Description
|
|
Created by azumi_mary
almost 8 years ago
|
|
Page 1
APUNTES DISEÑO DE BASE DE DATOS AVANZADAS POR: INGENIERA PERLA VIOLETA SANCHEZ TAPIA:
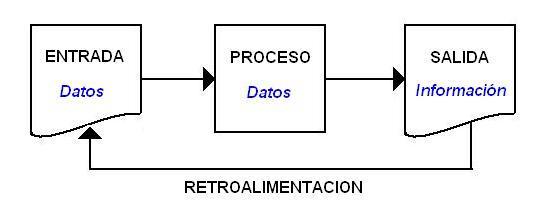
Base de Datos AvanzadosACREDITADO POR PERLA VIOLETA SANCHEZ TAPIA Este curso de Base de Datos y otros cursos abiertos son brindados en su totalidad por la universidad Atlantic International University (AIU) como parte de la “Iniciativa de Acceso Abierto”. Esta iniciativa es consistente con la Misión y Visión de la universidad. A través de esta iniciativa, la universidad Atlantic International University (AIU) busca eliminar las barreras que existen actualmente en el acceso a la educación, información y trabajos de investigación. La universidad AIU le da mucho valor e importancia al conocimiento y aprendizaje de los individuos y espera que este curso pueda tener una gran repercusión en las vidas de nuestros estudiantes y la humanidad en general alrededor del mundo, quienes tienen la inclinación natural hacia la búsqueda de nuevo conocimiento. Esperamos que este curso en Teorias y Tecnicas de la entrevista y otros cursos gratis, disponibles por parte de esta iniciativa de acceso abierto, permitan el avance y actualización a quienes lo deseen. El curso de Base de Datos contiene lo siguiente: Lecciones en formato de audio con las que se explica el contenido teórico. Actividades complementarias que le harán investigar más acerca del tema, así como, poner en práctica lo estudiado en la lección. Estas actividades no forman parte de su evaluación final. Textos que respaldan lo explicado en la videoconferencia. El curso de Base de Datos puede formar parte de un programa de titilación abonando hasta tres créditos universitarios. Las lecciones del curso se pueden llevar en línea através de estudio a distancia. Los contenidos y el acceso están abiertos al publico en función de la iniciativa "Open Access" o "Acceso Abierto" de Atlantic International University. Participantes que desean recibir crédito y/o certificado de termino, deben registrarse como alumnos (Conocer mas de AIU Acceso Abrierto). Lección 1: Funciones de un DBMS Determinado que una base de datos es una colección de archivos interrelacionados creados con un DBMS. El contenido de una base de datos esta almacenada de tal manera que los datos estén disponibles para los usuarios, una finalidad de la base de datos es eliminar la redundancia o al menos minimizarla. La DB (data base) es solo un “almacén” de datos, lo que ha hecho indispensable el desarrollo de sistemas que los administren y procesen, siendo estos los DBMS. El propósito general de los DBMS es el de manejar de manera clara, sencilla y ordenada, los datos de una Base de Datos (DB) que posteriormente se convertirán en información relevante, para un buen manejo de los datos. Video Conferencia Materiales de Lectura y Estudio Leccion 2: Desarrolladores y usuarios finales De los datos en donde habrá usuarios, no solo uno, que accederán a los datos de muchos usuarios, que a veces es el mismo dato que se traslapa y de ahí la importancia que la DB sea integrada conociéndose como BASE DE DATOS ÚNICA. Es importante entonces identificar el tipo de usuarios que acceden a una DB, que generalmente se clasificarán en dos tipos: desarrolladores y usuarios finales. Los Desarrolladores o Diseñadores están operando dentro de un DBMS en los Niveles de Diseño: Físico y Conceptual. Video Conferencia Materiales de Lectura y Estudio Leccion 3: MODELOS DE DATOS Un modelo de datos es una serie de conceptos que puede utilizarse para describir un conjunto de datos y las operaciones para manipularlos. Hay dos tipos de modelos de datos: los modelos conceptuales y los modelos lógicos. Los modelos conceptuales se utilizan para representar la realidad a un alto nivel de abstracción. Mediante los modelos conceptuales se puede construir una descripción de la realidad fácil de entender. En los modelos lógicos, las descripciones de los datos tienen una correspondencia sencilla con la estructura física de la base de datos. En el diseño de bases de datos se usan primero los modelos conceptuales para lograr una descripción de alto nivel de la realidad, y luego se transforma el esquema conceptual en un esquema lógico. El motivo de realizar estas dos etapas es la dificultad de abstraer la estructura de una base de datos que presente cierta complejidad. Un esquema es un conjunto de representaciones lingüísticas o gráficas que describen la estructura de los datos de interés. Video Conferencia Materiales de Lectura y Estudio Leccion 4: De red En este modelo las entidades se representan como nodos y sus relaciones son las líneas que los unen. En esta estructura cualquier componente puede relacionarse con cualquier otro. El Modelo de Red se puede