2944910
ESTADISTICA
Annotations:
- a) Estadística Paramétrica. b) Estadística No Paramétrica. La Estadística Paramétrica es un conjunto de técnicas desarrolladas para niveles altos de medición como el de intervalos. Los métodos paramétricos permiten hacer inferencias acerca de parámetros poblacionales de las distribuciones.
- La Estadística no paramétrica es un conjunto de técnicas diseñadas para niveles de medición menores, por ejemplo, el nominal y ordinal, para efectuar estimaciones no habrá parámetros en estricto sentido.
- Descriptiva
- Organiza, resume y describe
las características principales
de los datos.
Annotations:
- Generalmente se resumen en forma tabular, gráfica o numérica. El análisis se limita en si mismo a los datos coleccionados y no se realiza inferencia alguna o generalizaciones acerca de la totalidad de donde provienen esas observaciones.
- Niveles de Medición
Annotations:
- Proceso por el cual asignamos una categoría (o un valor) a una variable, para determinada unidad de análisis.
- Inferencial
- Paso 3
- Paso 3
- Escala: Nominal, Ordinal, Intervalos
y de razón o Proporción.
- NOMINAL:: Permite
clasificar un
objeto,persona o
una característica.
Annotations:
- Equivalencia
- ORDINAL: O DE RANGOS: Establece una relación
de orden entre los elementos (personas,
animales, objetos, etc.), en atención a una
característica, pero no especifica en que medida
Annotations:
- Equivalencia y mayor que. 1. Las observaciones o elementos se les ordena en rangos o categorías diferentes. 2. Las categorías son mayores o menores que otras categorías, es decir, que existe una clasificación de mayor a menor (jerarquía). 3. Las categorías son mutuamente excluyentes y exhaustivas. 4. No presentan el cero.
- INTERVALO:: Tiene las características de la ordinal y a demás
permite conocer la distancia entre dos valores de una
magnitud conocida, lo que le permite a esta escala un mayor
grado de perfección, ya que proporciona números que
manifiestan diferencias palpables entre individuos, objetos o
cosas.
Annotations:
- 1. Esta escala implica la cuantificación de los datos 2. En estás medidas se utilizan unidades constantes de medición (capacidad, peso, céntimos, grados Fahrenheit o centígrados) los cuales producen intervalos iguales entre puntos de la escala. 3. Proporcionan números que manifiestan diferencias palpables entre individuos, objetos o cosas. 4. En esta escala de intervalos el punto cero (0) y la unidad de medida es arbitrario. 5. Se pueden aplicar todas las medidas estadísticas más conocidas, con excepción del coeficiente de variación. 6. Son mutuamente exclusivas y exhaustivas.
- RAZÓN :constituye el nivel más alto de medición,
posee todas las características de las escalas
nominales, ordinales y de intervalos; además tiene
un cero absoluto tiene significado físico. Si en ella la
medición es cero, significa ausencia o inexistencia
total de la propiedad considerada.
Annotations:
- 1. La distancia entre los números es un tamaño conocido y constante. 2. Los datos tienen un punto cero significativo. 3. Puede utilizarse cualquier prueba de tipo estadístico, incluyendo el coeficiente de variación. 4. Permite hacer comparaciones entre los números verdaderos con un cero aritmético siendo arbitrario únicamente la unidad de medida.
- NOMINAL:: Permite
clasificar un
objeto,persona o
una característica.
- Medidas de: tendencia
central, dispersión,, posición
- MODA: Es el dato o
valor que más se
repite, o sea, el de
mayor frecuencia.
- MEDIANA: Es el dato o valor que
divide por la mitad la serie de
datos ordenados creciente o
decrecientemente, es decir, es el
valor central de la serie.
Annotations:
- 1. Esta influenciada por valores extremos, esto puede generar asimetrías positivas o negativas, (- o izq. cuando la media < mediana y + o derecha cuando media > mediana). es decir la media es vulnerable a los valores extremos e indican la proporción de los casos hacia un lado u otro en una distribución normal.
- MEDIA: Es el promedio
aritmético de todos los
datos o valores.
