6888893
Description
Mind Map by Rafael Lozano, updated more than 1 year ago
|
|
Created by Rafael Lozano
over 7 years ago
|
|
DataWarehouse
- HEFESTO
- HEFESTO es una metodología propia, cuya propuesta está
fundamentada en una muy amplia investigación, comparación de
metodologías existentes, experiencias propias en procesos de
confección de almacenes de datos.
Annotations:
- Cabe destacar que HEFESTO está en continua evolución, y se han tenido en cuenta, como gran valor agregado, todos los feedbacks que han aportado quienes han utilizado esta metodología en diversos países y con diversos fines.
- Los objetivos y resultados esperados en cada fase se distinguen fácilmente y son
sencillos de comprender. Se basa en los requerimientos de l@s usuari@s, por lo
cual su estructura es capaz de adaptarse con facilidad y rapidez ante los cambios
en el negocio. Reduce la resistencia al cambio, ya que involucra a l@s usuari@s
finales en cada etapa para que tome decisiones respecto al comportamiento y
funciones del DW. Utiliza modelos conceptuales y lógicos, los cuales son sencillos
de interpretar y analizar. Es independiente del tipo de ciclo de vida que se emplee
para contener la metodología. Es independiente de las herramientas que se
utilicen para su implementación. Es independiente de las estructuras físicas que
contengan el DW y de su respectiva distribución. Cuando se culmina con una
fase, los resultados obtenidos se convierten en el punto de partida para llevar a
cabo el paso siguiente. Se aplica tanto para Data Warehouse como para Data
Mart.
- La ventaja principal de esta
metodología es que específica
puntualmente los pasos a seguir en
cada fase a diferencia de otras
metodologías que mencionan los
procesos, más no explican cómo
realizarlos.
- HEFESTO es una metodología propia, cuya propuesta está
fundamentada en una muy amplia investigación, comparación de
metodologías existentes, experiencias propias en procesos de
confección de almacenes de datos.
- DWEP(Data Warehouse Engineering Process)
- Se basa en Proceso de desarrollo de software unificada, también
conocido como Unified Process o simplemente UP . La UP es una
industria de software estándar de ingeniería de procesos (SEP) de
los autores de los UML.
Annotations:
- Donde como el UML define un modelado visual el lenguaje, la UP especifica cómo desarrollar software utilizando UML. El UP es un sep genérico que tiene que ser instanciado para una organización, proyecto o de dominio. DWEP es nuestra instancia de la UP para el desarrollo de DWS.
- Casos de uso (Requisito) impulsado, arquitectura centrada, iterativo e incremental.
De acuerdo con la UP, el ciclo de vida del proyecto se divide en cuatro fases
(Inception, Elaboración, Construcción y Transición) y cinco flujos de trabajo básicos
(Requisitos, Análisis, diseño, implementación y prueba). Hemos añadido dos más
flujos de trabajo a los flujos de trabajo UP: Mantenimiento y revisión
post-desarrollo. Durante el desarrollo de un proyecto, el énfasis se desplaza sobre
las iteraciones, desde requisitos y el análisis hacia el diseño, implementación,
prueba, y finalmente, mantenimiento y revisión post-desarrollo, pero diferentes
flujos de trabajo pueden coexistir en la misma iteración.
Annotations:
- Para cada uno de los flujos de trabajo, utilizamos diferentes diagramas UML (técnicas) para modelar y documentar el proceso de desarrollo, sino un modelo puede ser modificado en diferentes fases porque los modelos evolucionan con el tiempo.