entender como una extensión del modelo jerárquico. También se presenta mediante un árbol, pero en este caso, cada hijo puede tener varios padres. De este modo se reducen, o eliminan, las redundancias, Pero desaparece la herencia de los campos. La integridad de datos, asociada a los arcos padre-hijo, se mantiene. Video Conferencia Materiales de Lectura y Estudio Leccion 5: Conceptos Básicos El modelo entidad-relación es el modelo más utilizado para el diseño conceptual de bases de datos. Fue introducido por Peter Chan en 1976. El modelo entidad-relación está formado por un conjunto de conceptos que permiten describir la realidad mediante un conjunto de representaciones gráficas y lingüísticas. Originalmente, el modelo entidad-relación sólo incluía los conceptos de entidad, relación y atributo. Más tarde, se añadieron otros conceptos, como los atributos compuestos y las jerarquías de generalización, en lo que se ha denominado modelo entidad-relación extendido. Video Conferencia Materiales de Lectura y Estudio Leccion 6: Aplicaciones Definición de Aplicación (Application). Programa informático que permite a un usuario utilizar una computadora con un fin específico. Las aplicaciones son parte del software de una computadora, y suelen ejecutarse sobre el sistema operativo. Una aplicación de software suele tener un único objetivo: navegar en la web, revisar correo, explorar el disco duro, editar textos, jugar (un juego es un tipo de aplicación), etc. Una aplicación que posee múltiples programas se considera un paquete. Son ejemplos de aplicaciones Internet Explorer, Outlook, Word, Excel, Dreamweaver, etc. Video Conferencia Materiales de Lectura y Estudio Leccion 7: Definición del problema El modelo relacional se basa en dos ramas de las matemáticas: la teoría de conjuntos y la lógica de predicados de primer orden. El hecho de que el modelo relacional esté basado en la teoría de las matemáticas es lo que lo hace tan seguro y robusto. Al mismo tiempo, estas ramas de las matemáticas proporcionan los elementos básicos necesarios para crear una base de datos relacional con una buena estructura, y proporcionan las líneas que se utilizan para formular buenas metodologías de diseño. La teoría matemática proporciona la base para el modelo relacional y, por lo tanto, hace que el modelo sea predecible, fiable y seguro. La teoría describe los elementos básicos que se utilizan para crear una base de datos relacional y proporciona las líneas a seguir para construirla. El organizar estos elementos para conseguir el resultado deseado es lo que se denomina diseño. Video Conferencia Materiales de Lectura y Estudio Leccion 8: Normalización Uno de los objetivos de una estructura de tabla normalizada es minimizar el número de "celdas vacías". Grupos de información son almacenados en distintas tablas que luego pueden ser "juntadas" (relacionadas) basándose en los datos que tengan en común. Es necesario que al realizar la estructura de una base de datos, esta sea flexible. La flexibilidad está en el hecho que se puedan agregar datos al sistema posteriormente sin tener que rescribir lo que ya se tiene. Por lo tanto, no tendremos que modificar la estructura de nuestras tablas actuales, simplemente agregar lo que hace falta. Video Conferencia Materiales de Lectura y Estudio Leccion 9: Clasificación de fallas El sistema debe estar preparado para recuperarse no sólo de fallas puramente locales, como la aparición de una condición de desborde dentro de una transacción, sino también de fallas globales, como podría ser la interrupción del suministro eléctrico al CPU Las fallas locales son las que afectan sólo a la transacción en donde ocurrió. Por el contrario las fallas globales, afectan a varias y casi siempre a todas las transacciones que se estaban efectuando en el momento de la falla, por lo cual tienen implicaciones importantes en el sistema. Estas fallas pueden ser: Fallas del sistema Afectan a todas las transacciones que se estaban ejecutando pero no afectan a la base de datos, se conocen también como caídas suaves (crash). El problema aquí es que se pierda el contenido de memoria principal, en particular, las áreas de almacenamiento temporal o buffers. Video Conferencia Materiales de Lectura y Estudio Leccion 10: Recuperación por bitácora Para recuperarse de las fallas de las transacciones, el sistema mantiene un log llamado journal o periódico que mantiene el curso de todas las transacciones que afectan los datos ítems de la base de datos. Al conjunto de log se le conoce como system log. Esta información es mantenida en disco (memoria secundaria) de manera que sólo puede estar afectada, eventualmente, por fallas en medios de almacenamiento. Periódicamente, los log son respaldados en cintas para protegerlos contra fallas por catástrofes. Los log tienen una serie de entradas que se detallan a continuación. Las T se refieren a un identificador único de cada transacción. Video Conferencia Materiales de Lectura y Estudio
