muestra y la poblacional prácticamente serían la misma. Por tanto, con este simple ejercicio mental, puede usted comprobar que es válido emplear la media de la muestra calculándola con la media convencional.
- 2.8.3 Error estándar
Annotations:
- Separación que la media de su muestra tiene respecto a la verdadera media de la población y este se aproxima muy bien al simplemente dividir la desviación estándar de su muestra entre la raíz cuadrada del número de observaciones que integran su muestra
Annotations:
- La diferencia entre la gráfica 21 y la 18 está en que la 21 se hicieron muestras aleatorias con diferente tamaño y en la 18 se hicieron muchas muestras con el mismo tamaño: 30 aguacates. La idea que se busca resaltar de la gráfica 21 es que, conforme aumenta el tamaño de la muestra, el error estándar9 se aproxima mucho a la desviación estándar de la población. Por tanto, la forma en que se calcula la desviación estándar en una muestra, mejor conocida como error estándar, se da ahora por la siguiente fórmula sí y solo si se conoce la desviación estándar de toda la población
Annotations:
- En un español más plano, lo que usted tiene que hacer para calcular el error estándar es simplemente calcular la desviación estándar () de su muestra y luego dividirla entre la raíz cuadrada de su número de datos ( n ). Esta fórmula se utilizará, de momento, como válida ya que se presupone que se conoce la desviación estándar de la población. Sin embargo, no siempre es así y en el siguiente tema se verá cómo se hace para calcular la desviación estándar de una muestra.
- 2.8.4 Cálculo de probabilidades con muestras
Annotations:
- Para calcular la probabilidad en una muestra se sigue utilizando la misma tabla de distribución normal estándar y se siguen los mismos métodos de cálculo previamente vistos. Lo único que cambia es la fórmula 6 a la que se le sustituye la desviación estándar por el error estándar
Annotations:
- Dicho lo anterior usted puede seguir los pasos para calcular probabilidades que se le presentan en la tabla 11 ya sea cuando emplea datos de una población o de una muestra. Como aprecia, solo cambia el cálculo del error estándar
Annotations:
- Para ilustrar todo esto con un ejemplo, piense que usted es el comerciante de aguacates de Morelia y que toma una muestra de 30 piezas que le lleva a un peso promedio de 150 g. y una desviación estándar de los datos de 80 g. Usted quiere determinar la probabilidad de que, si toma otro aguacate más, este tenga un peso menor o igual a 180 grs.
- Cuando usted trabaja con poblaciones, las medidas que son insumos necesarios para el cálculo de
probabilidades se llaman Parámetros. Es decir, si los datos que usted tiene para analizar son la media y la
desviación estándar. A estos dos se les denomina parámetros de su función de probabilidad
- 2.9 El teorema del límite central y una primera forma de determinar el tamaño adecuado de la muestra
Annotations:
- Hasta ahora se ha trabajado con el supuesto de que las variables aleatorias que se estudian están normalmente distribuidas. Sin embargo puede darse el caso de que esto no sea así. Cuando usted, con técnicas de las que se revisarán algunas en temas posteriores, detecta que los datos con que trabaja no están normalmente distribuidos, puede seguir manejando el supuesto de normalidad si incrementa el número de datos de su muestra
- Entonces, el Teorema del límite central dice que debe incrementarse el número de datos para poder
hacer que la muestra sea normal si esta no lo es. La siguiente pregunta que podría plantearse usted
sería ¿Qué tan grande debe ser mi muestra para darle validez al Teorema del Límite Central? La
mayoría de los estadísticos sugiere que debe cumplirse una de las siguientes condiciones para
considerar la muestra “grande”
Annotations:
- 1. Que el número de observaciones de la muestra sea mayor de 30. Esto es: n 30 2. O que el número de datos de su muestra tenga una proporción menor o igual al 5% de la población total.
- ejemplo
- si usted quiere determinar cuál es el tamaño apropiado de muestra para un análisis estadístico
aplicado el precio de una acción o la temperatura de Morelia, usted deberá elegir 30 o más datos para
considerar “grande” su muestra y darle validez al teorema del límite central. Casos como estos dos son
situaciones en las que usted desconoce el verdadero tamaño de la población total.
Annotations:
- En otras circunstancias usted podrá conocer o aproximar el tamaño total de su población. Por ejemplo la población de habitantes de México era de aproximadamente 110 millones de habitantes a finales del año 2011. Si usted fuese un director del INEGI y desea determinar el nivel de empleo de México, deberá encuestar, a lo mucho, a 5.5 millones de personas. Es decir, el 5% de 110 millones. Si usted entrevista a 7 millones, a pesar de ser muchos datos su muestra ya no se considerará grande. ¿Por qué la contradicción de pedir una muestra mayor de 30 o menor al 5% de la población conocida? Esa respuesta se la dejamos a los matemáticos. Sea suficiente para usted saber esto y aplicar la regla de dedo como se le presenta.
- Teorema del límite central:
Annotations:
- “Una muestra de datos que no tenga una distribución de probabilidad normal podrá suponerse que está normalmente distribuida si - su número de datos es mayor o igual a 30. - si se conoce el tamaño total de la población (y estas es muy grande), su número de datos es menor o igual al 5% de la población total…”
- si usted quiere determinar cuál es el tamaño apropiado de muestra para un análisis estadístico
aplicado el precio de una acción o la temperatura de Morelia, usted deberá elegir 30 o más datos para
considerar “grande” su muestra y darle validez al teorema del límite central. Casos como estos dos son
situaciones en las que usted desconoce el verdadero tamaño de la población total.
- Entonces, el Teorema del límite central dice que debe incrementarse el número de datos para poder
hacer que la muestra sea normal si esta no lo es. La siguiente pregunta que podría plantearse usted
sería ¿Qué tan grande debe ser mi muestra para darle validez al Teorema del Límite Central? La
mayoría de los estadísticos sugiere que debe cumplirse una de las siguientes condiciones para
considerar la muestra “grande”
- 2.10El multiplicador de población finita
Annotations:
- Para finalizar la revisión de la Teoría del muestreo que contempla este segundo tema del curso de Estadística II. Es de interés observar algo más del cálculo del error estándar
- íneas atrás se le observó que, cuando se trabaja con muestras, no se utiliza la desviación estándar sino
el error estándar y que este se calcula simplemente al dividir la desviación estándar de su muestra
entre la raíz cuadrada del número de observaciones en la misma:
Annotations:
- Este cálculo es el que casi siempre se utilizará. Esto es así porque muchos fenómenos que estudiamos en las Ciencias Administrativas tienen poblaciones cuyos tamaños desconocemos. Es decir, son poblaciones infinitas
- Ejemplos
Annotations:
- de esto son el nivel de llenado de las botellas de agua que produce, la temperatura de Morelia, los precios de una acción, el inventario que tuvo, tiene y tendrá de aguacates, etc. Sin embargo, habrá casos en los que usted conozca muy bien el tamaño de su población y tenga que verse en la necesidad de hacer un muestreo dado lo costoso que le resulta sacar datos del total de su población. Un ejemplo puede ser un estudio de mercado como el que hizo Steve Jobs. Por ejemplo, él sabía cuántos arquitectos había en Estados Unidos. Por tanto, tuvo que hacer un ajuste adicional al error estándar para poder calcularlo bien y determinar la distribución de probabilidad:
Annotations:
- Cuando usted desee levantar una encuesta de ambiente laboral en su empresa, usted conoce de antemano el número de empleados en su nómina ( N ). Como usted posee o trabaja en una empresa con, digamos, 12 mil empleados, le resulta difícil procesar mucha información, por lo que podría hacer un tipo de muestreo (digamos estratificado o aleatorio simple) y se acerca a 60 empleados diferentes a realizarle la encuesta
- Como puede ver, su muestra es igual al 5% del total de empleados por lo que es de tamaño grande. Al
error estándar debería aplicarle, siempre que conozca el tamaño de la población, la siguiente
multiplicación:
- OTA: Si usted no conoce el tamaño total de la población o esta tiene un número infitino de datos
(como la temperatura o el precio de una acción), no deberá aplicar el multiplicador de la población
finita sino simplemente determinar el error estándar como sigue:
- Retomando el ejemplo de la encuesta a los empleados de su empresa, suponga que les hace una
simple pregunta: Del 1 al 10, con 1 muy bajo y 10 muy alto, diga usted si se siente contento en esta
empresa. Después de mandar por correo electrónico la pregunta a 60 personas, usted observa que la
calificación media de felicidad en la empresa es de μ=7.8 con una desviación estándar en la muestra
de σ=1.2. Entonces, el error muestral de esta encuesta para la totalidad de su empresa sería de:
- ? Para responder esto imagine que tiene una población total de 5,000 aguacates con diferentes niveles de
peso en gramos. Esta población total tendrá una distribución de probabilidad determinada. Ahora, si se
extrae una muestra de 30 aguacates, esta tendrá un promedio y una desviación estándar y, a su vez una
distribución de probabilidad con una forma y valores determinados. SI se repite dos veces más el ejercicio de
muestreo, se verá que las medias, las desviaciones estándar y las distribuciones de probabilidad son
diferentes por lo que, si se está trabajando con una muestra, es muy probable que esta tenga fluctuaciones
en dicha media. Para ilustrar esto se tiene la siguiente gráfica:
- En el siguiente cuadro se destacan las principales
diferencias operativas o de ejecución de cada uno de los
tipos de muestreo estudiados
- 3 Estimaciones puntuales y de intervalo. La base de la inferencia estadística
Annotations:
- En el tema anterior se introdujo el concepto de que la media muestral puede ser diferente respecto a la poblacional e incluso entre muestras. Eso llevó a observar como momentáneamente válida la aproximación de dicha media poblacional a través de la media de la muestra con que se trabaja x . Sin embargo, sigue presente el efecto de la incertidumbre que se genera al ver fluctuar x . Aquí es donde las estimaciones puntuales y de intervalo cobran vida como conceptos.
- Estimaciones puntuales
Annotations:
- Es un solo número que se utiliza para estimar un parámetro de la población: la media poblacional.
- La forma más común de obtener este tipo de estimación puntual es simplemente utilizar la media
muestral x . Sin embargo, el utilizar x está sujeto a cometer errores de muestra por lo que es más
apropiado hacer afirmaciones o estimaciones del tipo: El día de mañana a las 12:00 la temperatura
podría estar entre 20° y 21° o el nivel de llenado de la botella puede estar entre 996 l y 997l.Este tipo de
afirmación se conoce como estimación de intervalo.
- Estimación de intervalo
Annotations:
- Es un rango de valores que se utiliza para estimar un parámetro de la población
- Para dar una idea más clara de una estimación puntual y de una de intervalo se retoma el ejemplo del
inventario de aguacates del comerciante de Morelia, se generan 30 muestras aleatorias con 30
aguacates cada una y se llega a la siguiente gráfica:
- 3.1 Consideraciones para calcular verdaderas estimaciones de intervalo
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x ,y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se exponen
las 30 muestras aleatorias en comparación a la media poblacional.
- 3.1.1 El verdadero cálculo del error muestral cuando se desconoce la desviación estándar de la
población.
- algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la desviación
estándar de la población y en realidad lo que se está calculando la de una muestra. En el caso de
muestras, lo que debe de hacerse es hacer un pequeño ajuste para calcular la desviación estándar
muestral que ahora se denota como
- 3.1.2 La estimación de intervalo.
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que reconoce que este valor puede
cambiar de muestra en muestra y que tiene el cálculo del error estándar de la muestra calculado con la
fórmula 11, procederá usted a hacer una afirmación de este tipo: “El precio de la acción se estima que
sea de $26.4666 y, con un 95% de confianza, se espera que ese valor oscile entre $26.6533 y $28.2802.” Si
usted observa la gráfica 26, quizá no le sea muy preciso el pronóstico en el sentido de que el precio
esperado y su intervalo están muy abajo. Con el análisis de regresión podremos mejorar la precisión.
Baste con suponer, de momento, que la media muestral es buen pronóstico del valor futuro.
- ¿Cómo se hicieron este tipo de estimaciones?, ¿Cómo fue que se llegó a ese 95% de probabilidad para
definir un nivel de confianza (como el de 95% que se dio en la estimación) es necesario observar de
nuevo la gráfica 25 y recordar la Gráfica 25:
- Gráfica 10
- ¿Cómo se hicieron este tipo de estimaciones?, ¿Cómo fue que se llegó a ese 95% de probabilidad para
definir un nivel de confianza (como el de 95% que se dio en la estimación) es necesario observar de
nuevo la gráfica 25 y recordar la Gráfica 25:
- ¿Qué pasos debe usted seguir para lograr esto? Simple, lo hace usted al revés con la probabilidad.
¿Cómo es eso?
Annotations:
- 1. Saque su muestra. ¿Cómo? Utilice el método, de los previamente vistos, que mejor se acomode a sus objetivos. Defina el tamaño de muestra de tal forma que esté distribuida normal o gaussianamente o al menos aproxime esta función de probabilidad. Si se trata de datos infinitos de como son la temperatura o el precio de una acción, simplemente apele al teorema del límite central y defina una muestra mayor o igual a 30. 3. De los datos que tiene calcule la media muestral 4. Con esta media muestral calcule el error estándar. Si, como el caso de la temperatura o el precio de una acción, no conoce el tamaño total de la población de datos 5. Determine el nivel o intervalo de confianza que desea darle a sus estimaciones. Para fines del ejemplo que llevamos, piense en un 95% (usted puede elegir el que quiera de 0% a 100%). 6. Ahora haga la operación inversa en las tablas de probabilidad normal estándar. Primero reste a 95% el 50% ya que usted busca un solo valor Z a la derecha de la media. Es decir arriba de 0 i Z en la tabla. Esto le llevará a 45%. 7. Ahora busque en la tabla ¿qué valor tiene una probabilidad de 45%? 8. Ahora que tiene x , simplemente calcula sus límites superior e inferior donde cree que fluctuará, con ese 95% de confianza, su estimación puntual dada por X 9. Ahora sí puede ya hacer la afirmación que busca: el peso promedio del inventario de aguacates de mi empresa sea de 153.0547g y qu este fluctúe, con un 95% de confianza, entre 54.4644g y 247.6449g”
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que reconoce que este valor puede
cambiar de muestra en muestra y que tiene el cálculo del error estándar de la muestra calculado con la
fórmula 11, procederá usted a hacer una afirmación de este tipo: “El precio de la acción se estima que
sea de $26.4666 y, con un 95% de confianza, se espera que ese valor oscile entre $26.6533 y $28.2802.” Si
usted observa la gráfica 26, quizá no le sea muy preciso el pronóstico en el sentido de que el precio
esperado y su intervalo están muy abajo. Con el análisis de regresión podremos mejorar la precisión.
Baste con suponer, de momento, que la media muestral es buen pronóstico del valor futuro.
- algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la desviación
estándar de la población y en realidad lo que se está calculando la de una muestra. En el caso de
muestras, lo que debe de hacerse es hacer un pequeño ajuste para calcular la desviación estándar
muestral que ahora se denota como
- 3.2 ¿Qué pasa cuando nuestra muestra de datos no es grande? La
distribución t-Student
- Hasta ahora se ha trabajado con el supuesto de que los datos están
normalmente distribuidos ya sea porque así nos conviene o porque hemos trabajado con muestras con más de 30
datos, situación que satisface el Teorema del Límite Central previamente revisado
Annotations:
- Sin embargo, no siempre se tiene la posibilidad de tener muestras de 30 datos sino más pequeñas. Un ejemplo muy claro puede estar en la contabilidad de una empresa. Suponga que usted desea hacer un análisis estadístico y calcular la distribución de probabilidad del ROI11 y que solo tiene 12 trimestres de información. Claramente la distribución normal estándar no es de utilidad porque viola el Teorema del límite central. ¿Qué se hace entonces? ¿Qué función de probabilidad se puede utilizar?
- Hay un tipo de función de probabilidad, de los cuatro que revisaremos en el curso, que sirve para este
fin. Esta se llama distribución t-Student o simplemente distribución t.
Annotations:
- Esta distribución fue propuesta por W.S. Gosset quien era un trabajador de la cervecería Guinness en Dublín. El hombre era un aficionado a la Estadística y, como la cervecería prohibía a sus empleados hacer publicaciones científicas y académicas, Gosset utilizó el pseudónimo de “Student” para poder publicar su artículo y hacer su gran aportación a la Estadística
- Antes de hablar de los tres parámetros (uno más respecto a la normal) que se necesitan para calcular la
distribución t-Student imagine usted que tiene tres muestras con la misma media
Annotations:
- 1. Una con más de 30 datos a la que le podemos calcular la probabilidad normal. 2. Una con solo 5 datos que se le calcula una función de probabilidad t-Student. 3. Una con 20 datos que también se le calcula una función de probabilidad t-Student.
Annotations:
- No siempre se tienen muestras con una cantidad de datos u observaciones mayor o igual a 30. Cuando esto sucede, los datos no están normalmente distribuidos pero se pueden hacer estimaciones de intervalo utilizando la distribución t-Student
- 3.2.1 Los parámetros para calcular la distribución t-Student y su empleo para el cálculo de estimaciones de
intervalo
Annotations:
- Se ha visto previamente que la distribución normal, a parte del valor de la variable aleatoria i x , necesita solo dos simples parámetros o estadísticas12 que son la media y la desviación estándar. Para el caso de la distribución t-Student se siguen utilizando estos dos más uno llamado Grados de libertad (denotado como GL o ).
- Grados de libertad
Annotations:
- Número de valores de una muestra que podemos especificar libremente, una vez que se sabe la media de la muestra.
- Para dar una idea de los grados de libertad, suponga usted que tiene una muestra de solo dos datos que le lleva a
un promedio o media muestral de 3.5:
- Si usted libremente elige el número 6, observará que el siguiente número necesario para llegar a un promedio
de 3.5 es 6:
- De estos dos datos que conforman su muestra, uno de ellos lo especificó libremente y el otro es un valor
forzado que debe cumplir con el promedio. Por tanto, la forma en que determinamos los grados de
libertadaquí y en cualquier muestra de cualquier tamaño se daría por:
Annotations:
- Función de densidad de probabilidad t-Student: Función de densidad de probabilidad que es la más utilizada y requiere de solo cuatro parámetros para su cálculo, el valor aleatorio ( i x ) al que se le determinará la probabilidad, la media , la desviación estándar y los grados de libertad. A diferencia de la normal o normal estándar, se emplea cuando nuestra muestra tiene menos de 30 datos
- Para calcular estimaciones puntuales y de intervalo suponga el siguiente caso del ejemplo del
inventario de aguacates: El comerciante decide hacer una muestra más pequeña de solo 15
aguacates. Esto es así porque el resto del inventario ya los tiene empacados
y listos para mandarlos a la central de abastos. Por tanto, le quedaron solo esos 12 aguacates. En
base a estos quiere determinar ¿qué calidad, medida en peso, tendrá el siguiente inventario que le
remita su proveedor? Para ello cuenta con los siguientes pesos en su muestra:
Annotations:
- De estos pesos, calcula la media muestral, la desviación estándar de su muestra con la fórmula 11 y el correspondiente error estándar con la fórmula 8. Posteriormente, lo que se hace es determinar el valor t. Para ello, el comerciante decide dar un 95% de confianza a sus estimaciones. A diferencia del cálculo de intervalos con la probabilidad normal estándar en donde utilizamos una tabla de valores Z dada la probabilidad (tabla 2), se utilizará la tabla 4 correspondiente a los valores t dada la probabilidad. La diferencia aquí, respecto a la de valores Z (tabla 3), es que no se le da la probabilidad de suceso sino que tiene que buscar algo llamado nivel de significancia (denotado con una α) que no es más que el resultado de restar a 100% probabilidad el intervalo de confianza dado:
Annotations:
- En el caso del comerciante de aguacates que emplea un intervalo de confianza de 95%, se llega a un nivel de significancia de α=5% o α=0.05. Con los grados de libertad (11) y este nivel de significancia se busca el valor en tablas que es de 2.200985:
- Ya que se tienen todos estos datos, el
aguacatero puede hacer las siguientes
estimaciones tanto puntuales como de intervalo
- Para calcular estimaciones puntuales y de intervalo suponga el siguiente caso del ejemplo del
inventario de aguacates: El comerciante decide hacer una muestra más pequeña de solo 15
aguacates. Esto es así porque el resto del inventario ya los tiene empacados
y listos para mandarlos a la central de abastos. Por tanto, le quedaron solo esos 12 aguacates. En
base a estos quiere determinar ¿qué calidad, medida en peso, tendrá el siguiente inventario que le
remita su proveedor? Para ello cuenta con los siguientes pesos en su muestra:
- De estos dos datos que conforman su muestra, uno de ellos lo especificó libremente y el otro es un valor
forzado que debe cumplir con el promedio. Por tanto, la forma en que determinamos los grados de
libertadaquí y en cualquier muestra de cualquier tamaño se daría por:
- Si usted libremente elige el número 6, observará que el siguiente número necesario para llegar a un promedio
de 3.5 es 6:
- 3.3 Estimaciones de intervalo para comparar medias
- 3.3.1 Estimaciones de intervalo para muestras apareadas grandes y pequeñas
- 3.3.1.1 Estimación de intervalo para muestras apareadas grandes
Annotations:
- el Teorema del Límite central, se puede considera una muestra como “grande” si tiene más de 30 observaciones e incluso se puede suponer que está distribuida si el tamaño de dicha muestra es menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se tienen 4 grupos de 20 individuos que dan un total de 80 diferencias o diferencias de calificaciones entre computadoras ( Di ). Por tanto, se puede aceptar el supuesto de que es muestra grande y de que está normalmente distribuida.