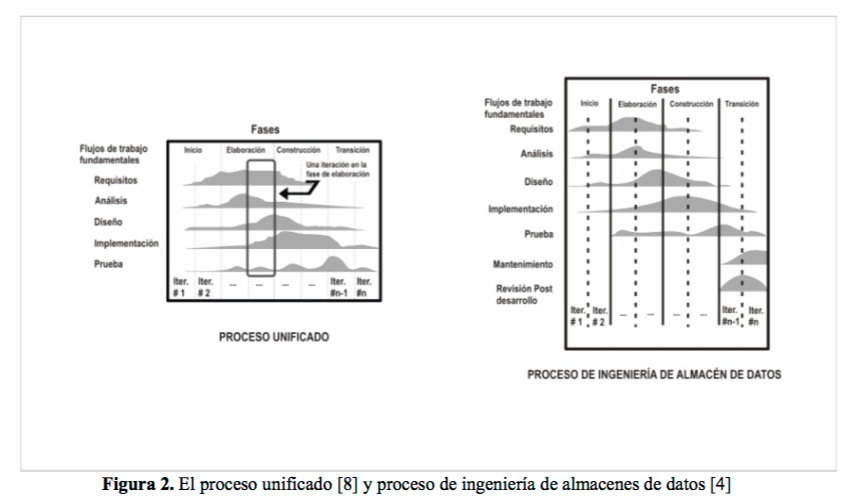
- 1 de 1 El PU como se muestra en la Figura 2, es un marco de
desarrollo compuesto de cuatro fases, cada una de ellas a su vez
dividida en una serie de iteraciones que ofrecen como resultado
un incremento del producto desarrollado, que añade o mejora las
funcionalidades del sistema en desarrollo. Fase de inicio Fase de
elaboraciónFase de construcción: Fase de transición
Annotations:
- El PU como se muestra en la Figura 2, es un marco de desarrollo compuesto de cuatro fases, cada una de ellas a su vez dividida en una serie de iteraciones que ofrecen como resultado un incremento del producto desarrollado, que añade o mejora las funcionalidades del sistema en desarrollo. Fase de inicio: El objetivo de esta fase es analizar el proyecto para justificar su puesta en marcha, para lograrlo se realiza una descripción general del proyecto, se detectan los riesgos críticos y se establecen la funcionalidad básica del software con una descripción de la arquitectura candidata. 2.3.2. Fase de elaboración: Una vez finalizada la fase de inicio, se pretende formar una arquitectura sólida para la construcción del software. En esta fase se busca establecer la base lógica de la aplicación con los casos de uso definitivos y los artefactos del sistema que lo componen. 2.3.3. Fase de construcción: Se inicia a partir de la línea base de arquitectura que se especificó en la fase de elaboración y su finalidad es desarrollar un producto listo para la operación inicial en el entorno del usuario final. 2.3.4. Fase de transición: Una vez que el proyecto entra en la fase de transición, el sistema ha alcanzado la capacidad operativa inicial. Esta fase busca implantar el producto en su entorno de operación.
- Se basa en Proceso de desarrollo de software unificada, también
conocido como Unified Process o simplemente UP . La UP es una
industria de software estándar de ingeniería de procesos (SEP) de
los autores de los UML.
- KIMBALL
- Ralph Kimball
- 1.Centrarse en el negocio
2.-Construir una infraestructura
de información adecuada.
3.-Realizar entregas en
incrementos significativos.
4.-Ofrecer la solución completa.
Annotations:
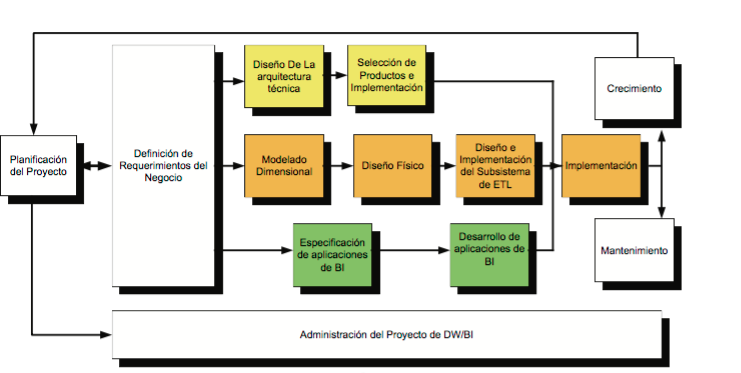
- La “Metodología Kimball” se basa en el Ciclo de Vida Dimensional del Negocio o Business Dimensional Lifecycle, el cual esta conformado por 4 principios básicos:
- 1.Centrarse en el negocio
2.-Construir una infraestructura
de información adecuada.
3.-Realizar entregas en
incrementos significativos.
4.-Ofrecer la solución completa.
- Para comprender la mayor diferencia entre estas dos metodologías, debemos explicar además de
la noción de DW mencionando en la introducción, la idea de Data mart. Un Data mart (Kimball et
al 98) es un repositorio de información, similar a un DW, pero orientado a un área o
departamento específico de la organización (por ejemplo Compras, Ventas, RRHH, etc.), a
diferencia del DW que cubre toda la organización, es decir la diferencia fundamental es su
alcance. Desde el punto de vista arquitectónico, la mayor diferencia entre los dos autores es el
sentido de la construcción del DW, esto es comenzando por los Data marts o ascendente
(Bottom-up, Kimball) o comenzando con todo el DW desde el principio, o descendente (Top- Down,
Inmon). Por otra parte, la metodología de Inmon se basa en conceptos bien conocidos del diseño
de bases de datos relacionases (Inmon 02, Imhoff & Galemmo 03).