{kind=link}
Page 2
Son muchas las consideraciones a tomar en cuenta al momento de hacer el diseño de la base de datos, quizá las más fuertes sean: La velocidad de acceso, El tamaño de la información, El tipo de la información, Facilidad de acceso a la información, Facilidad para extraer la información requerida, El comportamiento del manejador de bases de datos con cada tipo de información. No obstante que pueden desarrollarse sistemas de procesamiento de archivo e incluso manejadores de bases de datos basándose en la experiencia del equipo de desarrollo de software logrando resultados altamente aceptables, siempre es recomendable la utilización de determinados estándares de diseño que garantizan el nivel de eficiencia mas alto en lo que se refiere a almacenamiento y recuperación de la información. De igual manera se obtiene modelos que optimizan el aprovechamiento secundario y la sencillez y flexibilidad en las consultas que pueden proporcionarse al usuario. OBJETIVOS DEL DISEÑO DE BASES DE DATOS Entre las metas más importantes que se persiguen al diseñar un modelo de bases de datos, se encuentran las siguientes que pueden observarse en esta figura. Almacenar Solo La Información Necesaria.A menudo pensamos en todo lo que quisiéramos que estuviera almacenado en una base de datos y diseñamos la base de datos para guardar dichos datos. Debemos de ser realistas acerca de nuestras necesidades y decidir qué información es realmente necesaria. Frecuentemente podemos generar algunos datos sobre la marcha sin tener que almacenarlos en una tabla de una base de datos. En estos casos también tiene sentido hacer esto desde el punto de vista del desarrollo de la aplicación. 1.2. Normalizar la Estructura de las Tablas. Si nunca antes hemos oído hablar de la "normalización de datos", no debemos temer. Mientras que la normalización puede parecer un tema complicado, nos podemos beneficiar ampliamente al entender los conceptos más elementales de la normalización. Una de las formas más fáciles de entender esto es pensar en nuestras tablas como hojas de cálculo. Por ejemplo, si quisiéramos seguir la pista de nuestra colección de CD’s en una hoja de cálculo, podríamos diseñar algo parecido a lo que se muestra en la siguiente tabla. +------------+-------------+--------------+ .. +--------------+ | Álbum | track1 | track2 | | track10 | +------------+-------------+--------------+ .. +--------------+ Esto parece razonable. Sin embargo el problema es que el número de pistas que tiene un CD varía bastante. Esto significa que con este método tendríamos que tener una hoja de cálculo realmente grande para albergar todos los datos, que en los peores casos podrían ser de hasta 20 pistas. Esto en definitiva no es nada bueno. Uno de los objetivos de una estructura de tabla normalizada es minimizar el número de "celdas vacías". El darnos cuenta de que cada lista de CD’s tiene un conjunto fijo de campos (título, artista, año, género) y un conjunto variable de atributos (el número de pistas) nos da una idea de cómo dividir los datos en múltiples tablas que luego podamos relacionar entre sí. Mucha gente no esta familiarizada con el concepto "relacional", de manera sencilla esto significa, que grupos parecidos de información son almacenados en distintas tablas que luego pueden ser "juntadas" (relacionadas) basándose en los datos que tengan en común. Es necesario que al realizar la estructura de una base de datos, esta sea flexible. La flexibilidad está en el hecho que podemos agregar datos al sistema posteriormente sin tener que rescribir lo que ya tenemos. Por ejemplo, si quisiéramos agregar la información de los artistas de cada álbum, lo único que tenemos que hacer es crear una tabla artista que esté relacionada a la tabla álbum de la misma manera que la tabla pista. Por lo tanto, no tendremos que modificar la estructura de nuestras tablas actuales, simplemente agregar la que hace falta. La eficiencia se refiere al hecho de que no tenemos duplicación de datos, y tampoco tenemos grandes cantidades de "celdas vacías". El objetivo principal del diseño de bases de datos es generar tablas que modelan los registros en los que guardaremos nuestra información. Es importante que esta información se almacene sin redundancia para que se pueda tener una recuperación rápida y eficiente de los datos. A través de la normalización tratamos de evitar ciertos defectos que nos conduzcan a un mal diseño y que lleven a un procesamiento menos eficaz de los datos. Podríamos decir que estos son los principales objetivos de la normalización: Controlar la redundancia de la