- Recordando los comentarios iniciales del muestreo de racimo, se observó que este consiste en
separar una población en diferentes grupos de interés y luego tomar una muestra de cada
segmento, estrato o grupo de interés para tomar una muestra aleatoria de cada uno.De entrada
separó su población objetivo en cuatro grupos o estratos de interés:
Annotations:
- 1. Arquitectos ingenieros, matemáticos, físicos, investigadores y profesionistas que ocupen procesamiento de cálculo. 2. Diseñadores gráficos, artistas de medios, músicos y gente que ocupe procesamiento gráfico. 3. Amas de casa, estudiantes y gente mayor. 4. Contadores, abogados, economistas, financieros y otros profesionistas.
- De cada uno de ellos seleccionó y entrevistó a 20 individuos, a los que les aplicó un cuestionario con
una serie de preguntas sobre capacidad de procesamiento, facilidad de manejo, costo y calidad. Para
esto, el Sr. Jobs les prestó a cada individuo tanto una Macbook como una PC de alta potencia durante
un periodo de tiempo y luego les aplicó el cuestionario. Las calificaciones que arroja el mismo iban de 0
para una mala calificación de calidad, precio y procesamiento, es decir, una preferencia muy baja,
hasta un 10 que es el nivel máximo de preferencia que pueden tener por la computadora
- Los resultados de cada uno de los 20 individuos de los cuatro grupos se presenta en la página siguiente
en la tabla 12. Para iniciar, en cada individuo, se calcula la diferencia ( D ) entre la calificación dada a la
PC o a la Macbook en cada indviduo de cada estrato. Esta se calculó simplemente como:
Annotations:
- Como se verá, la forma de calcular estimaciones de intervalo puede aplicarse a muestras apareadas, cuyas variables tienen una influencia entre sí o a muestras que no tienen relación alguna. Es decir, son independientes.
- ¿Cuál sería el criterio para que el Sr. Jobs demostrara la preferencia que tiene su computadora
respecto a la competencia? Simplemente que la diferencia de calificaciones entre la Mac y la PC fuera
superior
- Recuerde usted que se está trabajando con muestras generadas por racimo. Entonces debe usted
calcular primero la media de las diferencias en cada estrato ( D ) y el error estándar (D ). Debajo de la
tabla de las muestras de los 4 estratos se ponen dichos valores. Lo que procede, al igual que el
muestreo estratificado, es a ponderar el peso que dichas estadísticas tienen en cada estrato. Como las
muestras son iguales, se les da una ponderación de ¼=25%. Por tanto, la media y el error estándar de
la diferencia de toda la muestra tomada se calcula como:
- Suponga ahora que el Sr. Jobs quiere hacer ahora estimaciones de los datos y hacer una campaña
publicitaria para afirmar que su computadora es más preferida que la de la competencia. Para poder
hacerla, debe hacer las estimaciones tanto puntual como de intervalo y, para ello, decidió que se
utilizara un nivel de confianza de 95%.
Annotations:
- Dado este nivel de confianza, se observa, como en la ilustración 2, que el valor Z que corresponde a dicha probabilidad o confianza es de 1.6449 i z . Por tanto, las estimaciones del Sr. Jobs quedarían como sigue:
Annotations:
- Con estas estimaciones, el Sr. Jobs podría hacer la siguiente afirmación: “La calificación de preferencia una Mac respecto a una PC será superior en el mercado en 1.6802 puntos y esta puede fluctuar como máximo y mínimo, con un nivel de confianza de 95%, entre 2.9122 y 0.4482”
- Suponga ahora que el Sr. Jobs quiere hacer ahora estimaciones de los datos y hacer una campaña
publicitaria para afirmar que su computadora es más preferida que la de la competencia. Para poder
hacerla, debe hacer las estimaciones tanto puntual como de intervalo y, para ello, decidió que se
utilizara un nivel de confianza de 95%.
- Recuerde usted que se está trabajando con muestras generadas por racimo. Entonces debe usted
calcular primero la media de las diferencias en cada estrato ( D ) y el error estándar (D ). Debajo de la
tabla de las muestras de los 4 estratos se ponen dichos valores. Lo que procede, al igual que el
muestreo estratificado, es a ponderar el peso que dichas estadísticas tienen en cada estrato. Como las
muestras son iguales, se les da una ponderación de ¼=25%. Por tanto, la media y el error estándar de
la diferencia de toda la muestra tomada se calcula como:
- ¿Cuál sería el criterio para que el Sr. Jobs demostrara la preferencia que tiene su computadora
respecto a la competencia? Simplemente que la diferencia de calificaciones entre la Mac y la PC fuera
superior
- Los resultados de cada uno de los 20 individuos de los cuatro grupos se presenta en la página siguiente
en la tabla 12. Para iniciar, en cada individuo, se calcula la diferencia ( D ) entre la calificación dada a la
PC o a la Macbook en cada indviduo de cada estrato. Esta se calculó simplemente como:
- 3.3.1.2 Estimación de intervalo para muestras apareadas pequeñas
Annotations:
- Como se vio previamente para trabajar con estimaciones de muestra pequeñas, las fórmulas de cálculo del límite superior e inferior de la estimación de intervalo siguen siendo los mismos. Lo único que cambiaba en la fórmula es el valor i Z por el valor i t en la fórmula 18:
Annotations:
- Para simplificar el ejemplo del Sr. Jobs, supongamos que los datos de la tabla 12, no son muestra grande sino pequeña y, para esto suponga que los valores de D y D de dicha tabla son de una muestra de solo 26 observaciones. Por tanto, si el número de observaciones es de 26, los grados de libertad son 25. Por tanto, al buscar en la tabla t para un nivel de significancia de 5% (el inverso de un nivel de confianza de 95%) con 25 grados de libertad, se llega a un valor 2.0595
Annotations:
- Hasta ahora se han hecho estimaciones de intervalo de diferencias entre muestras apareadas grandes y pequeñas que se suponen tienen algún grado de dependencia. Sin embargo, en algunas ocasiones, esto no siempre es así. Ahora veamos el caso de estimaciones de intervalo de diferencias cuando las muestras son independientes
- 3.3.2 Estimaciones de intervalo para muestras ind
Annotations:
- Para poder calcular las estimaciones de intervalo de diferencias de muestras independientes, lo único que debe cambiar es la forma de calcular tanto la media de las diferencias como el error estándar de las mismas. Esto es:
- Es decir, para calcular la media de las diferencias ( D) en el caso de muestras independientes no se
tiene que seguir un primer paso de calcular una diferencia de observaciones y luego calcularle la
media a dichas diferencias. Lo que se hace es calcular la media de las observaciones de cada muestra
y luego restarlas como en la fórmula 20.
Annotations:
- Para el caso del error estándar (D ), simplemente se dividen las varianzas de muestras grandes o pequeñas, según sea el caso, entre la raíz del número de observaciones, se suma ese resultado en cada caso y luego se saca la raíz cuadrada como en la fórmula 21.
Annotations:
- Para ilustrar con un ejemplo, salgamos del ejemplo del Sr. Jobs (porque hemos dicho que sus muestras no son independientes) y ahora pasemos de nuevo con el ejemplo de los dos comerciantes de aguacate: La empresaria de Chicago y el de Morelia. Este ejemplo se presenta en la tabla 15 de la página anterior.
- Con esto se cierra el tema de la Teoría del Muestreo. Antes de proceder a un tema muy importante y
sencillo (una vez que se domina esto) es necesario responder dos preguntas que quedaron sueltas:
Annotations:
- 1. Se ha dicho que las estimaciones de intervalo tienen un grado de confianza de X%. ¿cómo se determina el mismo? Ya que, si incrementamos el grado de confianza o lo reducimos, podemos manipular las cifras de nuestras estimaciones. 2. Se ha hablado de muestras grandes y muestras pequeñas y se sugiere que el tamaño apropiado es que n≥30 para que los datos se acepte el supuesto de que los datos distribuyan normalmente. ¿Hay otra forma de determinar el tamaño óptimo de la muestra? 3. Hasta ahora se está trabajando con muestras “bien portadas”. Es decir que no se da la presencia de lo que se conoce como datos atípicos. Estos ¿qué son? Datos cuyo valor se sale notablemente del resto. Por ejemplo, un aguacate de medio kilo en el ejemplo de los aguacateros.
- Es decir, para calcular la media de las diferencias ( D) en el caso de muestras independientes no se
tiene que seguir un primer paso de calcular una diferencia de observaciones y luego calcularle la
media a dichas diferencias. Lo que se hace es calcular la media de las observaciones de cada muestra
y luego restarlas como en la fórmula 20.
- 3.3.1.1 Estimación de intervalo para muestras apareadas grandes
- 3.4 ¿Cómo determinar el intervalo de confianza?
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el nivel de confianza que se imprimirá a las
estimaciones de intervalo. Sin embargo, estas salen de la óptica y grado de exigencia del curso ya que en el mismo se
le enseñará a dominar las principales técnicas estadísticas de utilidad para su vida profesional. Si usted desea
profundizar en esto, puede cursar una maestría en administración o una en finanzas que logre ese grado de
profundización o puede consultar fuentes más avanzadas en Econometría o análisis de datos multivariante
- 3.5 ¿Cómo determinar el tamaño de muestra cuando se busca incrementar la precisión del intervalo de
confianza?
Annotations:
- para finalizar el tema de la Teoría del muestreo es necesario completar un poco más una pregunta que se planteó previamente ¿Qué tan grande debe ser la muestra para tener un estudio estadístico adecuado? Esta pregunta se respondió en una primera instancia con el Teorema del límite central que sugiere que la muestra sea mayor o igual a 30 observaciones para poder suponer que los datos se distribuyen normalmente. Sin embargo, el mismo se aplica cuando la población de datos del fenómeno en estudio es muy grande y, por ende, se desconoce el verdadero valor de la desviación estándar poblacional
- Cuando se logra que la media muestral sea igual o muy próxima a la de la población, se dice que la muestra es
insesgada. Cuando la media muestral es mayor que la poblacional, se dice que tiene sesgo positivo y, cuando
sucede lo contrario, tienen sesgo negativo. Cuando se logra que el error estándar sea igual o aproximado a la
desviación estándar de la población, se dice que la muestra es eficiente.
Annotations:
- Por tanto, si no quiere utilizar el Teorema del límite central, conoce ahora el valor de la desviación estándar poblacional y desea ahorrar costos para no hacer muestras demasiado grandes, podría preguntarse
- Para ilustrar un caso similar, regresemos con los comerciantes de aguacates. Hablemos de nuevo de la
empresaria de Chicago. Suponga que existen estadísticas dadas por APEAM (Asociación de Productores y
Empacadores de Aguacate de Michoacán) en las que determinan, el peso promedio y la desviación estándar de
los pesos de las frutas producidas durante muchos años. Dada la naturaleza de los datos, podríamos decir, para
fines de nuestro ejemplo, que todos los datos procesados son de una población. Esta población tiene una
desviación estándar de 250.15g
Annotations:
- Si ella tiene una muestra de 12 aguacates, con una media muestral de 141.0029 g y un error estándar de 12.4640 g, éste tendría una estimación de intervalo de 168.4361 g y 113.5697 g. Ese intervalo tiene un rango de 54.8663 g y, tal vez, usted lo considere demasiado grande. Quizá usted quiera saber: con el mismo 95% de confianza
- Si definimos el grado de fluctuación o error tolerable como e g 10 , se llega entonces a la siguiente fórmula
para determinar el tamaño óptimo de la muestra cuando se conoce la desviación estándar de la población y se
busca dar un intervalo de confianza de x% (ejemplo 95%)
Annotations:
- Es decir, que si quiere, con un 95% de confianza hacer estimaciones cuya precisión de estimación de intervalo solo se aleje ±100 g de la puntual., debe tener una muestra de 271 aguacates. Es decir, si quiere que su muestra sea confiable, esta debe cumplir que su media muestral sea cercana a la poblacional (no esté sesgada) y que el error estándar sea muy aproximado o igual a la desviación estándar de la población (sea eficiente). Si se permite una lejanía de ±100 g de la media poblacional, se debe incrementar la precisión de la muestra al incrementar el número de datos. Y la cantidad apropiada de aguacates dentro de la muestra, deberá ser de 271
- Si definimos el grado de fluctuación o error tolerable como e g 10 , se llega entonces a la siguiente fórmula
para determinar el tamaño óptimo de la muestra cuando se conoce la desviación estándar de la población y se
busca dar un intervalo de confianza de x% (ejemplo 95%)
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el nivel de confianza que se imprimirá a las
estimaciones de intervalo. Sin embargo, estas salen de la óptica y grado de exigencia del curso ya que en el mismo se
le enseñará a dominar las principales técnicas estadísticas de utilidad para su vida profesional. Si usted desea
profundizar en esto, puede cursar una maestría en administración o una en finanzas que logre ese grado de
profundización o puede consultar fuentes más avanzadas en Econometría o análisis de datos multivariante
- 3.3.1 Estimaciones de intervalo para muestras apareadas grandes y pequeñas
- Hasta ahora se ha trabajado con el supuesto de que los datos están
normalmente distribuidos ya sea porque así nos conviene o porque hemos trabajado con muestras con más de 30
datos, situación que satisface el Teorema del Límite Central previamente revisado
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x ,y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se exponen
las 30 muestras aleatorias en comparación a la media poblacional.
- 4 Prueba de hipótesis: La técnica clásica
Annotations:
- Hasta ahora se ha visto una de las aplicaciones de la Estadística inferencial que es la estimación de valores futuros dados los datos muestrales con que se cuenta. Ahora se revisará una de las técnicas más útiles y necesarias de la misma, la cual no será excepción en aplicaicones de su empresa y futuras materias de su carrera como pueden ser Producción, Administración de la calidad o Finanzas. Esta técnica de la que se habla es: la prueba de hipótesis
- En el subtema 2.7 se habló de un proceso de 5 pasos que se debe seguir en el proceso de toma de decisiones
utilizando la Estadística y que es el mismo que deberá usted aplicar en su vida cotidiana:
Annotations:
- 1. Definir el objetivo: Definir el objetivo de la decisión que se va a hacer. Por ejemplo, determinar si la calidad del inventario es buena o no, si el número de piezas desperdiciadas es mayor a cierta cantidad, si el número de trimestres con pérdida es mayor a cierto objetivo o si el número de conexiones fallidas en un sistema de cómputo es mayor a determinada cantidad objetivo que se define en los estándares de calidad de la empresa de comunicaciones. Estos ejemplos se dan por citar algunos casos de lo que podría presentársele en su vida cotidiana. 2. Definir lo que se medirá: Aquí usted definirá cuál será la variable que delimitará la toma de sus decisiones. Por ejemplo “La cantidad de desperdicio” o el número de trimestres con pérdidas”. 3. Definir el tamaño de muestra: Esto es de vital importancia y se ha revisado en temas anteriores. Si usted no conoce el verdadero tamaño de la población ni sus parámetros como son la media y la desviación estándar, entonces apelará al teorema del límite central. Si se encuentra al caso contrario, usted empleará la fórmula 22 si y solo si se le proporciona algún valor que corresponda a la desviación estándar de dicha población. 4. Analizar los datos: Aquí se pueden utilizar varias técnicas de análisis. De entrada pueden ser lastécnicas de estimación y la comprobación de hipótesis. 5. Conclusión y toma de decisiones: Para fines del tema que interesa, una vez que se aplica la comprobación de hipótesis, se tiene una conclusión de la que se toma una decisión en la empresa.
- 4.1 Comprobación de hipótesis de una sola muestra
Annotations:
- Para exponer el concepto de la prueba de hipótesis se deben recordar tanto la forma de hacer estimaciones como el cálculo de probabilidades empleando valores Z o valores t. Para iniciar con la exposición de la idea recordemos al ejemplo de los comerciantes de aguacate. En concreto, centremos la atención de la empresaria de Chicago. Suponga usted que ella busca definir que la calidad de su inventario (recordemos que este concepto está medido a través del peso de cada fruta) debe ser mayor a 3.8 onzas (Oz.) para decir que tiene buena calidad. Suponga que la empresaria toma una muestra de 30 aguacates de su inventario total de 5,000 y la experiencia de inventarios previos le dice que la desviación estándar en el peso de los aguacates es de 1.1 Oz.
- Para poder responder esta pregunta de si el inventario cubre los estándares de calidad de la empresa, la
comerciante de Chicago tuvo que hacer los tres primeros pasos del proceso de toma de decisiones con la
Estadística:
Annotations:
- 1. Definir el objetivo: Determinar si el estándar de calidad mínimo requerido se cumple en el inventario. 2. Definir lo que se medirá: Definir “calidad” como sinónimo de peso de la fruta: Más peso=más calidad. 3. Definir el tamaño de muestra: En base al Teorema del límite central previamente visto, la empresaria decide hacer una muestra de 30 piezas.
- El cuarto paso correspondería al análisis de datos y es en ese punto donde se realiza la comprobación de
hipótesis. En términos generales, lo que se busca hacer en una comprobación de hipótesis con la técnica
clásica es determinar que, dada la muestra de datos que se tiene, la media de la misma es igual, más grande o
más pequeña que la media de la población o media objetivo.
- El objetivo que se busca lograr con la prueba de hipótesis es determinar una de las siguientes
posibilidades de hipótesis:
Annotations:
- Este tipo de hipótesis y el tipo de prueba se verán a detalle en breve. Lo que desea resaltar es que, en la técnica estadística que interesa, se busca determinar si la media de una muestra es igual, superior o inferior a un estándar teórico.
- El proceso de comprobación de hipótesis:
Annotations:
- 1. Definir una hipótesis nula a demostrar: Se plantea el enunciado (hipótesis) a demostrar y se plantean la hipótesis nula ( H0 ) y la alternativa ( Ha ). 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior. 3. Se define el grado de significancia: Este es el contrario al intervalo de confianza. Es decir, si se tiene 5% de significancia, se tiene 95% de confianza. Aquí se calculan los valores Z o t con las expresiones de las formulas 24 y 25. 4. Se define si se trabaja con la escala original o con una estandarizada. 5. Se define la regla de aceptación. 6. Se comparan los valores críticos fijados con los estadísticos (valor Z o media muestral) y se determina si se acepta la hipótesis nula ( H0) o se abre paso a la alternativa ( Ha ).
- 4.1.1 Ejemplos de los diferentes tipos de prueba de hipótesis con técnica clásica aplicados a una
muestra simple.
- 4.1.1.1 Pruebas de hipótesis para demostrar igualdad de la media muestral con una media
poblacional conocida o hipotética
Annotations:
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media objetivo o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la comerciante de Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar mejor el empleo de la prueba de hipótesis en diferentes circunstancias
- 4.1.1.1.1 Prueba de hipótesis para demostración de igualdad empleando muestras grandes.
Annotations:
- De entrada, la comerciante de Chicago tiene el siguiente inventario, al cual se le establecen la media hipotética de 3.8 . Ho Oz y una desviación estándar poblacional, determinada con la experiencia previa de la empresaria .
Annotations:
- El objetivo de la empresaria para este primer caso es determinar que un embarque de 5,000 piezas de aguacate que le acaba de llegar se ajusta a su estándar de calidad de 3.8 onzas que es el valor que define a la media poblacional hipotética. Para ello tomó 30 piezas de dicho embarque y siguió los siguientes pasos para demostrar que la calidad del mismo se ajusta al objetivo planteado. Esto lo hizo siguiendo los pasos que se presentan:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) igual a 3.8 Oz”
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta una prueba de dos
colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad. Esto le lleva a un valor Z de
1.9599.