- Ralph Kimball
- INMON
- William H. Inmon (born 1945)
- 1._Orientado a temas.- Los datos en la base de datos están organizados de
manera que todos los elementos de datos relativos al mismo evento u objeto del
mundo real queden unidos entre sí. Integrado. 2_La base de datos contiene los
datos de todos los sistemas operacionales de la organización, y dichos datos
deben ser consistentes. No volátil. 3._ La información no se modifica ni se
elimina, una vez almacenado un dato, éste se convierte en información de sólo
lectura, y se mantiene para futuras consultas. 4._Variante en el tiempo.- Los
cambios producidos en los datos a lo largo del tiempo quedan registrados para
que los informes que se puedan generar reflejen esas variaciones.
Annotations:
- Bill Inmon ve la necesidad de transferir la información de los diferentes OLTP (Sistemas Transaccionales) de las organizaciones a un lugar centralizado donde los datos puedan ser utilizados para el analisis (sería el CIF o Corporate Information Factory). Insiste ademas en que ha de tener las siguientes características:
Annotations:
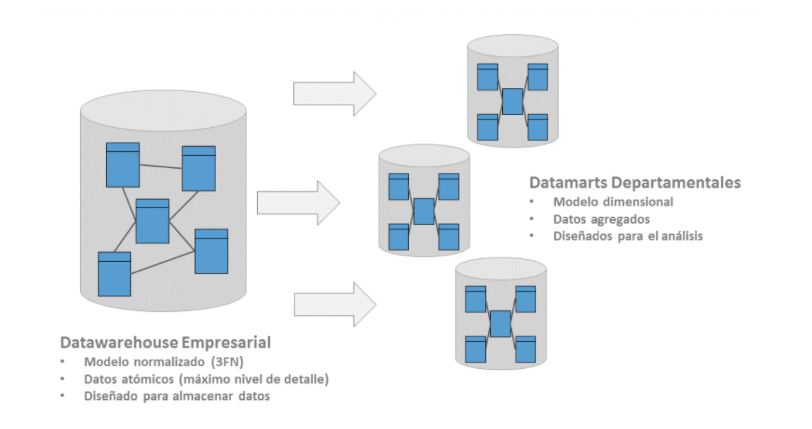
- Este enfoque de Inmon suele denominarse como una metodología de trabajo “Top-Down”, ya que se centra primero en una visión global de la compañía, para ir desmembrándola en pequeños sets de datos departamentales. Así, con esta arquitectura, todos los datamarts de la organización están conectados al datawarehouse, evitándose la aparición de incongruencias y anomalías al comparar los datos entre distintos departamentos.
Annotations:
- En cuanto a la estructura interna del datawarehouse, para Inmon la prioridad es que el modelo de datos esté construido en tercera forma normal. Por dar una breve explicación de lo que esto significa, el proceso de normalización consiste en aplicar una serie de reglas o normas a la hora de establecer las relaciones entre los diferentes objetos dentro de la base de datos. Con este proceso de normalización se consiguen muchos beneficios, como evitar la redundancia de los datos, mantener su integridad referencial, facilitar el mantenimiento de las tablas y disminuir el tamaño de la base de datos. Sin embargo, a diferencia de los datawarehouse desnormalizados, las consultas exigen el empleo de queries mucho más complejas, lo que dificulta el análisis directo de la información y el uso de las herramientas de reporting. De ahí, la necesidad de construir los datamarts, basados en modelos dimensionales de estrella o copo de nieve, diseños fácilmente explotables por estas herramientas de análisis de datos.
- 1._Orientado a temas.- Los datos en la base de datos están organizados de
manera que todos los elementos de datos relativos al mismo evento u objeto del
mundo real queden unidos entre sí. Integrado. 2_La base de datos contiene los
datos de todos los sistemas operacionales de la organización, y dichos datos
deben ser consistentes. No volátil. 3._ La información no se modifica ni se
elimina, una vez almacenado un dato, éste se convierte en información de sólo
lectura, y se mantiene para futuras consultas. 4._Variante en el tiempo.- Los
cambios producidos en los datos a lo largo del tiempo quedan registrados para
que los informes que se puedan generar reflejen esas variaciones.