- MEDIANA: Es el dato o valor que
divide por la mitad la serie de
datos ordenados creciente o
decrecientemente, es decir, es el
valor central de la serie.
- MTC
- DISPERSIÓN
- RANGO: Es la diferencia
entre los valores máximo
y mínimo de la variable.
- VARIANZA: nos permite identificar la
diferencia promedio que hay entre
cada uno de los valores respecto a
su punto central (media x).
Annotations:
- 1. Nos indica el grado de variabilidad (dispersión) respecto a la media. 2. El grado de variabilidad se relaciona con el tamaño de la muestra.
- DESVIACIÓN ESTÁNDAR: permite determinar el promedio
aritmético de fluctuación de los datos respecto a la media.
nos da como resultado un valor numerico que representa
el promedio de diferencia que hay ente los datos y la
media.
Annotations:
- 1. La desviación estándar no incide en la proporción de casos de un lado u otro en una distribución normal, pero si indica la curtosis. 2. La curtosis hace referencia a la forma de la curva de la distribución de datos en tanto muy aguda (mayor apuntamiento o mayor curtosis: leptocúrtica) o muy aplanada (menor apuntamiento o menor curtosis: platicúrtica).
- COEFICIENTE DE
VARIACIÓN:: Indica el
grado de homogeneidad
y heterogeneidad
Annotations:
- 1. Es el cociente entre la desviación estándar y la media aritmética. CV= (S/media) (100) 2. si CV> 20% mayor heterogeneidad (mas dispersión),si CV< 20% mayor homogeneidad (menor dispersión). 3. Puede considerarse como un índice de la representatividad de la media aritmética: cuanto mayor es el coeficiente de variación, menos representativa es la media
- VARIANZA: nos permite identificar la
diferencia promedio que hay entre
cada uno de los valores respecto a
su punto central (media x).
- RANGO: Es la diferencia
entre los valores máximo
y mínimo de la variable.
- POSICIÓN
- CUARTILES: Valores que
dividen la serie en cuatro
partes iguales. Por tanto,
hay 3 cuartiles: Q1, Q2 y
Q3
- DECILES:: Valores que dividen la
serie en diez partes iguales. Por
tanto, hay 9 deciles: desde el D1
hasta el D9
- PERCENTILES: Valores
que dividen la serie en
cien parte iguales. Por
tanto, hay 99 percentiles:
desde el P1 hasta el P99
- PERCENTILES: Valores
que dividen la serie en
cien parte iguales. Por
tanto, hay 99 percentiles:
desde el P1 hasta el P99
- DECILES:: Valores que dividen la
serie en diez partes iguales. Por
tanto, hay 9 deciles: desde el D1
hasta el D9
- CUARTILES: Valores que
dividen la serie en cuatro
partes iguales. Por tanto,
hay 3 cuartiles: Q1, Q2 y
Q3
- MODA: Es el dato o
valor que más se
repite, o sea, el de
mayor frecuencia.
- Paso 1.
- Organiza, resume y describe
las características principales
de los datos.
- Permite inferir una conclusión acerca de la
población, con un cierto nivel de confianza (o,
complementariamente, con un cierto nivel de
error).procede a formular estimaciones y probar
hipótesis acerca de la población a partir de los
datos resumidos y obtenidos de la muestra.
Annotations:
- Clásicamente, la estadística inferencial se ocupa de dos cuestiones: la estimación de parámetros y la prueba de hipótesis, aunque “por lo general, la mayoría de las aplicaciones de la estadística inferencial pertenecen al área de la prueba de hipótesis
- parametros
- Prueba de hipotesis
- constituyen un proceso
relacionado con aceptar o
rechazar alguna afirmación
acerca de los parámetros de
la población.
- Formular la Hipótesis
nula (Ho) y la hipótesis
alterna (H1)
Annotations:
- Ho: Negación del punto que se esta tratando de probar H1: Es la aseveración (hipótesis)que se acepta si se rechaza Ho.