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir los valores
críticos correspondientes al intervalo de confianza con los que aceptará o rechazará la
hipótesis. Esto la llevó a determinar los siguientes valores críticos
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad se definió, en la
gráfica anterior y como zona de aceptación, a todos los valores de X . Esto
lleva a la siguiente regla de aceptación
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ):
Annotations:
- Conclusión: En base a los datos que tiene la empresaria de Chicago, ella puede concluir que el embarque de 5,000 aguacates cumple con los estándares de calidad que tiene establecidos ya que la media muestral de una muestra aleatoria de 30 aguacates es estadísticamente igual al peso
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ):
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad se definió, en la
gráfica anterior y como zona de aceptación, a todos los valores de X . Esto
lleva a la siguiente regla de aceptación
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta una prueba de dos
colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad. Esto le lleva a un valor Z de
1.9599.
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 4.1.1.1.2 Prueba de hipótesis para demostración de igualdad empleando una muestra grande y una
escala estandarizada
Annotations:
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada. Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a contrastar, considerando que es muestra grande
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) igual a 3.8 Oz”
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad.
Esto le lleva a un valor Z de 1.9599.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores Z que
corresponden a
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba de
dos colas) se definió, en la gráfica anterior, como zona de aceptación a todos los valores de Z que se
encuentren entre IC IC y . Esto lleva a la siguiente regla de aceptación:
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
Annotations:
- Conclusión: Por tanto, en base a los datos que tiene la empresaria de Chicago, ella llega a la misma conclusión de la prueba de hipótesis anterior, con la diferencia de que se utilizó una escala diferente.
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba de
dos colas) se definió, en la gráfica anterior, como zona de aceptación a todos los valores de Z que se
encuentren entre IC IC y . Esto lleva a la siguiente regla de aceptación:
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores Z que
corresponden a
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad.
Esto le lleva a un valor Z de 1.9599.
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 4.1.1.1.3 Prueba de hipótesis para un caso de demostración de igualdad con una muestra pequeña con escala
original.
Annotations:
- Note usted cómo se empleó, para las pruebas anteriores, la escala original y el valor Z ya sea para realizar las estimaciones de intervalo o para definir el estadístico de prueba en una escala estandarizada
- Sin embargo
Annotations:
- ¿Qué hubiera sucedido si la empresaria hubiera tomado sólo 15 aguacates en lugar de 30 y hubiese decidido emplear la escala original (onzas)? En este punto, la muestra sería pequeña y la media muestralsería ahora de X 5.1318:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) diferente a 3.8 Oz”. Esto se representa con la siguiente hipótesis nula a
demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea
la distribución t-Student o un valor t
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%, al ser esta
una prueba de dos colas. Con esto, debe buscar un valor en tablas que corresponda a 2.5% de
probabilidad con 14 grados de libertad, lo que la lleva a un t de 2.1447.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala original, se establecen los siguientes valores críticos:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba
de dos colas) se define como zona de aceptación a todos los valores de X que se encuentren entre IC
IC
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados
Annotations:
- Conclusión: Por tanto, en base a los datos que tiene la empresaria de Chicago, ella puede concluir que el embarque de 5,000 aguacates cumple con los estándares de calidad que ella tiene establecidos ya que la media de una muestra aleatoria de 15 aguacates es estadísticamente igual a la media hipotética u objetivo dada por Ho y esto le dice que, dada la información de esas pocas piezas, el resto del embarque puede ser aceptado y comprado.
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala original, se establecen los siguientes valores críticos:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%, al ser esta
una prueba de dos colas. Con esto, debe buscar un valor en tablas que corresponda a 2.5% de
probabilidad con 14 grados de libertad, lo que la lleva a un t de 2.1447.
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) diferente a 3.8 Oz”. Esto se representa con la siguiente hipótesis nula a
demostrar y su alternativa:
- 4.1.1.1.4 Prueba de hipótesis para demostración de igualdad empleando una muestra pequeña y una
escala estandarizada.
Annotations:
- Ahora se procederá a realizar la prueba de igualdad con muestra pequeña como la anterior pero utilizando valores estandarizados. Para ello se tienen los siguientes pasos:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) igual a 3.8 Oz”. Esto se representa con la siguiente hipótesis nula a
demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
igualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea
la t-Student y, por ende, se emplea un valor t.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor t en tablas que corresponda a 47.5% de probabilidad
(recuerde que es un 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma). Esto le
lleva a un valort de 2.1447.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores t
que corresponden a:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad
se definió, como zona de aceptación, a todos los valores de t que se encuentren entre IC IC
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad
se definió, como zona de aceptación, a todos los valores de t que se encuentren entre IC IC
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores t
que corresponden a:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor t en tablas que corresponda a 47.5% de probabilidad
(recuerde que es un 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma). Esto le
lleva a un valort de 2.1447.
- 4.1.1.2 Pruebas de hipótesis para demostrar desigualdad de la media muestral con una media poblacional conocida o
hipotética.
- Para poder utilizar este ejemplo, suponga ahora que, por alguna circunstancia peculiar, la empresaria de
Chicago desea que el inventario de aguacates sea diferente de 8.9 Ho Oz. Es decir, puede tener cualquier
peso superior o inferior diferente a 8.9 Oz. Entonces, la comerciante buscará hacer una prueba de hipótesis
en donde busca comprobar que dicha desigualdad existe. A continuación se le presentan los 4 casos de
igualdad estudiados pero como desigualdades.
- Los datos del problema para el caso de una prueba de hipótesis de desigualdad, como se ha visto, serán los
mismos salvo el valor de la media hipotética 8.9 Ho Oz . A su vez, es de necesidad observar que, para el
caso de desigualdad, las reglas de aceptación de la hipótesis nula (H0 ) cambian por las siguientes marcadas
con el ID 2 en la tabla 16
- Los datos del problema para el caso de una prueba de hipótesis de desigualdad, como se ha visto, serán los
mismos salvo el valor de la media hipotética 8.9 Ho Oz . A su vez, es de necesidad observar que, para el
caso de desigualdad, las reglas de aceptación de la hipótesis nula (H0 ) cambian por las siguientes marcadas
con el ID 2 en la tabla 16
- 4.1.1.2.1 Prueba de hipótesis para demostración de desigualdad empleando muestras grandes y escala
original.
Annotations:
- Ahora se demostrará la desigualdad de la muestra tomada, respecto al objetivo planteado tomando la escala original de valores. Para ello, se siguen estos pasos:
- . Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) diferente a 8.9 Oz”. Esto se representa con la siguiente hipótesis nula
a demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una
desigualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad
(recuerde que es un 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma). Esto le
lleva a un valor Z de 1.9599.
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir los valores
críticos
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de desigualdad
(prueba de dos colas) se definió, como zona de aceptación, a todos los valores de X que se encuentren
entre
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes
resultados
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes
resultados
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de desigualdad
(prueba de dos colas) se definió, como zona de aceptación, a todos los valores de X que se encuentren
entre
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir los valores
críticos
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad
(recuerde que es un 47.5% de probabilidad arriba de la media y 47.5% debajo de la misma). Esto le
lleva a un valor Z de 1.9599.
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una
desigualdad:
- 4.1.1.2.2 Prueba de hipótesis para demostración de desigualdad empleando una muestra grande y una
escala estandarizada
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada. Es
decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a contrastar,
considerando si es muestra grande. Esto lleva al cálculo de los estadísticos de la forma en que se expresa en
la fórmula 24 para muestra grande:
- Retomando el objetivo de la empresaria de Chicago quien desea demostrar que un determinado
embarque de aguacates tiene un peso diferente a la media hipotética de 8.9 . Ho Oz y una
desviación estándar poblacional (determinada con la experiencia previa de la empresaria) de 1.1 .
Oz , la comprobación de hipótesis llevaría a un estadístico de prueba Z dado por (recuerde que la
muestra es de 30 piezas y la media muestral de 4.7365):
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) diferente a 8.9 Oz”
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una
igualdad
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea
la gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad.
Esto le lleva a un valor Z de 1.9599.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar los valores críticos
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de desigualdad
(prueba de dos colas) se definió, como zona de aceptación, a todos los valores de Z que se
encuentren entre
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultado
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultado
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar los valores críticos
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor Z en tablas que corresponda a 47.5% de probabilidad.
Esto le lleva a un valor Z de 1.9599.
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una
igualdad
- 4.1.1.2.3 Prueba de hipótesis para un caso de demostración de desigualdad con una muestra pequeña
con escala original.
Annotations:
- Ahora se retoma el caso de una muestra pequeña con 15 piezas que tiene una media muestral de de X 5.1318 y un objetivo de demostrar desigualdad para una media hipotética de 08.9. Con estos datos iniciales, para este tipo de prueba de hipótesis, se siguieron los pasos que se presentan:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una
calidad (peso) diferente a 8.9 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una desigualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la
distribución t-Student o un valor t
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%, al ser esta una
prueba de dos colas, debe buscar un valor en tablas que corresponda a 2.5% de probabilidad con 14
grados de libertad, lo que la lleva a un t de 2.1447.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala original, se establecen los siguientes valores críticos
- Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba de dos
colas) se definió, como zona de aceptación, a todos los valores de t que se encuentren entre
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta
la hipótesis nula ( H0 ) o se abre paso a la alternativa (Ha ):
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta
la hipótesis nula ( H0 ) o se abre paso a la alternativa (Ha ):
- Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba de dos
colas) se definió, como zona de aceptación, a todos los valores de t que se encuentren entre
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala original, se establecen los siguientes valores críticos
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%, al ser esta una
prueba de dos colas, debe buscar un valor en tablas que corresponda a 2.5% de probabilidad con 14
grados de libertad, lo que la lleva a un t de 2.1447.
- 2. Se determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 2, ya que se busca demostrar una desigualdad:
- 4.1.1.2.4 Prueba de hipótesis para demostración de desigualdad empleando una muestra pequeña y una escala
estandarizada.
Annotations:
- Ahora se procederá a realizar la prueba de desigualdad con muestra pequeña como la anterior pero utilizando valores estandarizados. Para ello se tienen los siguientes pasos:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es
importante observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de
hipótesis de dos colas establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una
desigualdad
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea
la t-Student y, por ende, se emplea un valor t.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor en tablas que corresponda a esto y a 14 grados de
libertad, lo que le lleva a un t de 2.1447.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores t
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad (prueba
de dos colas) se definió, como zona de aceptación a todos los valores de t que se encuentren entre
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se
acepta la hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Se tienen los siguientes resultados:
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con
escala estandarizada, lo que se busca es determinar los valores críticos (IC) como los valores t
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria decide utilizar un valor t que corresponda a un nivel de significancia de 2.5%. Al ser esta
una prueba de dos colas, debe buscar un valor en tablas que corresponda a esto y a 14 grados de
libertad, lo que le lleva a un t de 2.1447.
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada. Es
decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a contrastar,
considerando si es muestra grande. Esto lleva al cálculo de los estadísticos de la forma en que se expresa en
la fórmula 24 para muestra grande:
- 4.1.1.3.1 Prueba de hipótesis de cola superior empleando muestra grande y escala original
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a
demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor Z en tablas que corresponda a 95% de probabilidad Esto le lleva a un valor Z
de 1.6448
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria decidió
trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del intervalo de
confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar el siguiente valor crítico:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de cola superior, se
definió, como zona de aceptación, a todos los valores de X que se encuentren arriba de IC
- 7. Se comparan el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 7. Se comparan el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria decidió
trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del intervalo de
confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar el siguiente valor crítico:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor Z en tablas que corresponda a 95% de probabilidad Esto le lleva a un valor Z
de 1.6448
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 4.1.1.3.2 Prueba de hipótesis de cola superior empleando muestra grande y escala estandarizada
Annotations:
- Ahora se hará la misma prueba de hipótesis de cola superior con muestra grande empleando una escala estandarizada. Para ello se siguieron estos pasos:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido
tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su
alternativa:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor Z en tablas que corresponda a 95% de probabilidad Esto le lleva a un valor
Z de 1.6448.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con escala
estandarizada, lo que se busca es determinar el valor crítico (IC) del intervalo superior como el valor Z que
corresponde a:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de cola superior se definió,
como zona de aceptación, a todos los valores de X que se encuentren arriba de IC
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa (Ha ): Se tienen los siguientes resultados:
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa (Ha ): Se tienen los siguientes resultados:
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja con escala
estandarizada, lo que se busca es determinar el valor crítico (IC) del intervalo superior como el valor Z que
corresponde a:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor Z en tablas que corresponda a 95% de probabilidad Esto le lleva a un valor
Z de 1.6448.
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 4.1.1.3.3 Prueba de hipótesis de cola superior con muestra pequeña y escala original.
Annotations:
- Ahora se tomará el caso de la muestra pequeña (15 aguacates) con su media muestral de 5.1318 Oz y la misma desviación estándar poblacional de 1.1 Oz. En este caso se trabajará con la escala original. Para ello, la empresaria siguió estos pasos:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido
tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su
alternativa:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la
distribución t-Student y, por ende, se emplea un valor t.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la empresaria
decide utilizar un valor t que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor t en tablas que corresponda a 5% de probabilidad y 14 grados de
libertad. Esto le lleva a un valor t de 1.7613.
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria
decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del
intervalo de confianza con el que aceptará o rechazará la hipótesis. Esto la llevó a determinar el siguiente
valor críticos:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de cola superior se definió,
como zona de aceptación, a todos los valores de X que se encuentren arriba de IC
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados:
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria
decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del
intervalo de confianza con el que aceptará o rechazará la hipótesis. Esto la llevó a determinar el siguiente
valor críticos:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la empresaria
decide utilizar un valor t que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una cola
(cola superior), debe buscar un valor t en tablas que corresponda a 5% de probabilidad y 14 grados de
libertad. Esto le lleva a un valor t de 1.7613.
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior
- 4.1.1.3.4 Prueba de hipótesis de cola superior con muestra pequeña y escala de
estandarizada.
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido
tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su
alternativa:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la
distribución t-Student y, por ende, se emplea un valor t
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la empresaria
decide utilizar un valor t que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una
cola (cola superior), debe buscar un valor t en tablas que corresponda a 5% de probabilidad y 14 grados de
libertad. Esto le lleva a un valor t de 1.7613.
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria
decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del
intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar al siguiente
valor crítico: 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico
superior (IC ) del intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a
determinar al siguiente valor crítico:
Annotations:
- IC = 1.7613
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de cola superior se definió,
como zona de aceptación, a todos los valores de X que se encuentren arriba de IC
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ): Con esto, se tienen los siguientes resultados
- 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la empresaria
decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico superior (IC ) del
intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a determinar al siguiente
valor crítico: 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico
superior (IC ) del intervalo de confianza con los que aceptará o rechazará la hipótesis. Esto la llevó a
determinar al siguiente valor crítico:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto, la empresaria
decide utilizar un valor t que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de una
cola (cola superior), debe buscar un valor t en tablas que corresponda a 5% de probabilidad y 14 grados de
libertad. Esto le lleva a un valor t de 1.7613.
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola superior:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates recibido
tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su
alternativa:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se representa con la siguiente hipótesis nula a
demostrar y su alternativa:
- 4.1.1.4 Ejemplos de pruebas de hipótesis de cola inferior
- Para el caso de la prueba de hipótesis de cola inferior se tiene la misma lógica de análisis que las pruebas de
cola inferior, con la diferencia de que las reglas de decisión para aceptar la hipótesis nula () se dan por el
renglón o ID 3 de la tabla 16:
Annotations:
- Por cuestión de espacio, no se hará una exposición extensa de los cuatro posibles casos dado el tamaño de muestra (grande o pequeña) y tipo de escala (original o estandarizada). Lo que se hará será simplemente citar un ejemplo consistente en una muestra grande con escala estandarizada. Usted podrá observar que los pasos a seguir en los otros tres casos son similares a las 4 pruebas previas de cola superior. Solo cambiará, como se ha mencionado, la regla de aceptación de H
- Para exponer este ejemplo, se supondrá ahora que la empresaria no quiere aguacates con un peso menor a
7 Oz, por lo que deberá demostrar que el embarque que ha recibido se ajusta a dicho estándar de calidad.
Para ello, siguió estos pasos:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) menor a 7 Oz”
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola inferior:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la gaussiana
(normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta
una prueba de una cola (cola inferior), debe buscar un valor Z en tablas que corresponda a 95% de
probabilidad Esto le lleva a un valor Z negativo de -1.6448.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar el valor crítico (IC) del intervalo inferior
como el valor Z que corresponde a:
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de cola superior se
definió, como zona de aceptación, a todos los valores de X que se encuentren arriba de IC
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ):
- 7. Se compara el valor crítico fijado con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula ( H0 ) o se abre paso a la alternativa ( Ha ):
- 5. Se define si se trabaja con la escala original o con una estandarizada: Dado que ahora se trabaja
con escala estandarizada, lo que se busca es determinar el valor crítico (IC) del intervalo inferior
como el valor Z que corresponde a:
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la
empresaria decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta
una prueba de una cola (cola inferior), debe buscar un valor Z en tablas que corresponda a 95% de
probabilidad Esto le lleva a un valor Z negativo de -1.6448.
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una cola
establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola inferior:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El embarque de aguacates
recibido tiene una calidad (peso) menor a 7 Oz”
- Para el caso de la prueba de hipótesis de cola inferior se tiene la misma lógica de análisis que las pruebas de
cola inferior, con la diferencia de que las reglas de decisión para aceptar la hipótesis nula () se dan por el
renglón o ID 3 de la tabla 16:
- Para poder utilizar este ejemplo, suponga ahora que, por alguna circunstancia peculiar, la empresaria de
Chicago desea que el inventario de aguacates sea diferente de 8.9 Ho Oz. Es decir, puede tener cualquier
peso superior o inferior diferente a 8.9 Oz. Entonces, la comerciante buscará hacer una prueba de hipótesis
en donde busca comprobar que dicha desigualdad existe. A continuación se le presentan los 4 casos de
igualdad estudiados pero como desigualdades.
- 4.1.1.1 Pruebas de hipótesis para demostrar igualdad de la media muestral con una media
poblacional conocida o hipotética
- 4.2 ¿Cuándo se utiliza la escala original y cuándo la estandarizada?
Annotations:
- se ha observado que una de las variantes que puede tener la comprobación de hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada, lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra.
- algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta sirve para
homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve más para
comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios
aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a
inherente al analista.
- 4.3 ¿Qué se hace cuando se desconoce la desviación estándar
poblacional?
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar poblacional o se
supone una partiendo de la experiencia propia. Por ejemplo, la empresaria de chicago partió de lo que
ha observado con su proveedor, en el sentido de fijar la desviación estándar del peso de aguacates que
ha recibido a lo largo de la historia como de 1.1Oz. Sin embargo, no siempre se conoce este valor por lo
que debe calcularse para poder determinar los estadísticos Z o t.
- 4.4 Pruebas de hipótesis para comparar muestras
Annotations:
- En este caso específico ya no se busca demostrar que los parámetros de una muestra se ajustan a los de una población o a un valor hipotético dado por H 0 .
- Más bien se busca comparar su media, buscando probar que estas sean iguales, mayor en la muestra A respecto
a la B o viceversa. Las posibles pruebas de hipótesis y las reglas de aceptación de H0 para los posibles casos se
presentan en la siguiente tabla:
Annotations:
- Para ilustrar el empleo de este tipo de prueba de hipótesis, tómese la idea original que tenían los dos empresarios aguacateros de comparar la calidad de sus inventarios, con la finalidad de saber si el proveedor, que es el mismo para ambos, les vende la misma calidad. Lo primero que hacen los empresarios es homologar sus escalas de medida, por lo que deciden trabajar con onzas. Posteriormente, deciden probar la calidad estableciendo como objetivo determinar que la calidad que ambos reciben es la misma
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El inventario de aguacates de ambos
comerciantes es igual”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa:
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 17, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una prueba de igualdad:
- 3. Se determina la función de probabilidad a utilizar: En este caso, al ser muestra grande, se emplea la
gaussiana (normal estándar) y, por ende, se emplea un valor Z.
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de dos colas,
se debe buscar un valor Z en tablas que corresponda a 97.5% de probabilidad Esto le lleva a un valor Z de
1.9599.