- William H. Inmon (born 1945)
- METODOLOGIAS
- CREADORES / DESCRIPCIÓN
- CARACTERISTICAS
- FASES/(DISEÑOS /DIAGRAMAS)
- FASES/(DISEÑOS /DIAGRAMAS)
- CARACTERISTICAS
- CREADORES / DESCRIPCIÓN
- P3TQ
- La metodología Catalyst, conocida como P3TQ (Product, Place,
Price, Time, Quantity), fue propuesta por Dorian Pyle en el año
2003.
- La metodología Catalyst, en sus dos modelos, está compuesta por una serie de pasos llamados “boxes”. El concepto es que
luego de llevar a cabo una acción, se deben evaluar los resultados y determinar cuál es el próximo paso (box) a seguir. La
secuencia y la interacción entre los distintos pasos permiten una flexibilidad muy grande, y una amplia variedad de
caminos posibles. CRISP–DM, creada por el grupo de empresas SP
- La metodología Catalyst, en sus dos modelos, está compuesta por una serie de pasos llamados “boxes”. El concepto es que
luego de llevar a cabo una acción, se deben evaluar los resultados y determinar cuál es el próximo paso (box) a seguir. La
secuencia y la interacción entre los distintos pasos permiten una flexibilidad muy grande, y una amplia variedad de
caminos posibles. CRISP–DM, creada por el grupo de empresas SP
- La metodología Catalyst, conocida como P3TQ (Product, Place,
Price, Time, Quantity), fue propuesta por Dorian Pyle en el año
2003.
- KM-IRIS
- Fue elaborada por el grupo de Integración y
Re-Ingeniería de Sistemas (IRIS) de la Universidad Jaume
- Se crea con el objetivo de dirigir el proyecto de desarrollo de un sistema de gestión de conocimiento, se
ha diseñado para aplicarse a las diferentes fuentes de conocimiento que existen en la empresa, como las
personas, los documentos o los datos. Esta metodología pretende cubrir el ciclo completo en el
desarrollo de un sistema de gestión de conocimiento, Es una metodología poco difundida y con escasa
documentación.
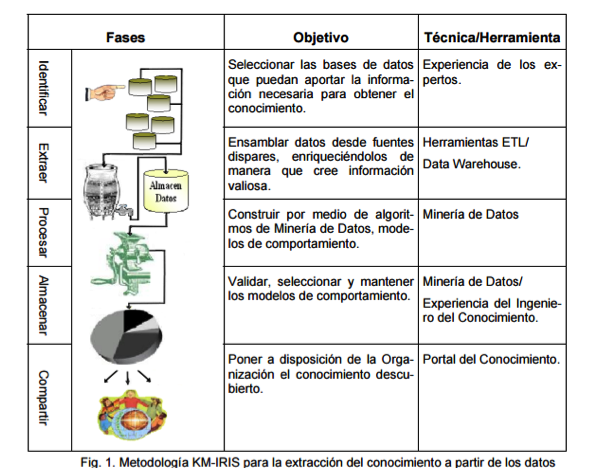
- 1._Fase Identificar 2._Fase
Extraer 3._Fase Procesar
4._Fase Almacenar 5._Fase
Compartir
Annotations:
- Fase Identificar: Persigue identificar los conocimientos que poseen las diversas fuentes de la empresa, para manipularlos posteriormente, reconociendo al mismo tiempo al experto que posee dicho conocimiento. Esta fase constituye el cimiento sobre la cual se erige toda la GC. Fase Extraer: Establece los mecanismos para extraer la mayor cantidad de conocimiento que sea posible, así como su grado de participación en la solución de problemas en la organización. Fase Procesar: Consiste en el análisis y diseño de los depósitos del conocimiento y de los expertos para cada fuente tratada de acuerdo a los datos extraídos. Con esta información no sólo será posible crear las bases de datos sino además construir el “mapa de conocimiento” (Stanford, 2001), es decir, visualizar el conocimiento más allá del texto con el fin de evocar, codificar, compartir, usar y expandir conocimiento. Fase Almacenar: Corresponde a la actualización de cada uno de los depósitos de conocimiento de acuerdo a las diversas fuentes utilizadas y a la base de expertos por conocimiento. Esta se lleva a cabo utilizando un esquema de clasificación, según el modelo de (Skyrme, 2002) que hace que las posteriores recuperaciones sean más fáciles. Fase Compartir: Tiene como objetivo brindar acceso a los depósitos de conocimiento y a la red de expertos a través de un portal corporativo. El portal emplea el mapa de conocimientos y diversas herramientas de manipulación del conocimiento para ubicar y acceder a la información, la cual se puede encontrar de manera distribuida.