- Selección de
la prueba
Annotations:
- Existen numerosaspruebas de hipótesis y su elección “depende de la hipótesis alternativa que se formule, del número de casos examinados, del nivel de medición utilizado, etc
- nivel de significación:
valores comunes de
alfa 0.05 y 0.01
Annotations:
- Cada investigador elige su nivel de significación, es decir, su probabilidad de equivocarse en el sentido indicado.
- Error de tipo II: probabilidad de
aceptar la (Ho) cuando es falsa
- Error de tipo I:
Probabilidad de rechazar
la Ho cuando es
verdadera.
- Distribución muestral: distribución de los
posibles valores que algún estadístico puede
tomar siendo (Ho)
- zona de rechazo: conjunto de
valores posibles que son tan
extremos que cuando (Ho) es
verdadera la probabilidad es muy
pequeña.
- Decisión final: si la prueba estadística
proporciona un valor que cae en la región de
rechazo, rechazamos (H0)
- Decisión final: si la prueba estadística
proporciona un valor que cae en la región de
rechazo, rechazamos (H0)
- zona de rechazo: conjunto de
valores posibles que son tan
extremos que cuando (Ho) es
verdadera la probabilidad es muy
pequeña.
- Formular la Hipótesis
nula (Ho) y la hipótesis
alterna (H1)
- constituyen un proceso
relacionado con aceptar o
rechazar alguna afirmación
acerca de los parámetros de
la población.
- PROBABILIDAD Y CURVA NORMAL
Annotations:
- La curva normal es uno de los temas fundamentales de la estadística que utiliza la información provista por la estadística descriptiva y permite el paso a la estadística inferencial en el sentido de proveer una herramienta para obtener conclusiones respecto de la población. La comprensión de este tema exige un conocimiento mínimo de la teoría de la probabilidad.
- Paso 2.
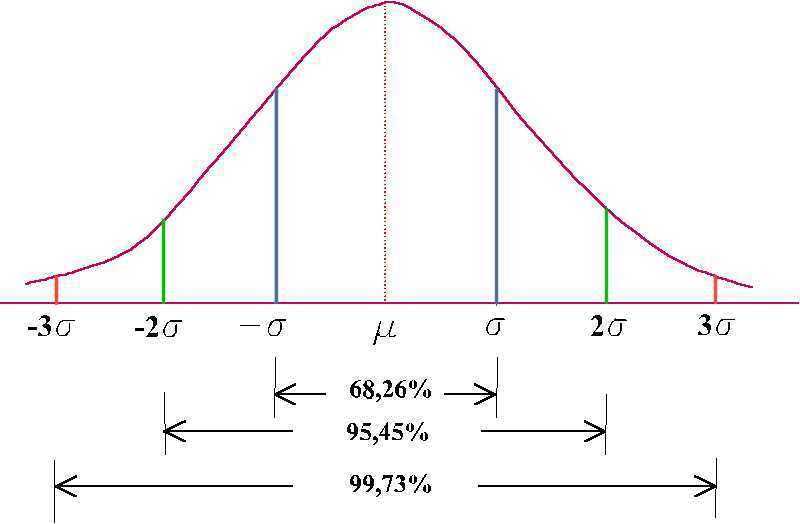
- Distribución normal: Está caracterizada por dos parámetros: la media, μ y
la desviación típica, σ. Está comprobado que en una curva normal,
idealmente, alrededor de un 68% de los casos posibles están comprendidos
entre menos una desviación estándar y más una desviación estándar
alrededor de un 95% están comprendidos entre menos 2 y más dos
desviaciones estándar y alrededor de un 99% están comprendidos entre
menos tres y más tres desviaciones.
- DISTRIBUCIÓN DE UNA CURVA NORMAL
- DISTRIBUCIÓN DE UNA CURVA NORMAL
- Probabilidad: Se entiende por
probabilidad el grado de posibilidad
de ocurrencia de un determinado
acontecimiento.
Annotations:
- 1. Probabilidad clásica.- Suele también denominarse probabilidad teórica o a priori, y se define como el cociente entre el número de casos favorables y el número de casos equiprobables posibles. (la probabilidad de obtener un 3 en un dado) 2. Probabilidad frecuencial.- Suele también denominarse probabilidad empírica o a posteriori, y es definible como el cociente entre el números de casos favorables y el número de casos observados.