- 5. Se define si se trabaja con la escala original o con una estandarizada: Se determina trabajar con escala
estandarizada. Con esto, lo que se busca es determinar el valor crítico (IC) del intervalo superior como el valor Z
que corresponde a
- 6. Se define la regla de aceptación: Dado que la prueba a realizar es una prueba de igualdad de dos colas, se
definió, como zona de aceptación, a todos los valores de Z que se encuentren entreIC e IC
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ):
- 7. Se comparan los valores críticos fijados con el estadístico (media muestral) y se determina si se acepta la
hipótesis nula (H0 ) o se abre paso a la alternativa ( Ha ):
- 5. Se define si se trabaja con la escala original o con una estandarizada: Se determina trabajar con escala
estandarizada. Con esto, lo que se busca es determinar el valor crítico (IC) del intervalo superior como el valor Z
que corresponde a
- 4. Se define el grado de significancia: La muestra con que se trabaja es de 30 piezas. Por tanto, la empresaria
decide utilizar un valor Z que corresponda a un nivel de significancia de 5%. Al ser esta una prueba de dos colas,
se debe buscar un valor Z en tablas que corresponda a 97.5% de probabilidad Esto le lleva a un valor Z de
1.9599.
- 2. Se determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 17, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una prueba de igualdad:
- 1. Definir una hipótesis nula a demostrar: La hipótesis a demostrar sería: “El inventario de aguacates de ambos
comerciantes es igual”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa:
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar poblacional o se
supone una partiendo de la experiencia propia. Por ejemplo, la empresaria de chicago partió de lo que
ha observado con su proveedor, en el sentido de fijar la desviación estándar del peso de aguacates que
ha recibido a lo largo de la historia como de 1.1Oz. Sin embargo, no siempre se conoce este valor por lo
que debe calcularse para poder determinar los estadísticos Z o t.
- 5 Prueba de hipótesis: Las técnicas Ji- cuadrada y ANOVA
Annotations:
- Dentro de los supuestos que se han manejado es determinar que existe dependencia o independencia en dichas poblaciones, por un lado y que están ya sea normalmente distribuidas (si se trata de una población o muestra grande) o t-Student distribuidas si se trata de una muestra pequeña
- En este tema específico utilizaremos un tipo de técnica de comprobación de hipótesis conocido como la
técnica Ji-Cuadrada, la cual nos servirá para realizar dos cosas:
Annotations:
- 1. Determinar si dos o más variables o atributos de interés son independientes en base a los datos obtenidos en la muestra. 2. Determinar si el comportamiento de los datos con que se cuenta se explican o no con una distribución de probabilidad determinada como puede ser la normal, la t-Student u otro tipo de casos como son la F, la binomial, la Weibull, la Gumbel, la Poisson, la uniforme u otras. 3. Determinar si la varianza de una muestra es igual, inferior o superior a sierto valor hipotético, poblacional u objetivo.
- Otro tipo de técnica de comprobación de hipótesis que se revisará será la prueba ANOVA (siglas en
idioma inglés de Análisis de varianza –Analysis Of VAriance-) en la cual no se comparan medias
directamente, como en la técnica clásica; sino que se contrastan las varianzas. Esta prueba permitirá, a
su vez, ya no comparar solo dos muestras de manera conjunta. Más bien, ayudará a realizar lo siguiente:
Annotations:
- 1. Comparar 2 o más muestras o poblaciones al mismo tiempo con la finalidad de determinar si son o no iguales sus medias. 2. Comparar 2 o más muestras o poblaciones al mismo tiempo con la finalidad de determinar si son o no iguales o diferentes sus varianzas.
- 5.1 La técnica Ji-Cuadrada
- 5.1.1 Prueba de hipótesis para demostrar independencia.
- Este cuestionamiento se lo planteó después de aplicar las encuestas, recolectar los datos y organizar los
mismos a través de una tabla de contingencia como la siguiente:
Annotations:
- El enunciado de la hipótesis a plantear en este caso sería: “Las variables atributo de la computadora y estrato profesional están relacionadas entre sí y, por tanto pueden influir en la preferencia del usuario de la computadora.”
- Estrato 1: Arquitectos ingenieros, matemáticos, físicos, investigadores y profesionistas que ocupen
procesamiento de cálculo. Estrato 2: Diseñadores gráficos, artistas de medios, músicos y gente que
ocupe procesamiento gráfico. Estrato 3: Amas de casa, estudiantes y gente mayor. Estrato 4: Contadores,
abogados, economistas, financieros y otros profesionistas.
Annotations:
- El cambio formal u operativo en cada situación se da por la ubicación de la zona de aceptación. Para fines de este ejemplo, solo interesa demostrar que hay dependencia entre las dos variables y eso implicaría que las frecuencias observadas son estadísticamente (no numéricamente) iguales. Tal como se planteó en la fórmula
Annotations:
- n la misma surgen dos variables de vital importancia para esta técnica de comprobación de hipótesis. La primera de ellas es 0 f , que se refiere a la frecuencia observada en alguna celda de la tabla de contingencias. Por ejemplo, la frecuencia observada de las personas que prefieren la Mac dado el arranque y que forman parte del estrato
- El segundo concepto de interés viene dado por e f que es la frecuencia esperada para ese atributo. En
este punto usted puede observar una pequeña similitud de esta técnica con la clásica. Se comparan
valores observados contra valores esperados. La forma de determinar la frecuencia esperada se hace
a través de las sumas de renglones (TR) y columnas (TC ) y el número de observaciones (n ).
- Con esto se pueden sustituir ahora los valores de frecuencia observada de cada combinación de
atributos de la tabla 18 y de frecuencia esperada de la tabla 20 para realizar el cálculo de la fórmula
24. Esto se detalla en la siguiente tabla de cálculos:
- Con esto se pueden sustituir ahora los valores de frecuencia observada de cada combinación de
atributos de la tabla 18 y de frecuencia esperada de la tabla 20 para realizar el cálculo de la fórmula
24. Esto se detalla en la siguiente tabla de cálculos:
- 5.1.2 Distribución de probabilidad ji-cuadrada.
- cuando se trata con valores que solo son positivos, será de mucho interés tener una distribución de
probabilidad que nunca tenga valores negativos en su distribución de probabilidad. Por ejemplo, el precio de
una acción nuca tendrá valores negativos pero, en repetidas ocasiones de nuestros ejercicios, las
estimaciones de intervalo llevaban a límites inferiores negativos que no era lógico que existan. Por ejemplo,
podríamos tener la estimación de intervalo del precio de una acción, las calificaciones de un grupo de clase o
el peso de los aguacates dadas por:
Annotations:
- Determinar el número de personas que entran a un supermercado en una determinada hora Aplicaciones de administración de riesgos crediticios como son, determinar el monto de pérdida potencial que un banco puede tener por hacer préstamos de tarjeta de crédito o definir ¿cuál es la probabilidad de que nuestra cartera de clientes acreditados nos haga perder X cantidad de dinero por incumplimiento de pago? Determinar si el número de conexiones a nuestra página por medio internet de internet es igual a un número objetivo. Determinar que la varianza de nuestros datos es igual, inferior o superior a un valor objetivo.
- Las que, de momento, nos interesan más:
Annotations:
- o Determinar si dos variables, dada la frecuencia de la combinación de ambas en una tabla de contingencia, son dependientes o independientes. o Determinar si un conjunto de datos se distribuye o explica con una función de densidad de probabilidad determinada (prueba de bondad de ajuste). o Determinar si la varianza de una población, inferida a partir de una muestra de datos, se ajusta a un objetivo preestablecido
Annotations:
- onforme se incrementan los grados de libertad, la distribución ji-cuadrada se parece más a una normal o al menos es simétrica. La única diferencia de interés está en que se tiene una distribución de probabilidades en la que ninguno de los valores modelados es negativo, lo que asegura nuestro interés original expresado líneas atrás.
Annotations:
- Para identificar el número de grados de libertad en la primera columna observe cómo pa1 y pt1 tienen valores de elección libre para usted. Sin embargo, el valor de pc1 ya no es libre porque su magnitud es fundamental para que la suma de pa1, pt1 y pc1 sea de 20. Lo propio sucede en las otras dos columnas. Ahora, si usted replica el ejercicio en los renglones y marca con amarillo las celdas que deben mantenerse sin cambio para que resulten los valores de la sumatoria por columnas o por renglones, observará que solo tiene usted seis valores de libre elección
- Por lo tanto, usted puede calcular valores críticos o 2 i x (el equivalente a valores t o z) partiendo de un
nivel de significancia deseado como puede ser, a manera de ejemplo, α=5% y con los 6 grados de libertad
del ejemplo de Jobs, usted llega a un valor 2 xi, , 24.99 puede elaborar la siguiente gráfica con un
valor crítico de rechazo representado con una línea punteda:
- 1. La media global de frecuencia observada de las ocho combinaciones de variable O sea una frecuencia
media global de 6.66. Esta se aprecia claramente como el valor de mayor probabilidad en la distribución
- 2. Ahora, lo que se busca es determinar qué tan separada está la frecuencia de observaciones de
preferencia en cada combinación de atributo y estrato respecto a un valor esperado determinado con la
fórmula 25. Esta separación en cada cado se suma. Si la misma se encuentra un valor menor o igual a
esa media global, se puede aceptar el hecho de que las variables están estrechamente relacionadas e
influyen en la preferencia que una persona tiene por la Mac, dado el atributo y el estrato
- 3. Ahora, si la diferencia es muy grande (es estadísticamente superior a la media de frecuencias por
preferencia global en cada combinación de atributo y estrato), se deberá rechazar a la hipótesis de
dependencia entre variables utilizando el estadístico Ji determinado con la fórmula 24:
- 3. Ahora, si la diferencia es muy grande (es estadísticamente superior a la media de frecuencias por
preferencia global en cada combinación de atributo y estrato), se deberá rechazar a la hipótesis de
dependencia entre variables utilizando el estadístico Ji determinado con la fórmula 24:
- 2. Ahora, lo que se busca es determinar qué tan separada está la frecuencia de observaciones de
preferencia en cada combinación de atributo y estrato respecto a un valor esperado determinado con la
fórmula 25. Esta separación en cada cado se suma. Si la misma se encuentra un valor menor o igual a
esa media global, se puede aceptar el hecho de que las variables están estrechamente relacionadas e
influyen en la preferencia que una persona tiene por la Mac, dado el atributo y el estrato
- 1. La media global de frecuencia observada de las ocho combinaciones de variable O sea una frecuencia
media global de 6.66. Esta se aprecia claramente como el valor de mayor probabilidad en la distribución
- 5.1.3 Algunas consideraciones a tomar con la prueba ji-cuadrada.
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan
- 1. Nunca se deben trabajar con tablas de contingencia que tengan frecuencias menores a 5. Es decir,
que el valor de una celda sea menor a 5. Si en algún momento se presentara este caso en dos o más
celdas, podemos eliminar algunas categorías (renglón o columna) y combinar los valores de la (s)
eliminada (s) con otra que esté en el mismo caso y así lograr frecuencias mayores o iguales a 5. Sin
embargo, esto tiene la limitante de la pérdida de una o varias categorías y el examen de independencia
entre variables quedaría muy parcial.
- 2. Si, por alguna circunstancia, el valor ji-cuadrada derivado con la fórmula 24 diera cero, debe
sospecharse del resultado ya que se puede estar en presencia de un problema de una inapropiada
recolección de datos
- 1. Nunca se deben trabajar con tablas de contingencia que tengan frecuencias menores a 5. Es decir,
que el valor de una celda sea menor a 5. Si en algún momento se presentara este caso en dos o más
celdas, podemos eliminar algunas categorías (renglón o columna) y combinar los valores de la (s)
eliminada (s) con otra que esté en el mismo caso y así lograr frecuencias mayores o iguales a 5. Sin
embargo, esto tiene la limitante de la pérdida de una o varias categorías y el examen de independencia
entre variables quedaría muy parcial.
- 5.1.4 Prueba de hipótesis ji cuadrada para bondad de ajuste (determinar la función de probabilidad a emplear
en un grupo de datos).
Annotations:
- Ahora se revisará uno de los usos más comunes que tiene la prueba con distribución ji-cuadrada: Determinar si el comportamiento de un grupo de datos se explica con alguna función de densidad determinada
- En estas notas nos limitaremos, con la finalidad de solo sensibilizarle al empleo de la distribución de
probabilidad ji-cuadrada, a determinar si los datos con que se trabaja están o no normalmente distribuidos
- Para ello, se utilizará el cálculo de un estadístico elaborado ampliamente utilizado en la Econometría y el
análisis estadístico y el cuál fue elaborado por un Mexicano (Carlos Jarque15) y Anil Bera. El mismo se conoce
como estadístico Jarque-Bera
- La lógica del estadístico Jarque-Bera parte de dos conceptos fundamentales inherentes a una función de
probabilidad como es la normal:
Annotations:
- la gráfica de la distribución de probabilidad no es tan simétrica como debería de ser y tiene una cola más larga a la izquierda o a la derecha. Cuando la cola mes más larga a la izquierda se dice que se tiene un sesgo negativo ya que es mayor la probabilidad de tener valores más negativos que positivos. En caso contrario, se dice que se tiene un sesgo positivo por que se tienen mayores probabilidades de tener valores más positivos que negativos
- El sesgo de la distribución de probabilidad de los datos se calcula como sigue:
Annotations:
- Una función de probabilidad normal estándar debe tener la forma de la función de probabilidad b ya que las probabilidades que se lograrían con los diferentes valores de ix se apegan a la descripción de la función de probabilidad descrita en la fórmula 5. Cuando se tiene el caso de una probabilidad leptokúrtica se observa que las probabilidades de suceso se concentran en los valores cercanos a la media y le dan poca probabilidad a los valores más extremos a la derecha y a la izquierda
- Fórmula 30: Cálculo del estadístico Jarque-Bera:
- Sin embargo, se revisan los datos y se determinan los cálculos de sesgo, kurtosis y estadístico
Jarque-Bera que lleva a un valor de 179.1553. Esto se aprecia en la siguiente ilustración:
- Sin embargo, se revisan los datos y se determinan los cálculos de sesgo, kurtosis y estadístico
Jarque-Bera que lleva a un valor de 179.1553. Esto se aprecia en la siguiente ilustración:
- Fórmula 30: Cálculo del estadístico Jarque-Bera:
- La lógica del estadístico Jarque-Bera parte de dos conceptos fundamentales inherentes a una función de
probabilidad como es la normal:
- Para ello, se utilizará el cálculo de un estadístico elaborado ampliamente utilizado en la Econometría y el
análisis estadístico y el cuál fue elaborado por un Mexicano (Carlos Jarque15) y Anil Bera. El mismo se conoce
como estadístico Jarque-Bera
- 5.1.5 Prueba de hipótesis ji-cuadrada para hacer inferencias sobre la varianza de una sola población
(o muestra)
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de
datos o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado.
La lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica
clásica. Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un
valor ji-cuadrada tanto para el intervalo superior como el inferior, según el caso que
aplique.
- Otra diferencia obvia y fundamental de la prueba ji-cuadrada es que no emplea una distribución
normal o t-Student para fijar los mencionados valores críticos.
- que ahora el embarque tenga una varianza de máximo 1.21 que se da por la desviación estándar que
ella tiene por experiencia previa con su proveedor. Por tanto, lo que debe ella hacer
es una prueba de hipótesis de cola inferior para demostrar que ahora la varianza es la que se ajusta a
los objetivos establecidos. Por ejemplo, puede establecer la siguiente hipótesis nula y alternativa:
- Al hacer la comparación se tiene el siguiente resultado:
- Al hacer la comparación se tiene el siguiente resultado:
- que ahora el embarque tenga una varianza de máximo 1.21 que se da por la desviación estándar que
ella tiene por experiencia previa con su proveedor. Por tanto, lo que debe ella hacer
es una prueba de hipótesis de cola inferior para demostrar que ahora la varianza es la que se ajusta a
los objetivos establecidos. Por ejemplo, puede establecer la siguiente hipótesis nula y alternativa:
- Otra diferencia obvia y fundamental de la prueba ji-cuadrada es que no emplea una distribución
normal o t-Student para fijar los mencionados valores críticos.
- 5.1.6 Haciendo estimaciones de intervalos de varianzas
Annotations:
- Así como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede replicar el ejercicio en el caso de las varianzas
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de
datos o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado.
La lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica
clásica. Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un
valor ji-cuadrada tanto para el intervalo superior como el inferior, según el caso que
aplique.
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan
- cuando se trata con valores que solo son positivos, será de mucho interés tener una distribución de
probabilidad que nunca tenga valores negativos en su distribución de probabilidad. Por ejemplo, el precio de
una acción nuca tendrá valores negativos pero, en repetidas ocasiones de nuestros ejercicios, las
estimaciones de intervalo llevaban a límites inferiores negativos que no era lógico que existan. Por ejemplo,
podríamos tener la estimación de intervalo del precio de una acción, las calificaciones de un grupo de clase o
el peso de los aguacates dadas por:
- Este cuestionamiento se lo planteó después de aplicar las encuestas, recolectar los datos y organizar los
mismos a través de una tabla de contingencia como la siguiente:
- 5.2 Prueba ANOVA.
Annotations:
- ). En temas previos se hicieron comparaciones de medias muestrales respecto a un objetivo hipotético o de diferencias entre dos muestras solamente. Lo propio se hizo para revisar la varianza de una sola muestra. Es decir, para determinar si esta era igual, superior o inferior a un objetivo determinado
- Para reducir todo este trabajo, la prueba ANOVA viene al rescate e incluso quizá sea la más adecuada
en muchas aplicaciones de su futura vida profesional. Las nociones intuitivas de dicha prueba
consisten en comparar dos muestras a través de su varianza y no de su media muestral. La idea se
expone en la siguiente gráfica:
- Si se observa con detenimiento la gráfica 34, se puede notar que la desigualdad en la varianza de las
tres muestras se puede atribuir a dos factores
Annotations:
- La varianza existente entre las medias muestrales. Es decir, qué tan separadas están unas de otras respecto a un promedio de medias o gran media X . La varianza conjunta existente entre todos los datos de las muestras.
- Para ilustrar mejor la idea, observe la gráfica superior izquierda. Usted verá que prácticamente no
existe variabilidad o varianza entre las medias muestrales y, si la varianzas son
iguales, la variabilidad total (graficada con una línea roja como “todas las muestras”) es prácticamente
la misma que la existente entre las medias muestrales.
- 5.2.1 La función de probabilidad F.
- 5.2.2 La prueba F
Annotations:
- Ahora que se observa que se tienen los múltiples datos necesarios como los grados de libertad del numerador y los del denominador se puede calcular el estadístico F y determinar un valor crítico F empleando las tablas correspondientes al emplear los grados de libertad del numerador y del denominador. Para ello será de necesidad utilizar las tablas de valores F como la que se presenta en la plataforma Moodle en el tema correspondiente a la prueba ANOVA.
- 5.2.3 Prueba ANOVA para probar la igualdad en la varianza entre dos
muestras. El caso de la cola superior.
Annotations:
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar que la prueba ANOVA es muy poderosa para contrastar igualdad entre medias.
Annotations:
- Dado que el estadístico F se encuentra dentro de los dos intervalos, se observa se acepta la hipótesis de igualdad entre las varianzas y se rechaza la de desigualdad. Hasta este punto es que se revisan los métodos de comprobación de hipótesis más comunes. Estos son conocidos como pruebas estadísticas paramétricas ya que suponen la preexistencia tanto de parámetros poblacionales como la suposición de normalidad o algún tipo de función de probabilidad en los datos aleatorios
- 5.1.1 Prueba de hipótesis para demostrar independencia.
- 6 Estadística multivariada: Regresión lineal simple y multivariada.
Annotations:
- Conceptos de estadística multivariada. Hasta el momento se ha trabajado con el contraste de muestras o poblaciones que tienen una distribución de probabilidad identidad y, en algunos casos, que tienen un comportamiento dependiente una de la otra.
Annotations:
- Un ejemplo, en las ciencias económico-administrativas se puede encontrar en el comportamiento de los rendimientos pagados por una acción que cotiza en bolsa. Suponga usted que tiene un histórico de las variaciones porcentuales diarias del precio o rendimientos de dos acciones que cotizan en la bolsa han tenido a lo largo de un año
Annotations:
- se tienen dos probabilidades llamadas “marginales” Estas no son más que las distribuciones de probabilidad gaussianas de la variación porcentual del precio de AMX y de KOF respectivamente. Es decir las probabilidades de que AMX varíe un X% o de que KOF lo haga en un Y% independientemente del comportamiento de otras acciones. Sin embargo, la superficie en forma de campana o “montaña” colorida que se tiene al centro cuantifica la probabilidad de que AMX vería un X% dado o por la influencia de que KOF varía a su vez y al mismo tiempo un Y%.