- 1._Fase Identificar 2._Fase
Extraer 3._Fase Procesar
4._Fase Almacenar 5._Fase
Compartir
- Se crea con el objetivo de dirigir el proyecto de desarrollo de un sistema de gestión de conocimiento, se
ha diseñado para aplicarse a las diferentes fuentes de conocimiento que existen en la empresa, como las
personas, los documentos o los datos. Esta metodología pretende cubrir el ciclo completo en el
desarrollo de un sistema de gestión de conocimiento, Es una metodología poco difundida y con escasa
documentación.
- Fue elaborada por el grupo de Integración y
Re-Ingeniería de Sistemas (IRIS) de la Universidad Jaume
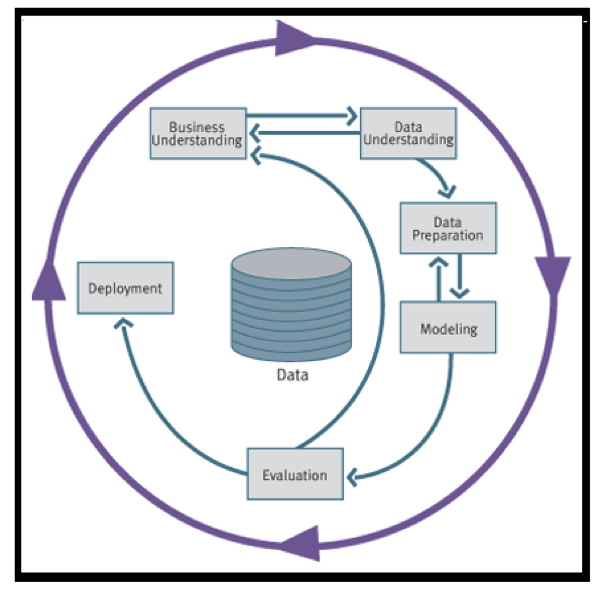
- CRISP-DM
- Es un estándar industrial utilizado por más de 160 empresas por todo el mundo que surge a la
respuesta de la falta de estandarización. El estándar incluye un modelo y una guía, estructurados en
seis fases, algunas de estas fases son bidireccionales, lo que significa que algunas fases permitirán
revisar parcial o totalmente las fases anteriores. Esta metodología para proyectos de minería de datos
no es la “más actual” o “la mejor”, pero es muy útil para comprender esta tecnología o extraer ideas
para diseñar o revisar métodos de trabajo para proyectos de similares características
- 1._Comprensión 2._Establecimiento
3._Evaluación la situación 4._ Establecimientode
los objetivos de la minería de datos
5._Generacióndel plan del proyecto
6._Comprensiónde los datos
Annotations:
- Comprensión del negocio (Objetivos y requerimientos desde una perspectiva no técnica) Establecimiento de los objetivos del negocio (Contexto inicial, objetivos, criterios de éxito) Evaluaciónde la situación (Inventario de recursos, requerimientos, supuestos,terminologías propias del negocio,…) Establecimientode los objetivos de la minería de datos (objetivos y criterios de éxito)Generacióndel plan del proyecto (plan, herramientas, equipo y técnicas) Comprensiónde los datos (Familiarizarse con los datos teniendopresente los objetivos del negocio) Recopilacióninicial de datos Descripciónde los datos Exploraciónde los datos Verificaciónde calidad de datosPreparaciónde los datos (Obtener la vista minable o dataset) Selección de los datos Limpieza dedatos Construcciónde datos Integraciónde datos Formateo dedatosModelado (Aplicarlas técnicas de minería de datos a los dataset)§ Selecciónde la técnica de modelado§ Diseño dela evaluación§ Construccióndel modelo§ Evaluacióndel modeloEvaluación (Delos modelos de la fase anteriores para determinar si son útiles a las necesidadesdel negocio)§ Evaluaciónde resultados§ Revisar elproceso§ Establecimientode los siguientes pasos o accionesDespliegue (Explotarutilidad de los modelos, integrándolos en las tareas de toma de decisiones dela organización)§ Planificaciónde despliegue§ Planificaciónde la monitorización y del mantenimiento§ Generaciónde informe final§ Revisióndel proyecto