- CORRELACIÓN Y REGRESIÓN
- Su análisis permite averiguar el tipo y el grado
de asociación estadística entre dos o más
variables, mientras que el análisis de regresión
permite hacer predicciones sobre la base de la
correlación detectada, es decir, una vez realizado
el análisis de correlación, pueden obtenerse dos
resultados: que haya correlación o que no la haya.
Si hay correlación, entonces se emprende un
análisis de regresión, consistente en predecir
cómo seguirán variando esas variables según
nuevos valores.
Annotations:
- 1. En general el análisis de correlación se realiza conjuntamente con el análisis de regresión. Mientras el análisis de correlación busca asociaciones, el análisis de regresión busca predicciones, es decir, predecir el comportamiento de una variable a partir del comportamiento de la otra. Así, la correlación y la regresión están íntimamente ligadas.
- 2. en el contexto de un estudio científico, no basta con determinar el grado de correlación entre dos variables en una muestra. Es necesario además establecer, mediante una prueba de significación (por ejemplo la prueba „t‟), si la correlación establecida en la muestra puede extenderse a toda la población con un determinado nivel de confianza. Esta tarea corresponderá a la estadística inferencial.
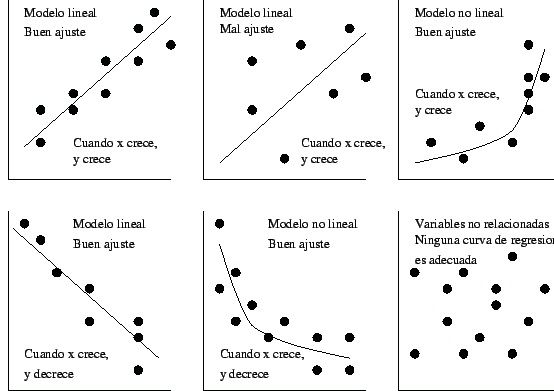
- La correlación lineal se calcula analíticamente
mediante ciertos coeficientes, que serán
distintos según se trate de correlacionar
variables nominales, ordinales o
cuantitativas, y según se trate de otras
consideraciones varias.
Annotations:
- 1. También existen las correlaciones espurias, es decir que no se pueden explicar teóricamente.
- El coeficiente de Pearson (R) es un número
comprendido entre -1 y +1, y que posee un determinado
signo (positivo o negativo). El valor numérico indica
„cuanta‟ correlación hay, mientras que el signo indica qué
„tipo‟ de correlación es (directa si el signo es positivo,
inversa si es negativo).
Annotations:
- En las ciencias sociales 1. (+/- 0.1, +/- 0.2: correlación nula)2. (+/- 0.3, +/- 0.4: correlación media) 3. (+/- 0.5, +/- 0.7: alta correlación)
- Coeficiente (Rho) de Spearman: es el
coeficiente de Pearson aplicado a
variables ordinales y de intervalo
- el Coeficiente (Tau) de Kendall para variables ordinales.
- el Coeficiente (Tau) de Kendall para variables ordinales.
- Análisis de regresión
Annotations:
- Su objetivo es establecer una predicción acerca del comportamiento de una variable Y conociendo el correspondiente valor de X (o viceversa) y el grado de correlación existente entre ambas variables. Para ello es preciso conocer la llamada recta de regresión (7), que es la recta imaginaria que mejor representa el conjunto de pares de valores de las variables X e Y.
- consiste en averiguar la ecuación de la
recta de regresión. Ello permitirá realizar
predicciones en base a dicha ecuación
Annotations:
- Mediante: 1. Mínimos cuadrados ordinarios 2. Método de las desviaciones
- Su análisis permite averiguar el tipo y el grado
de asociación estadística entre dos o más
variables, mientras que el análisis de regresión
permite hacer predicciones sobre la base de la
correlación detectada, es decir, una vez realizado
el análisis de correlación, pueden obtenerse dos
resultados: que haya correlación o que no la haya.
Si hay correlación, entonces se emprende un
análisis de regresión, consistente en predecir
cómo seguirán variando esas variables según
nuevos valores.
Media attachments
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.