Annotations:
- A manera de reflexión respecto al método de cálculo, si observa detenidamente la fórmula 39, podrá observar que hay una estrecha relación entre la varianza de una variable aleatoria y la covarianza entre variables aleatorias
- 6.1 El coeficiente de correlación y su interacción con la covarianza.
- Por ejemplo qué hace que el número de flores en un valle sea mayor conforme hay lluvia es algo que la
biología, en especial la Botánica, nos puede responder. Qué hace que el precio de una acción se mueva en
conjunto con el de otra es otra situación que se puede investigar con la Economía Financiera y así
sucesivamente
- Todas las causas de este fenómeno de interacción se responden con las respectivas ciencias de interés. Sin
embargo responder ¿en qué magnitud y con qué grado de apego se mueven dos fenómenos modelados
matemáticamente a través de dos variables aleatorias? Es algo que se responde gracias a la estadística. En
qué magnitud se mueve una variable aleatoria de manera conjunta respecto al movimiento de otra se
determina con la covarianza
- Vea usted el coeficiente de correlación como el “pegamento” entre variables. Con este pegamento o
nivel de gravedad usted puede calcular la covarianza como sigue
- Vea usted el coeficiente de correlación como el “pegamento” entre variables. Con este pegamento o
nivel de gravedad usted puede calcular la covarianza como sigue
- Todas las causas de este fenómeno de interacción se responden con las respectivas ciencias de interés. Sin
embargo responder ¿en qué magnitud y con qué grado de apego se mueven dos fenómenos modelados
matemáticamente a través de dos variables aleatorias? Es algo que se responde gracias a la estadística. En
qué magnitud se mueve una variable aleatoria de manera conjunta respecto al movimiento de otra se
determina con la covarianza
- Por ejemplo qué hace que el número de flores en un valle sea mayor conforme hay lluvia es algo que la
biología, en especial la Botánica, nos puede responder. Qué hace que el precio de una acción se mueva en
conjunto con el de otra es otra situación que se puede investigar con la Economía Financiera y así