- 1._Comprensión 2._Establecimiento
3._Evaluación la situación 4._ Establecimientode
los objetivos de la minería de datos
5._Generacióndel plan del proyecto
6._Comprensiónde los datos
- Es un estándar industrial utilizado por más de 160 empresas por todo el mundo que surge a la
respuesta de la falta de estandarización. El estándar incluye un modelo y una guía, estructurados en
seis fases, algunas de estas fases son bidireccionales, lo que significa que algunas fases permitirán
revisar parcial o totalmente las fases anteriores. Esta metodología para proyectos de minería de datos
no es la “más actual” o “la mejor”, pero es muy útil para comprender esta tecnología o extraer ideas
para diseñar o revisar métodos de trabajo para proyectos de similares características
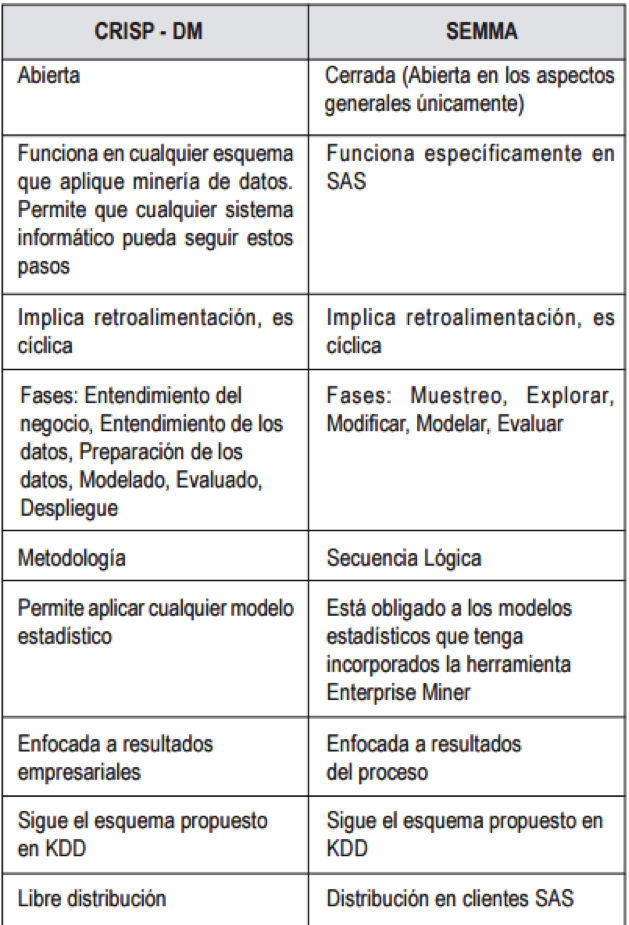
- SEMMA (Sample, Explore, Modify, Model,
Asses)
- Es un proceso que se sigue para realizar minería de datos. SEMMA es una organización lógica para el
manejo de una herramienta funcional de SAS llamada Enterprise Manager para el manejo de tareas de
minería de datos. SEMMA intenta hacer fácil de aplicar la exploración estadística y la visualización de
técnicas, seleccionando y transformando las variables predictivas más relevantes, modelándolas para
obtener resultados, y finalmente confirmar la precisión del modelo
- 1._Muestreo 2._Modificarse 3._Modelar 4._EvaluarSe
Annotations:
- Muestreo Se busca extraer una porción de datos lo suficientemente grande para contener información significativa, pero reducida para manipularla rápidamente. explorar Se desea explorar los datos buscando tendencias y anomalías imprevistas para obtener una comprensión total de los mismos. ModificarSe modifican los datos por medio de la creación, selección y transformación de variables, para centrar el proceso de selección del modelo. Modelar Se modelan los datos permitiendo que el software busque automáticamente una combinación de datos que prediga con cierta certeza un resultado deseado EvaluarSe califican los datos mediante la evaluación de la utilidad y fiabilidad de los resultados del proceso de minería de datos
- 1._Muestreo 2._Modificarse 3._Modelar 4._EvaluarSe
- Es un proceso que se sigue para realizar minería de datos. SEMMA es una organización lógica para el
manejo de una herramienta funcional de SAS llamada Enterprise Manager para el manejo de tareas de
minería de datos. SEMMA intenta hacer fácil de aplicar la exploración estadística y la visualización de
técnicas, seleccionando y transformando las variables predictivas más relevantes, modelándolas para
obtener resultados, y finalmente confirmar la precisión del modelo
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.