sucesivamente
- 6.2 El modelo regresión lineal simple para establecer relaciones estadísticas entre variables y hacer
pronósticos básicos.
- 6.2.1 Determinación de los coeficientes del modelo de regresión
Annotations:
- Para determinar los coeficientes de regresión, siendo esta el modelo resultante de la interacción entre las dos variables, se ocupa la covarianza que es la que cuantifica el grado de variación promedio conjunta entre variables, la varianza de la variable regresora ( x ) 16, y la media muestral de la regresada (Y ):
Media attachments
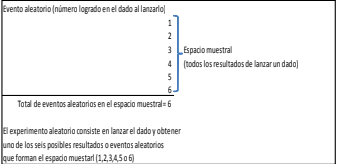{kind=link}
{kind=link}
{kind=link}
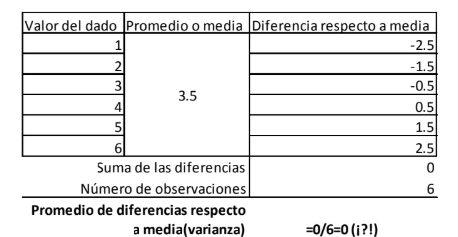{kind=link}
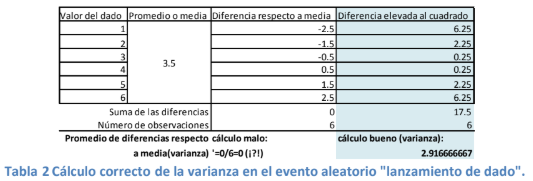{kind=link}
{kind=link}
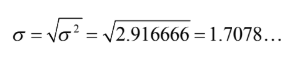{kind=link}
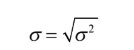{kind=link}
{kind=link}
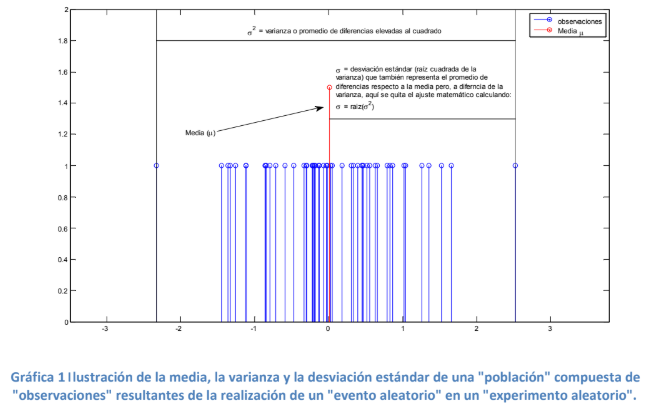{kind=link}
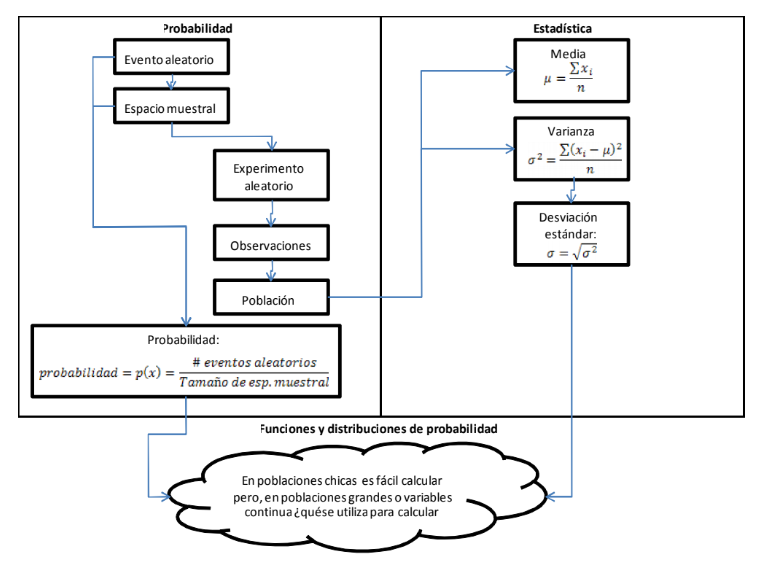{kind=link}
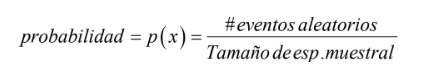{kind=link}
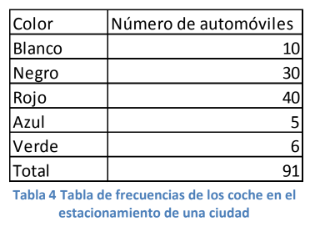{kind=link}
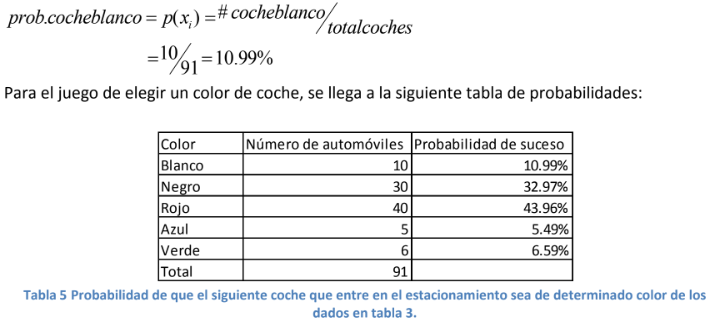{kind=link}
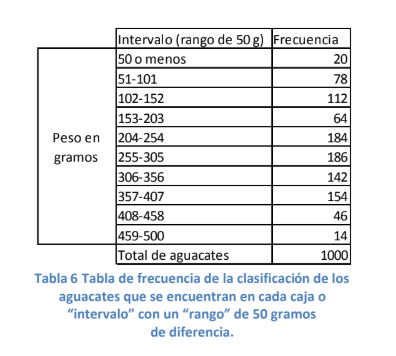{kind=link}
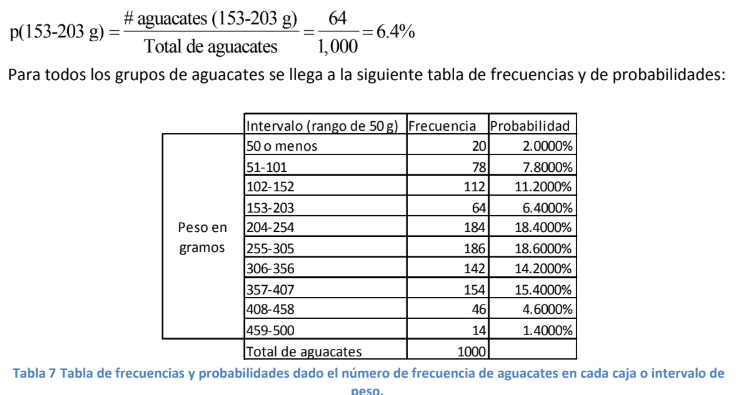{kind=link}
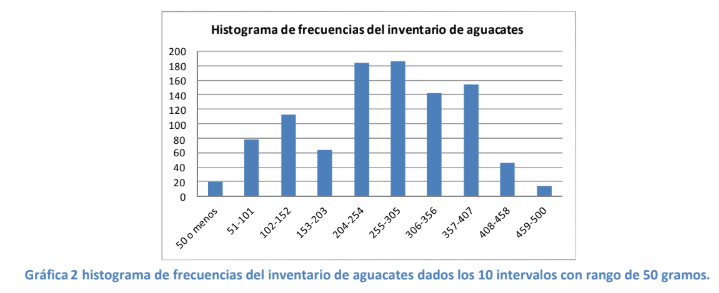{kind=link}
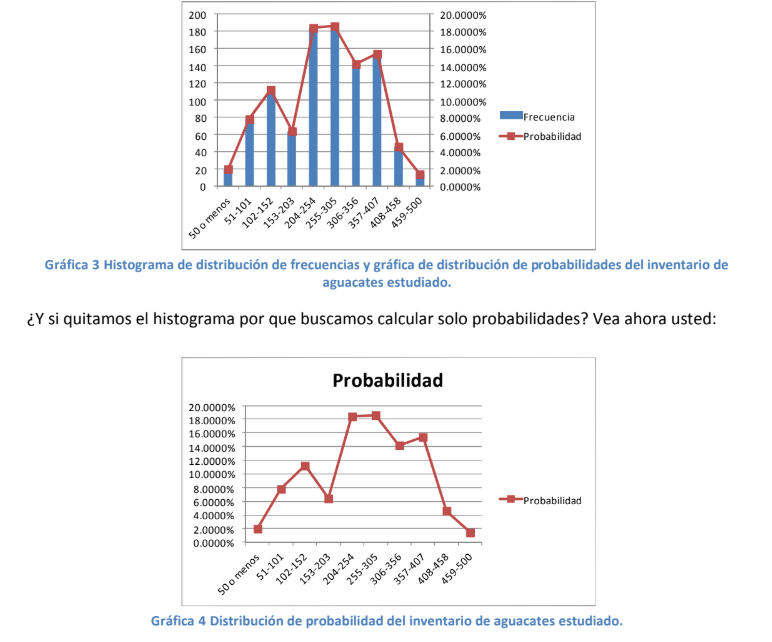{kind=link}
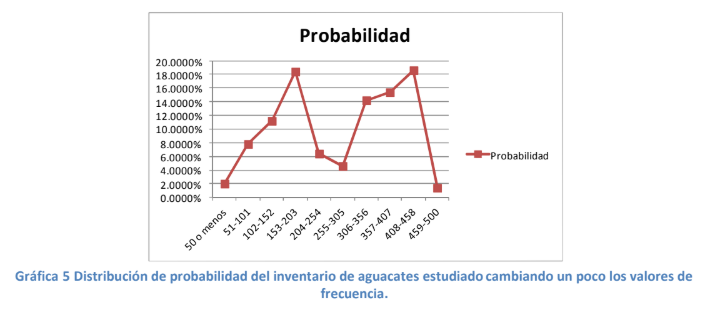{kind=link}
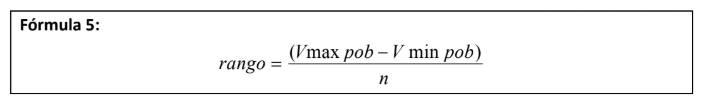{kind=link}
{kind=link}
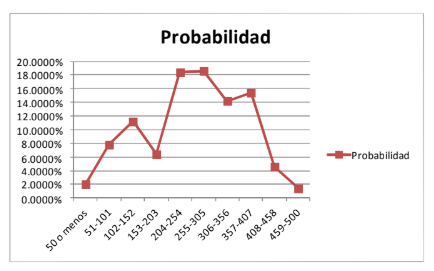{kind=link}
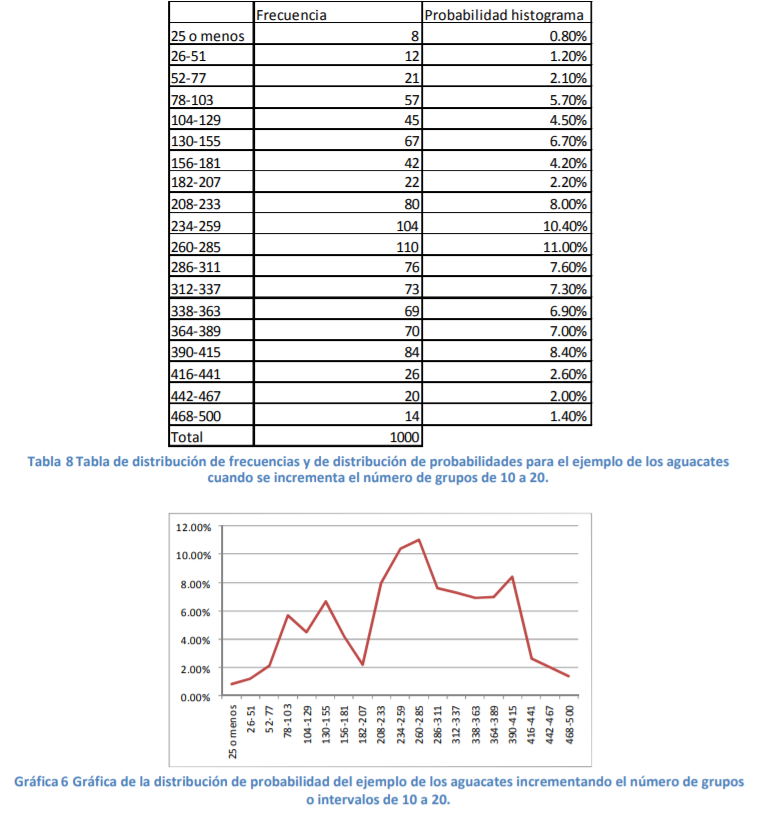{kind=link}
{kind=link}
{kind=link}
{kind=link}
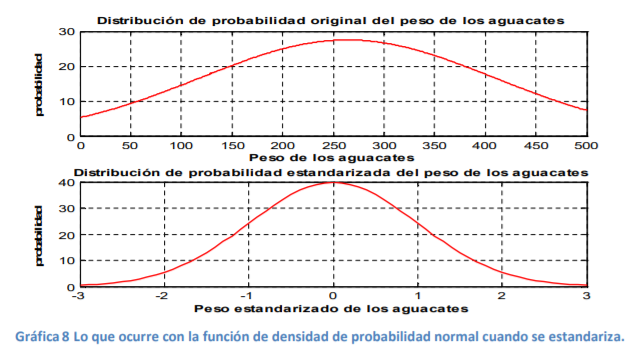{kind=link}
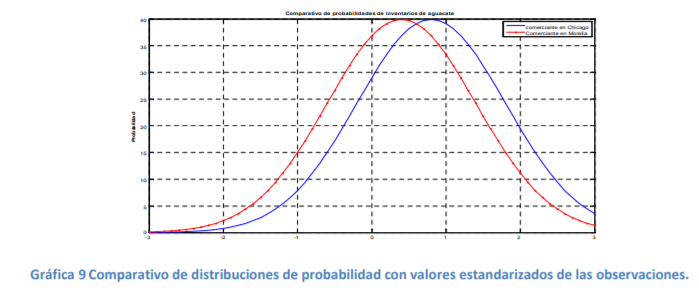{kind=link}
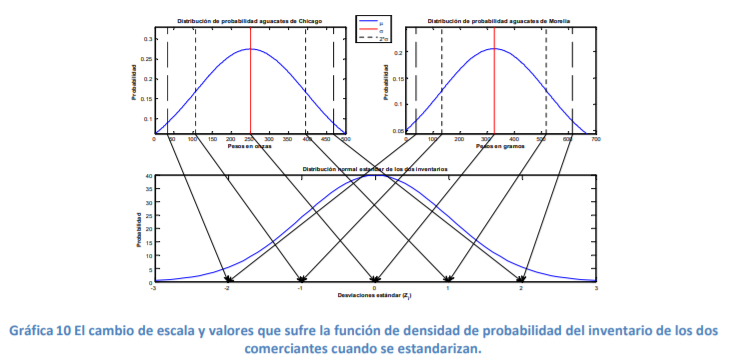{kind=link}
{kind=link}
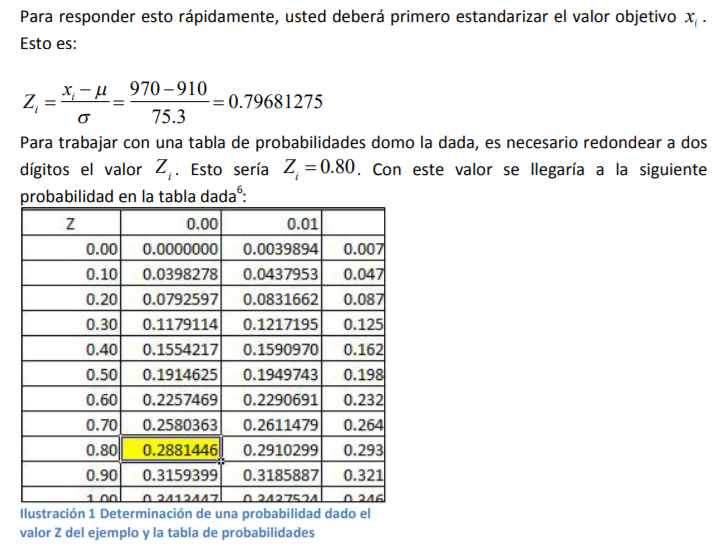{kind=link}
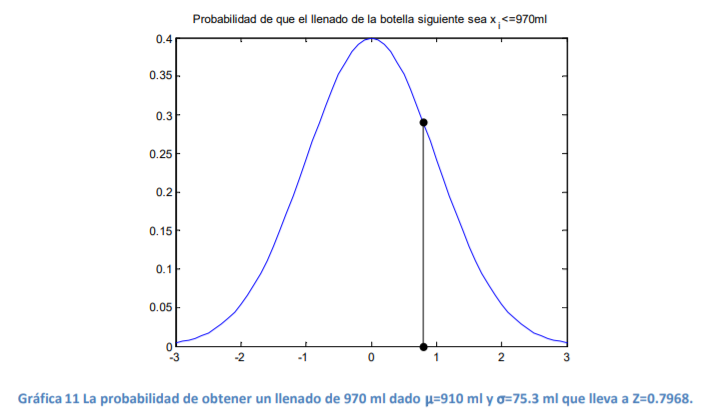{kind=link}
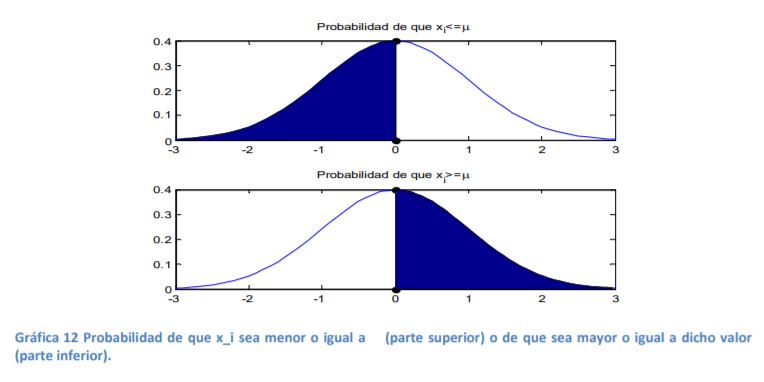{kind=link}
{kind=link}
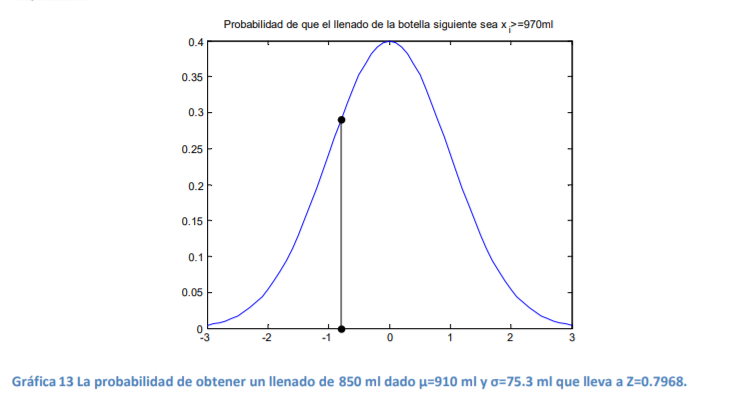{kind=link}
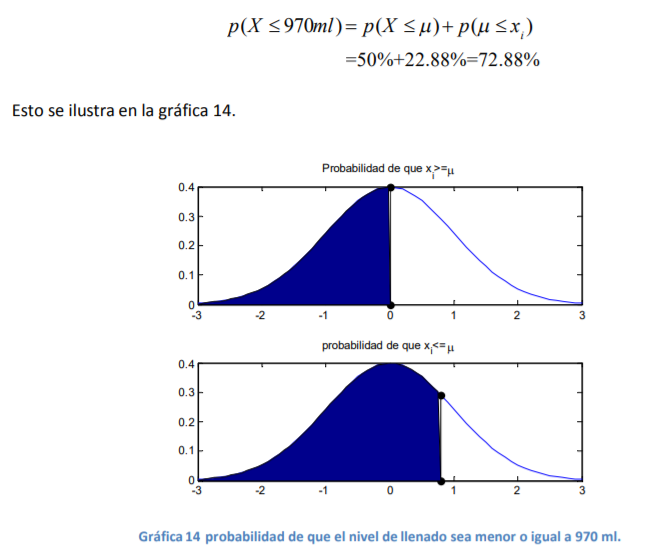{kind=link}
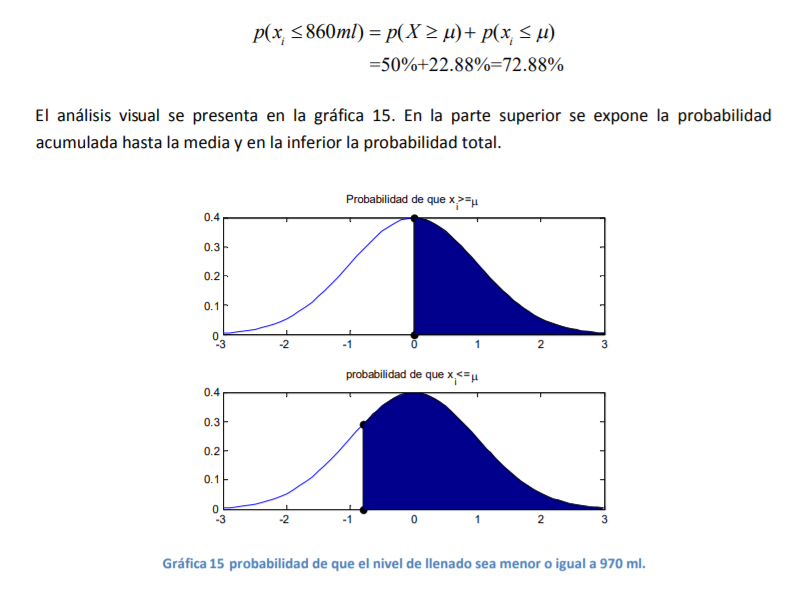{kind=link}
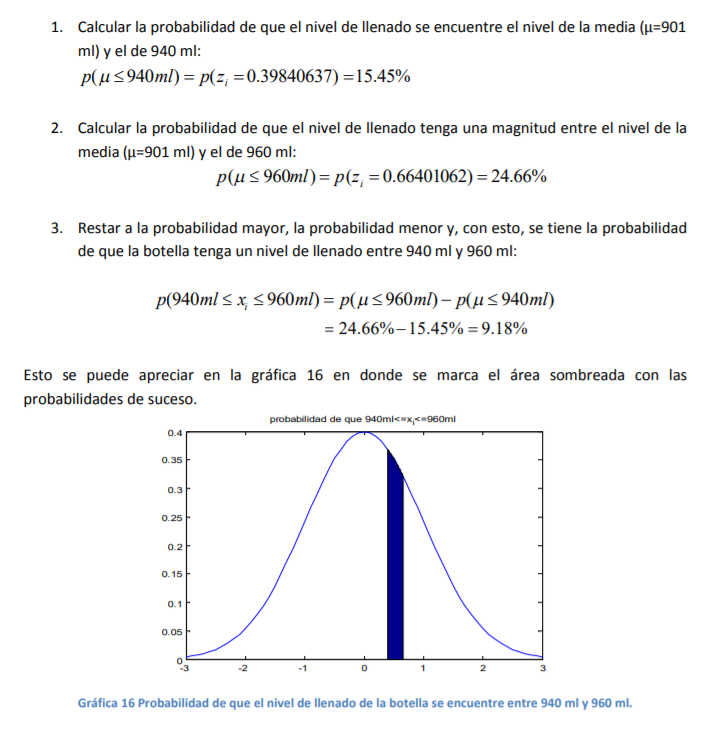{kind=link}
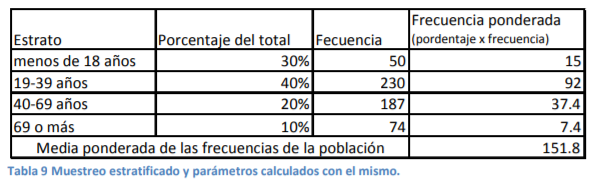{kind=link}
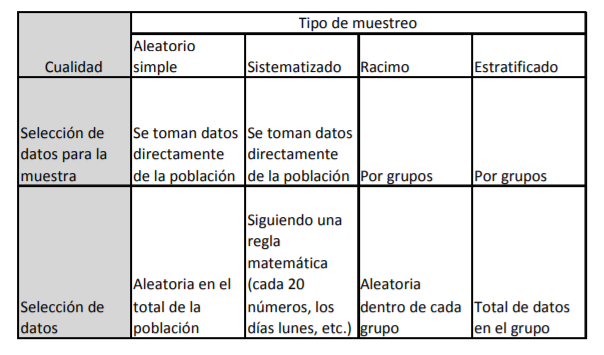{kind=link}
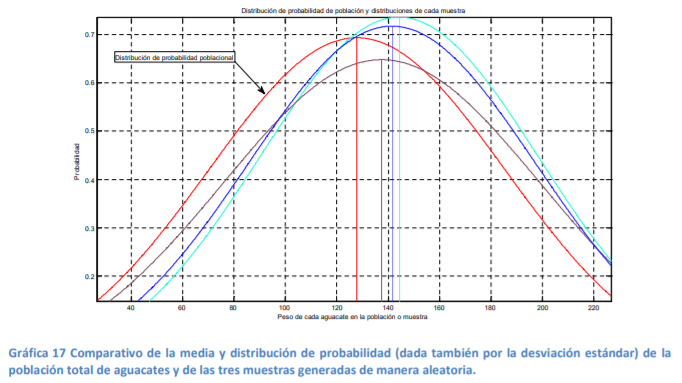{kind=link}
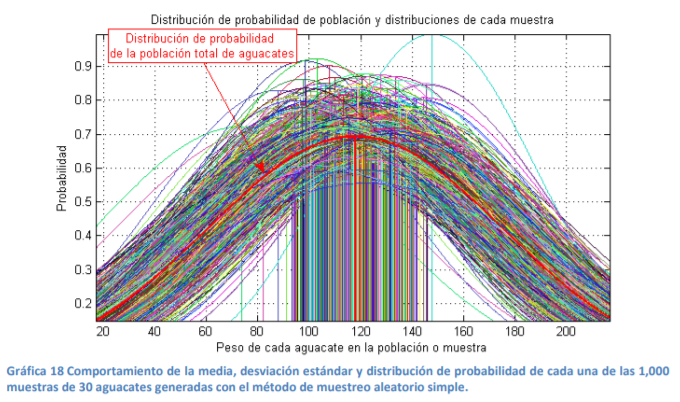{kind=link}
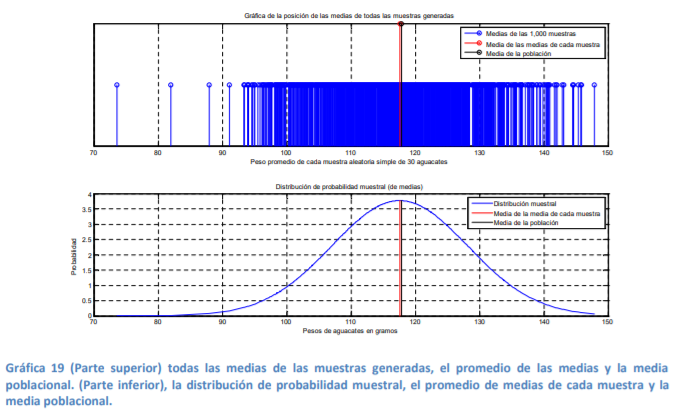{kind=link}
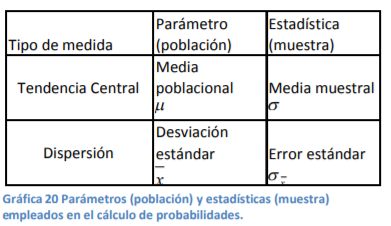{kind=link}
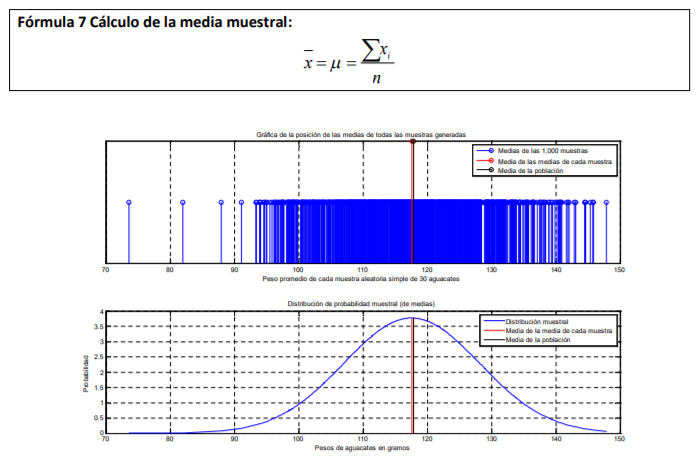{kind=link}
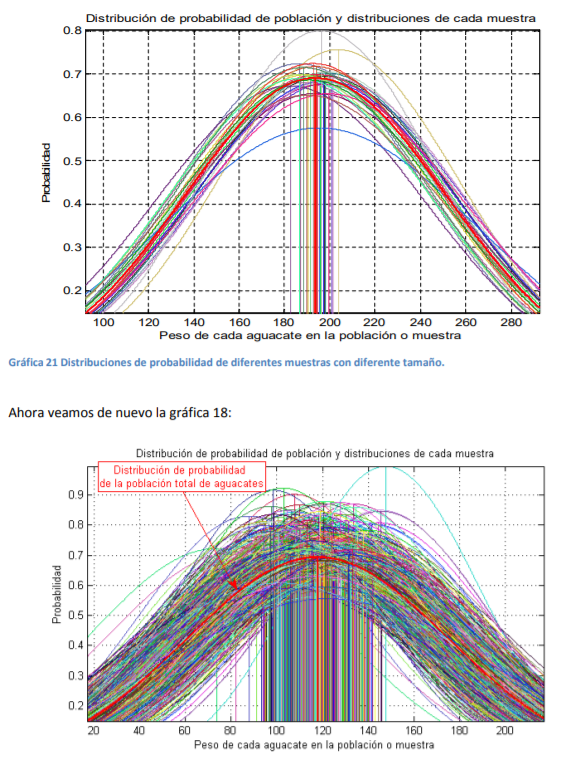{kind=link}
{kind=link}
{kind=link}
{kind=link}
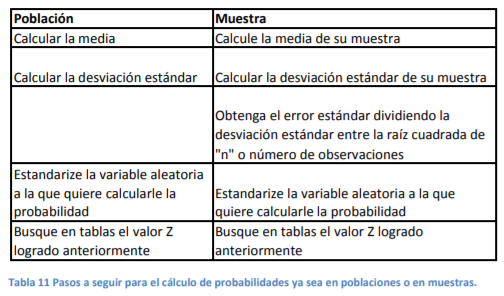{kind=link}
{kind=link}
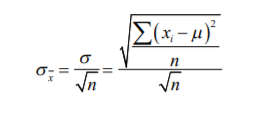{kind=link}
{kind=link}
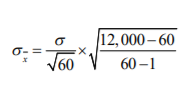{kind=link}
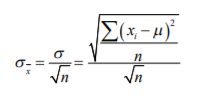{kind=link}
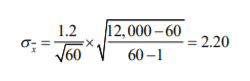{kind=link}
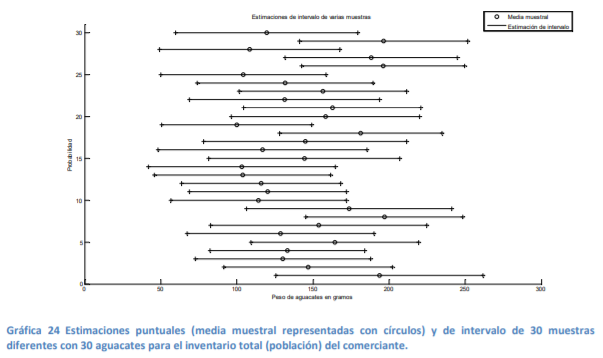{kind=link}
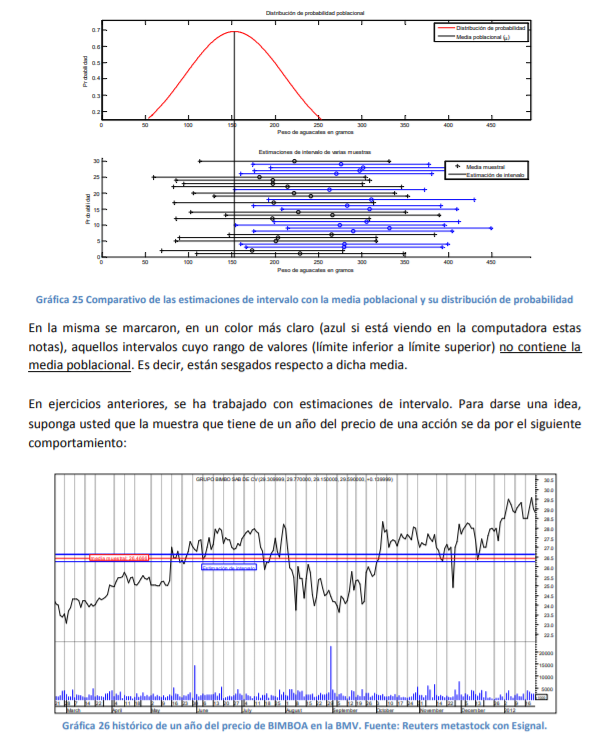{kind=link}
{kind=link}
{kind=link}
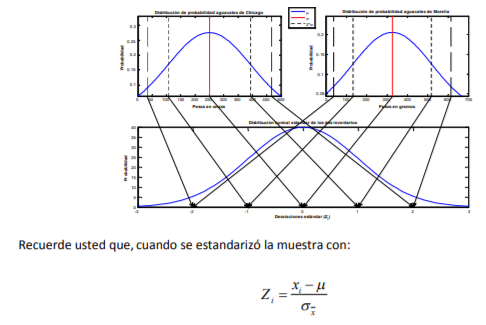{kind=link}
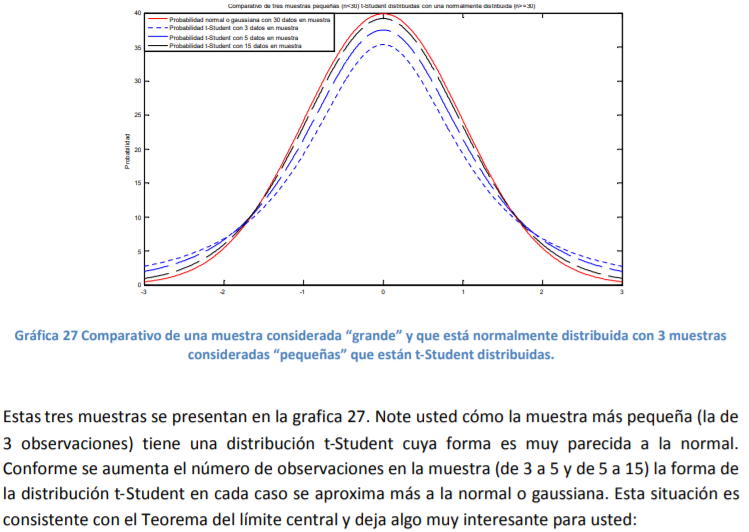{kind=link}
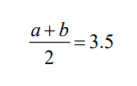{kind=link}
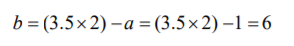{kind=link}
{kind=link}
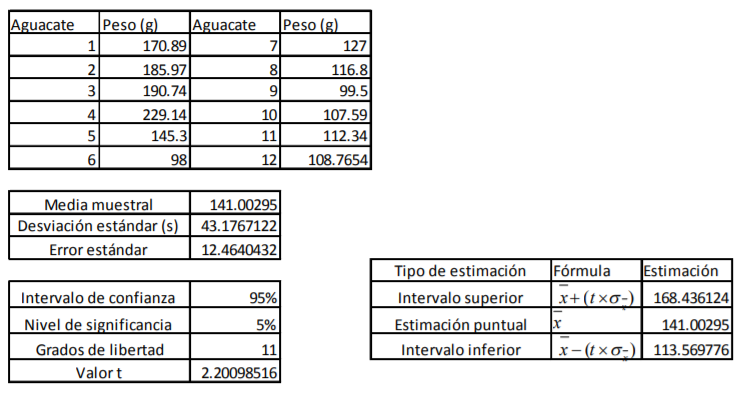{kind=link}
{kind=link}
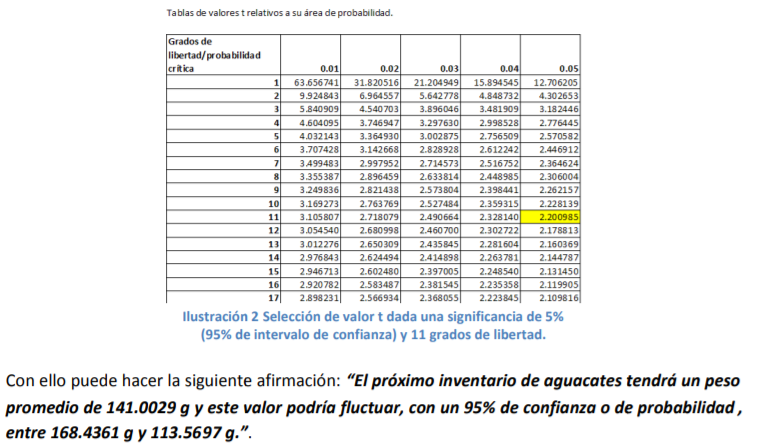{kind=link}
{kind=link}
{kind=link}
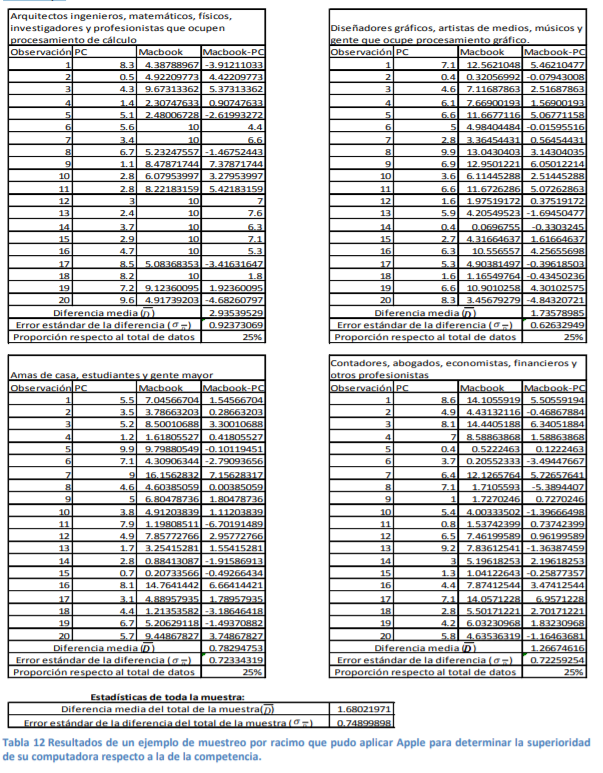{kind=link}
{kind=link}
{kind=link}
{kind=link}
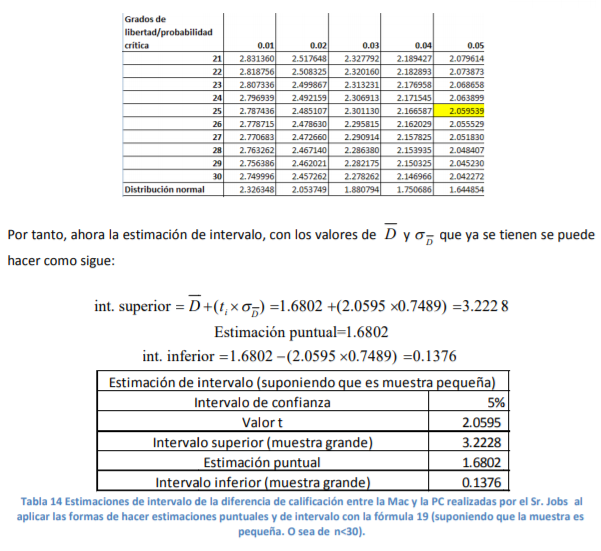{kind=link}
{kind=link}
{kind=link}
{kind=link}
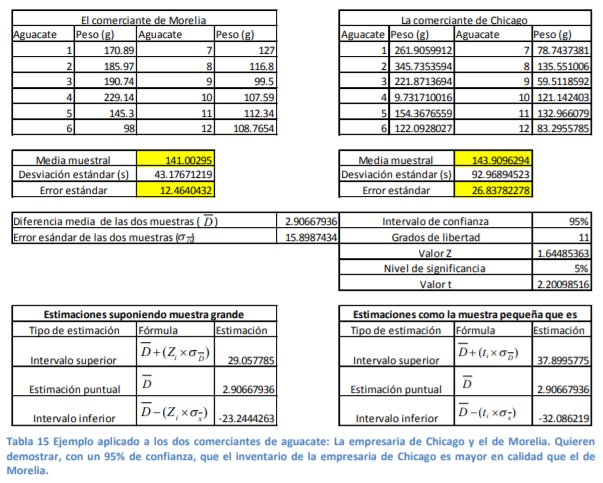{kind=link}
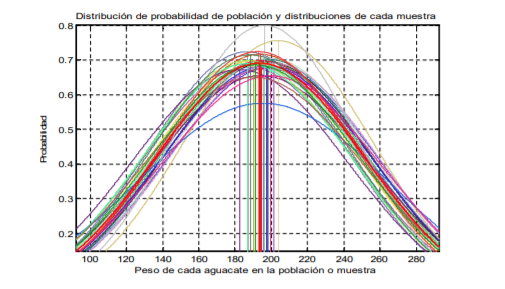{kind=link}
{kind=link}
{kind=link}
{kind=link}
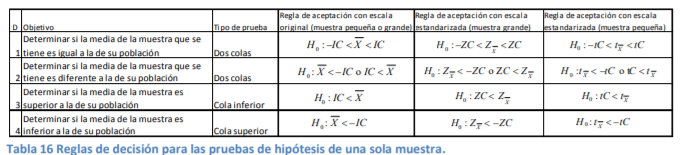{kind=link}
{kind=link}
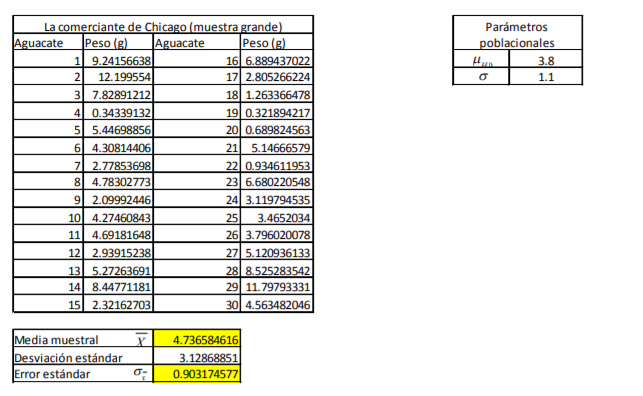{kind=link}
{kind=link}
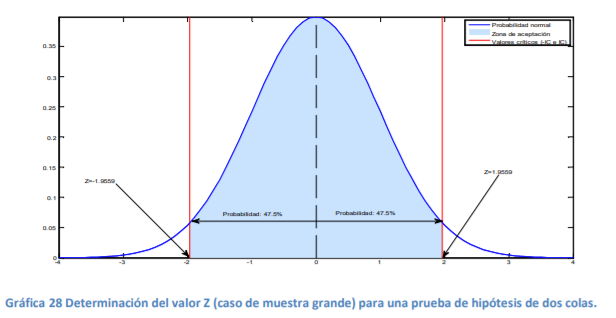{kind=link}
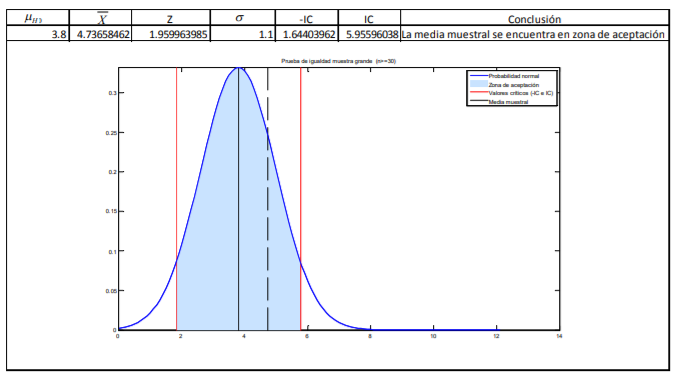{kind=link}
{kind=link}
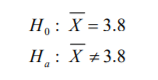{kind=link}
{kind=link}
{kind=link}
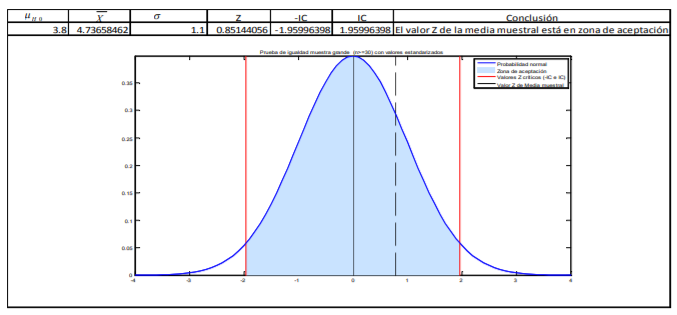{kind=link}
{kind=link}
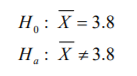{kind=link}
{kind=link}
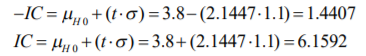{kind=link}
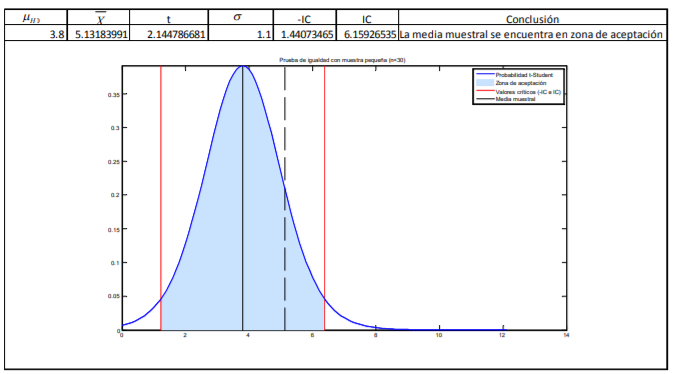{kind=link}
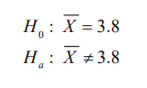{kind=link}
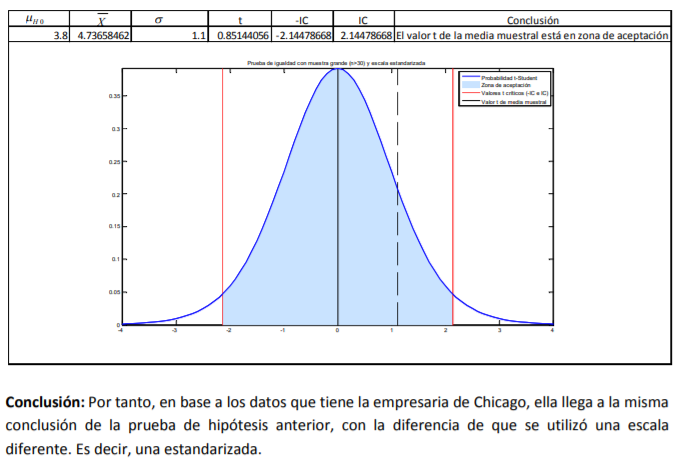{kind=link}
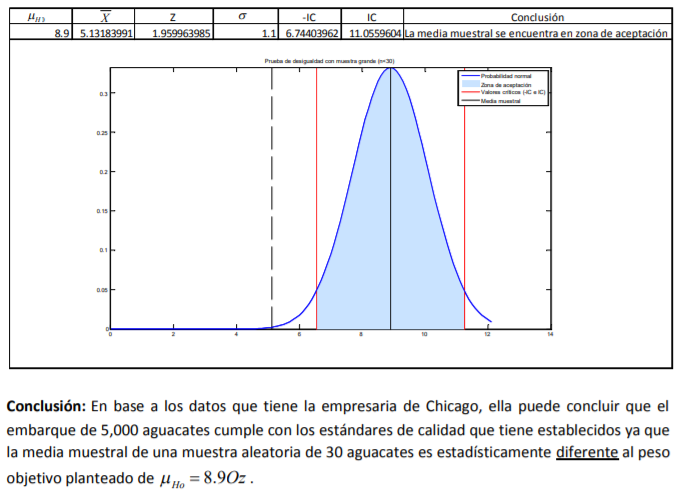{kind=link}
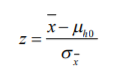{kind=link}
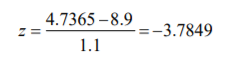{kind=link}
{kind=link}
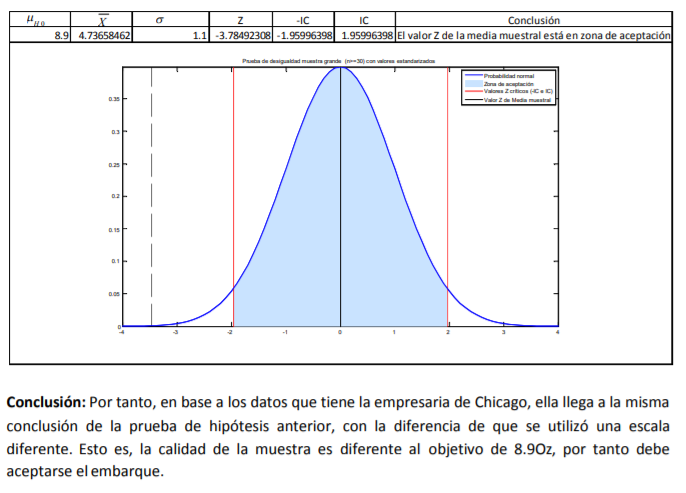{kind=link}
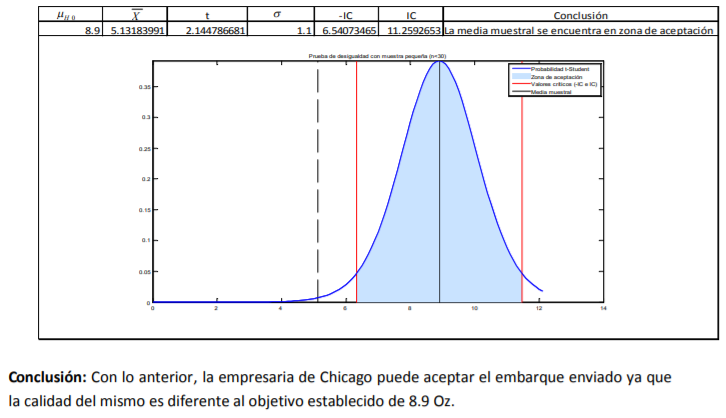{kind=link}
{kind=link}
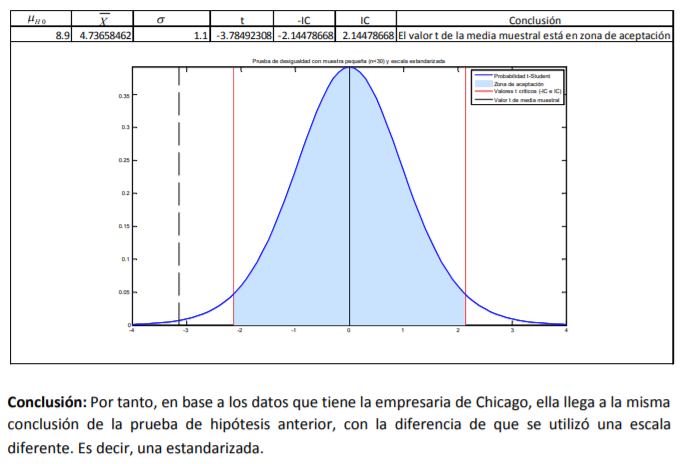{kind=link}
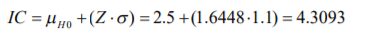{kind=link}
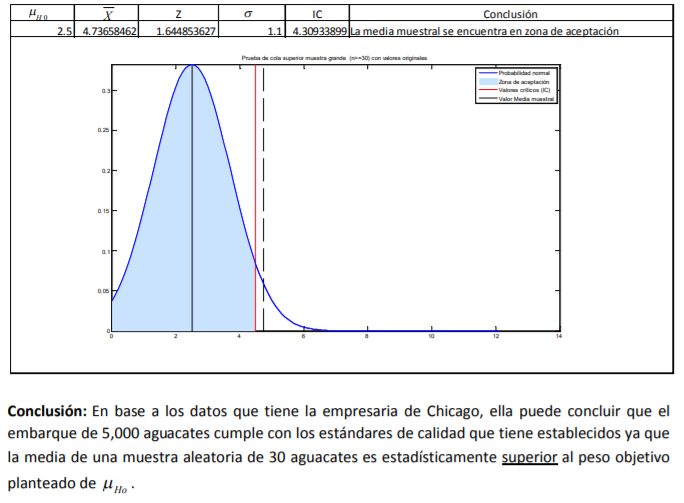{kind=link}
{kind=link}
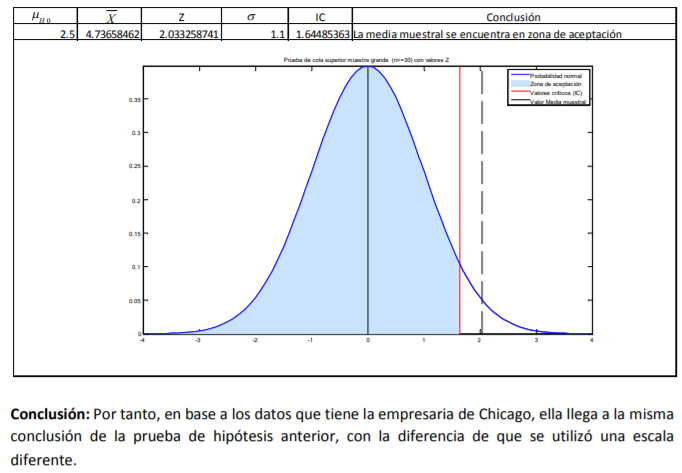{kind=link}
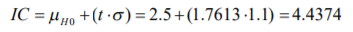{kind=link}
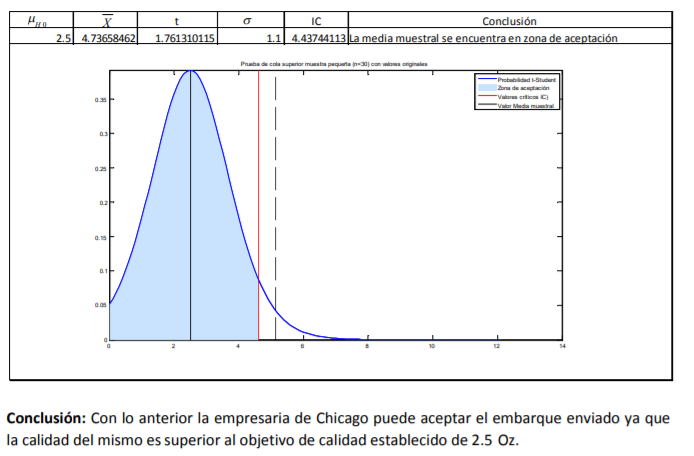{kind=link}
{kind=link}
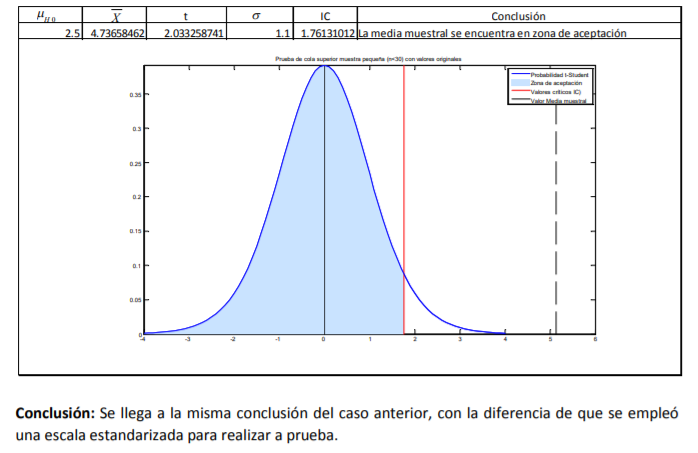{kind=link}
{kind=link}
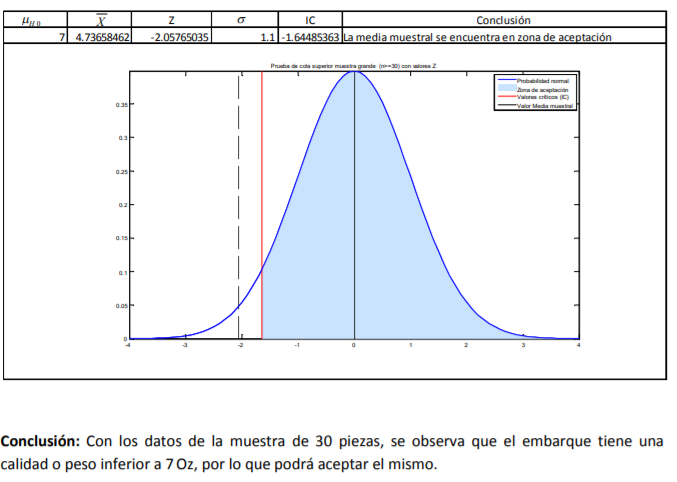{kind=link}
{kind=link}
{kind=link}
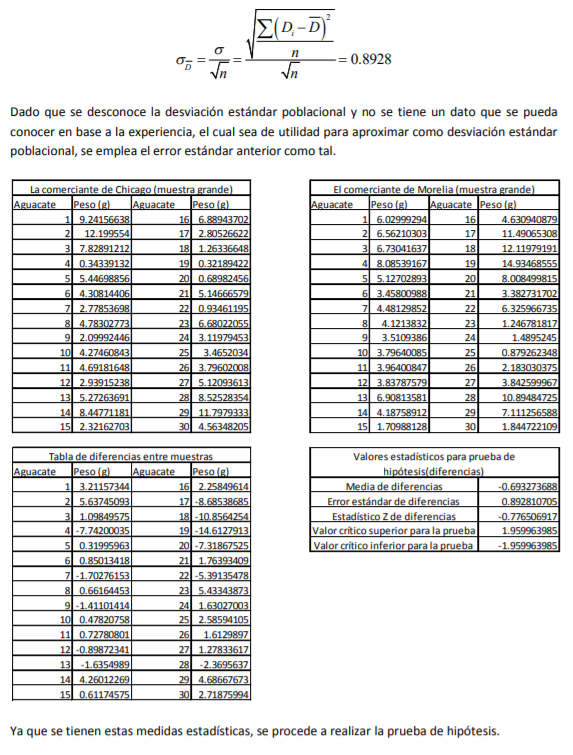{kind=link}
{kind=link}
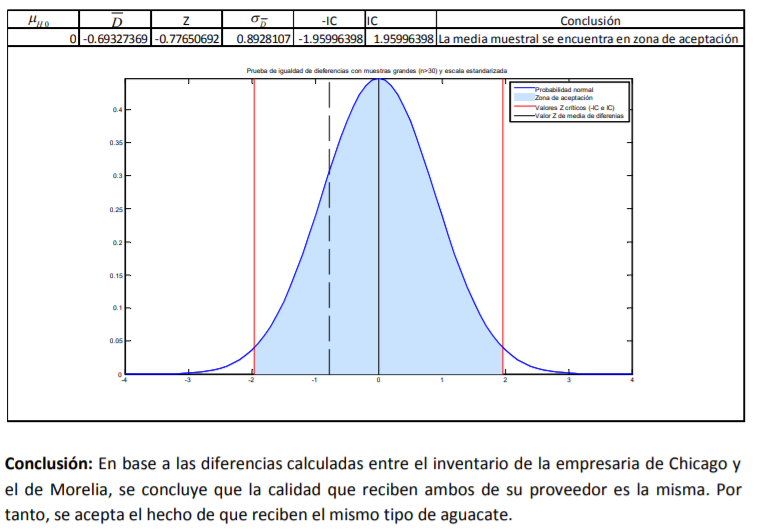{kind=link}
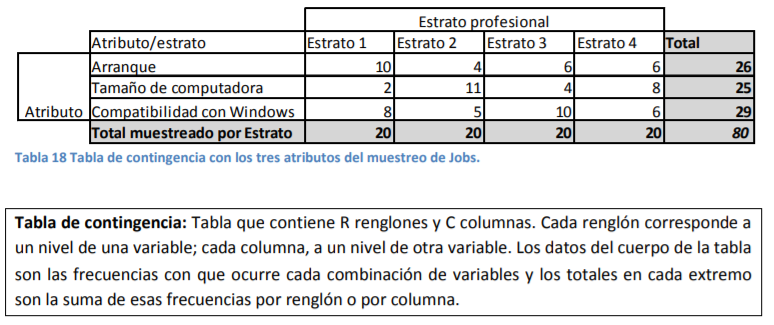{kind=link}
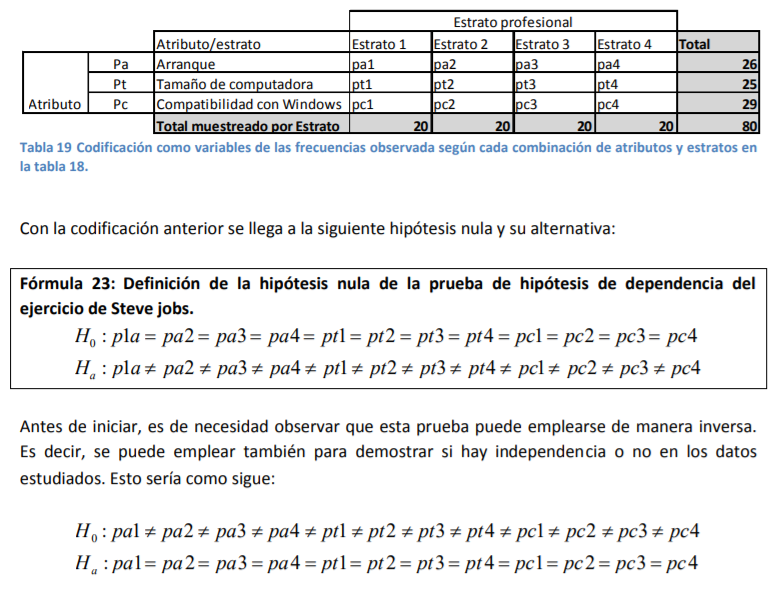{kind=link}
{kind=link}
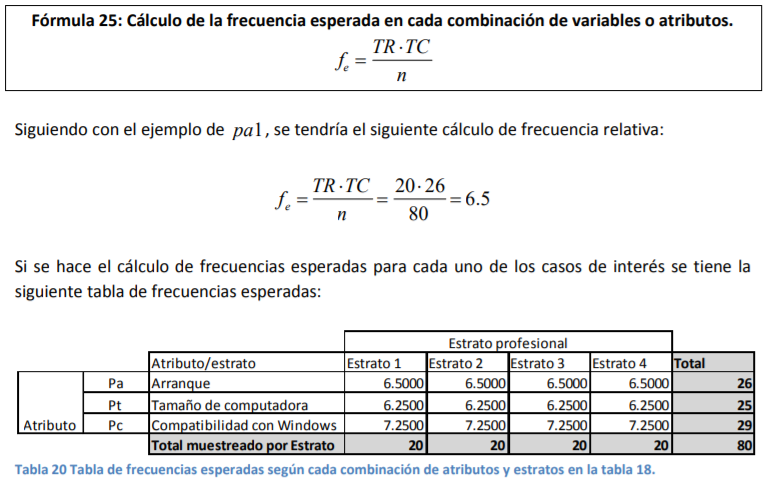{kind=link}
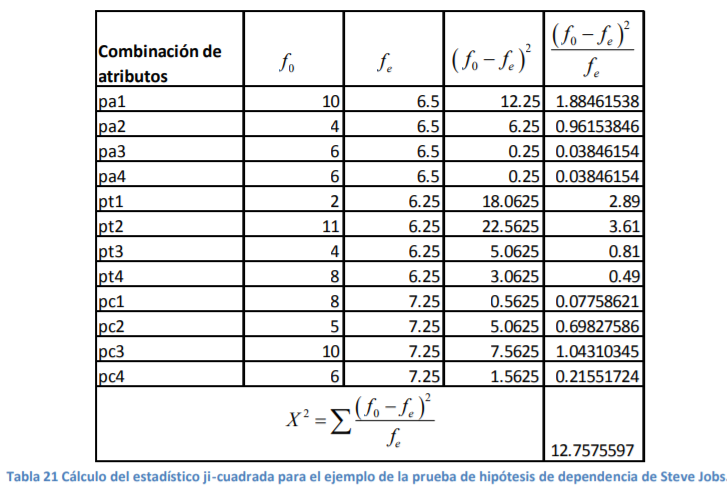{kind=link}
{kind=link}
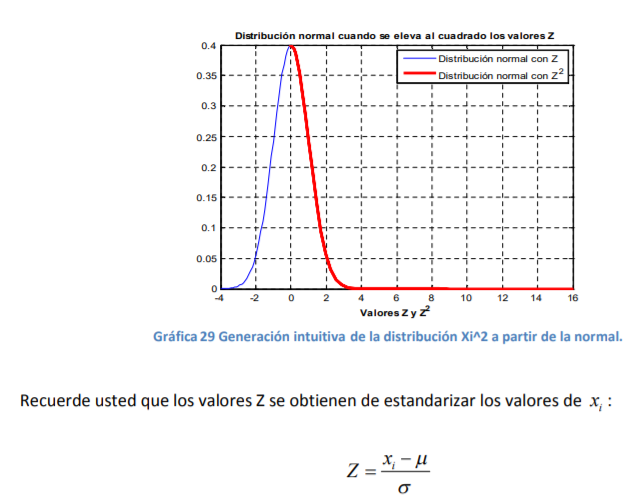{kind=link}
{kind=link}
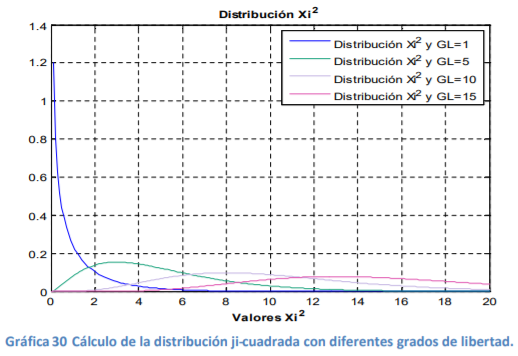{kind=link}
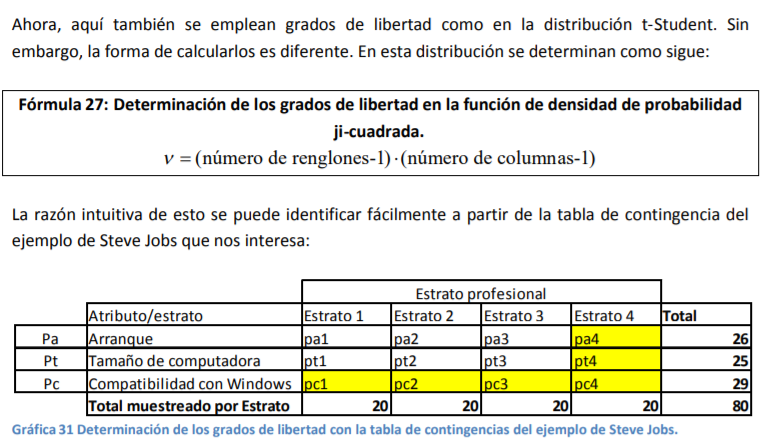{kind=link}
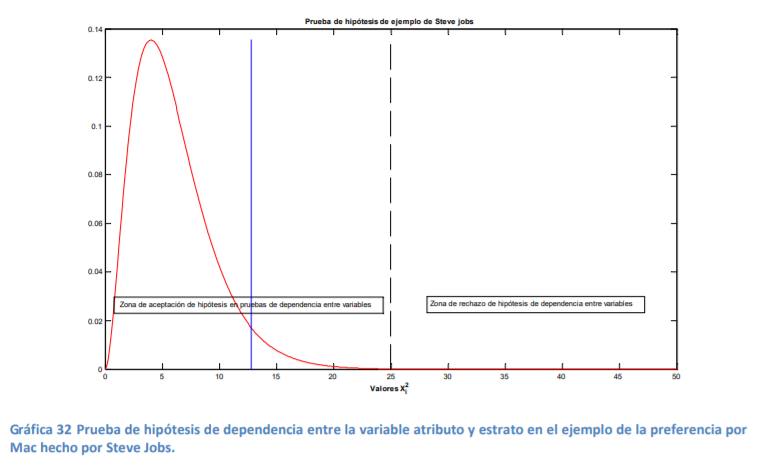{kind=link}
{kind=link}
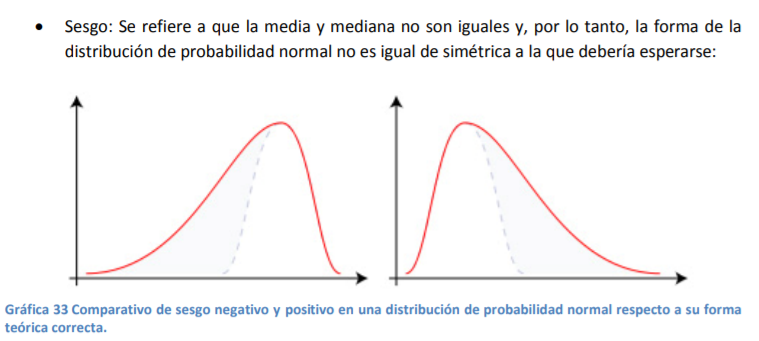{kind=link}
{kind=link}
{kind=link}
{kind=link}
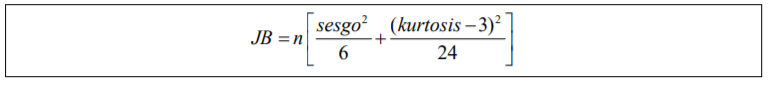{kind=link}
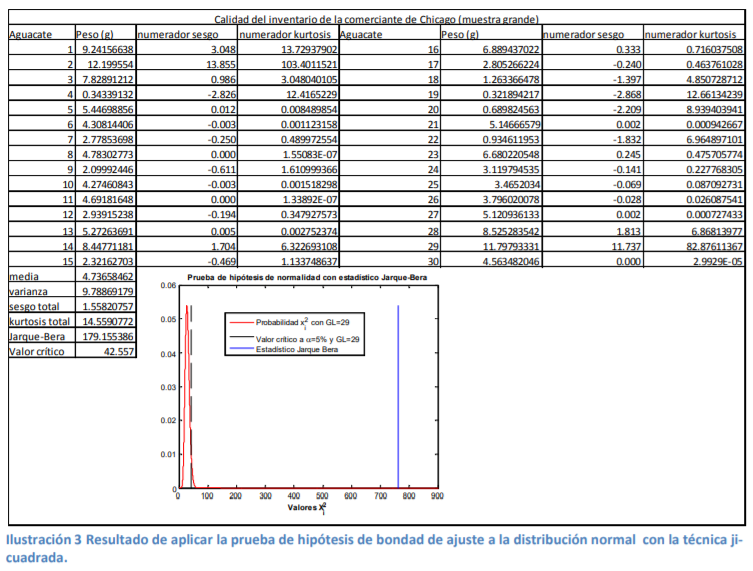{kind=link}
{kind=link}
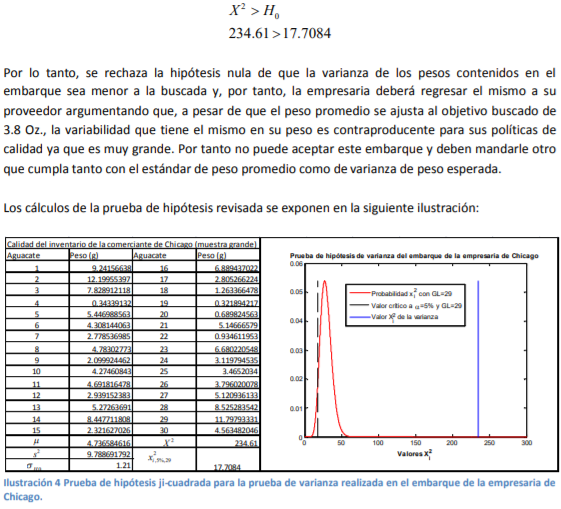{kind=link}
{kind=link}
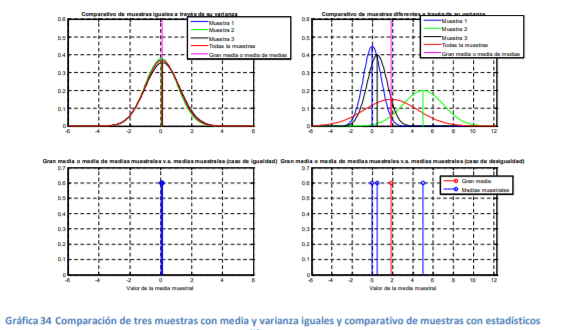{kind=link}
{kind=link}
{kind=link}
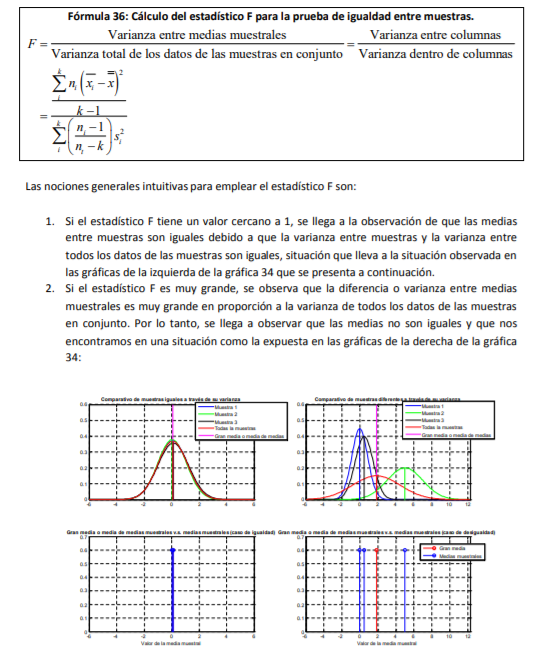{kind=link}
{kind=link}
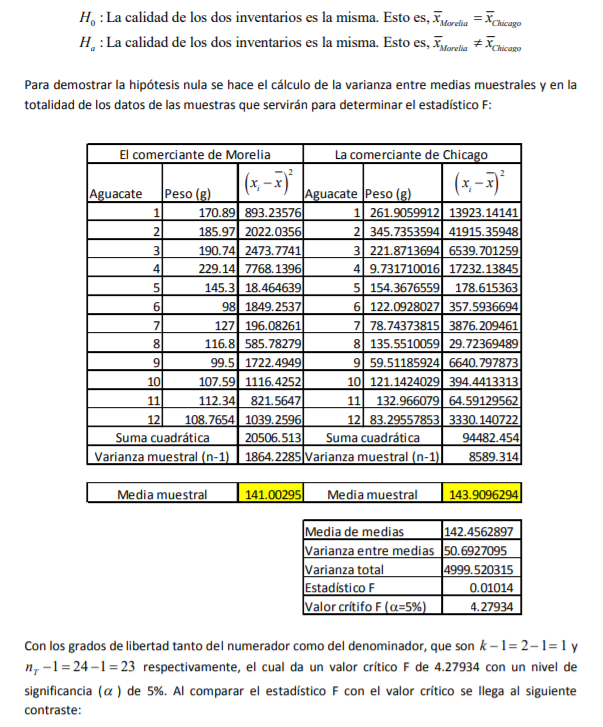{kind=link}
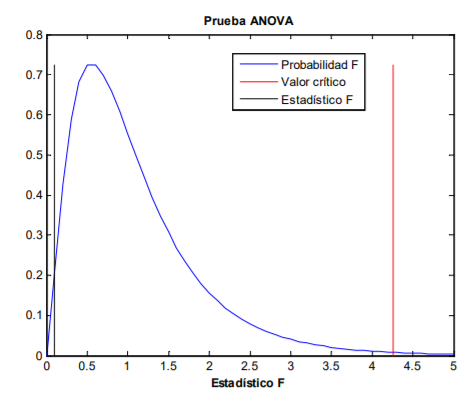{kind=link}
{kind=link}
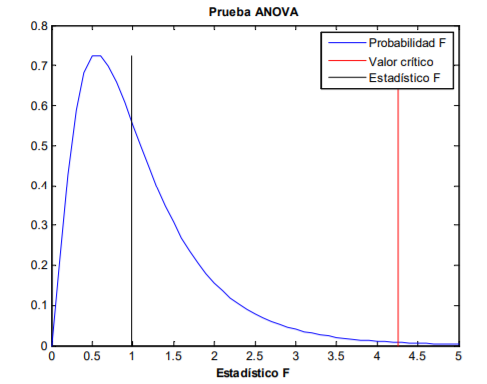{kind=link}
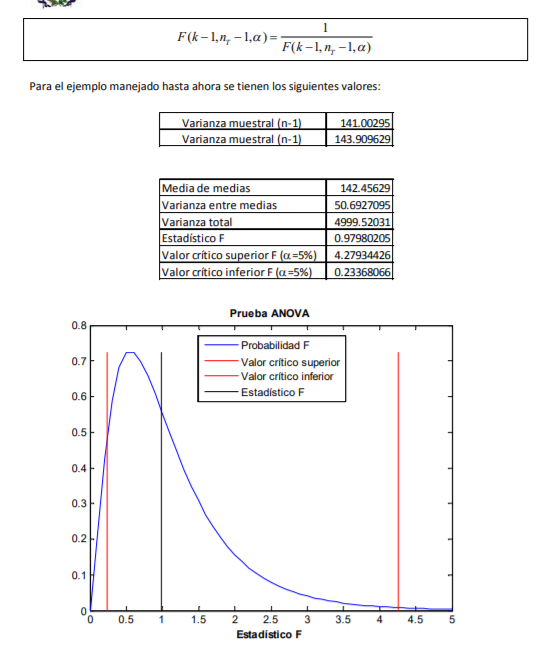{kind=link}
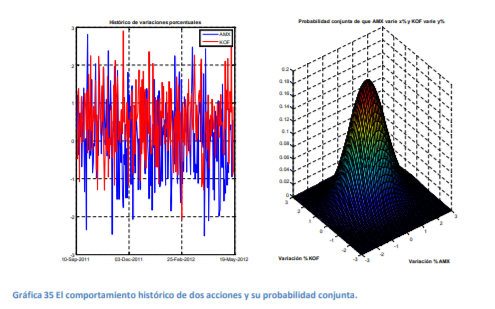{kind=link}
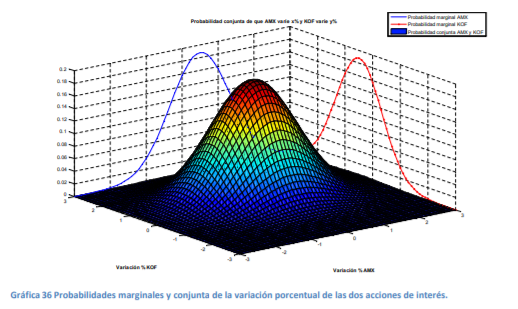{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.