información. Evitar pérdidas de información. Capacidad para representar toda la información. Mantener la consistencia de los datos. Seleccionar el Tipo de Dato Adecuado.Una vez identificadas todas las tablas y columnas que necesita la base de datos, debemos determinar el tipo de dato de cada campo. Existen tres categorías principales que pueden aplicarse prácticamente a cualquier aplicación de bases de datos: Texto Números Fecha y hora Cada uno de éstos presenta sus propias variantes, por lo que la elección del tipo de dato correcto no sólo influye en el tipo de información que se puede almacenar en cada campo, sino que afecta al rendimiento global de la base de datos. A continuación se dan algunos consejos que nos ayudarán a elegir un tipo de dato adecuado para nuestras tablas: Identificar si una columna debe ser de tipo texto, numérico o de fecha. Elegir el subtipo más apropiado para cada columna. Configurar la longitud máxima para las columnas de texto y numéricas, así como otros atributos. 1.4. Utilizar Índices Apropiadamente Los índices son un sistema especial que utilizan las bases de datos para mejorar su rendimiento global. Dado que los índices hacen que las consultas se ejecuten más rápido, podemos estar incitados a indexar todas las columnas de nuestras tablas. Sin embargo, lo que tenemos que saber es que el usar índices tiene un precio. Cada vez que hacemos un INSERT, UPDATE, REPLACE, o DELETE sobre una tabla, MySQL tiene que actualizar cualquier índice en la tabla para reflejar los cambios en los datos. ¿Así que, cómo decidimos usar índices o no? La respuesta es "depende". De manera simple, depende que tipo de consultas ejecutamos y que tan frecuentemente lo hacemos, aunque realmente depende de muchas otras cosas. Así que antes de indexar una columna, debemos considerar que porcentaje de entradas en la tabla son duplicadas. Si el porcentaje es demasiado alto, seguramente no veremos alguna mejora con el uso de un índice. Ante la duda, no tenemos otra alternativa que probar. 1.5. Usar Consultas REPLACE Existen ocasiones en las que deseamos insertar un registro a menos de que éste ya se encuentre en la tabla. Si el registro ya existe, lo que quisiéramos hacer es una actualización de los datos. 1.6. Usar Una Versión Reciente de MySQL La recomendación es simple y concreta, siempre que esté en nuestras manos, debemos usar la versión más reciente de MySQL que se encuentre disponible. Además de que las nuevas versiones frecuentemente incluyen muchas mejoras, cada vez son más estables y más rápidas. De esta manera, a la vez que sacamos provecho de las nuevas características incorporadas en MySQL, veremos significativos incrementos en la eficiencia de nuestro servidor de bases de datos. 1.8. Usar Tablas Temporales. Cuando estamos trabajando con tablas muy grandes, suele suceder que ocasionalmente necesitemos ejecutar algunas consultas sobre un pequeño subconjunto de una gran cantidad de datos. En vez de ejecutar estas consultas sobre la tabla completa y hacer que MySQL encuentre cada vez los pocos registros que necesitamos, puede ser mucho más rápido seleccionar dichos registros en una tabla temporal y entonces ejecutar nuestras consultas sobre esta tabla. Una tabla temporal existe mientras dure la conexión a MySQL. Cuando se interrumpe la conexión MySQL remueve automáticamente la tabla y libera el espacio que ésta usaba. 1.7. Recomendaciones. El último paso del diseño de la base de datos es adoptar determinadas convenciones de nombres. Aunque MySQL es muy flexible en cuanto a la forma de asignar nombre a las bases de datos, tablas y columnas, he aquí algunas reglas que es conveniente observar: Utilizar caracteres alfanuméricos. Limitar los nombres a menos de 64 caracteres (es una restricción de MySQL). Utilizar el guión bajo (_) para separar palabras. Utilizar palabras en minúsculas (esto es más una preferencia personal que una regla). Los nombres de las tablas deberían ir en plural y los nombres de las columnas en singular (es igual una preferencia personal). Utilizar las letras ID en las columnas de clave primaria y foránea. En una tabla, colocar primero la clave primaria seguida de las claves foráneas. Los nombres de los campos deben ser descriptivos de su contenido. Los nombres de los campos deben ser unívocos entre tablas, excepción hecha de las claves. Los puntos anteriores corresponden muchos de ellos a preferencias personales, más que a reglas que debamos de cumplir, y en consecuencia muchos de ellos pueden ser pasados por alto, sin embargo, lo más importante es que la nomenclatura utilizada en nuestras bases de datos sea coherente y consistente con el fin de minimizar la posibilidad de errores al momento de crear una aplicación de bases de datos. Leer más: http://www.monografias.com/trabajos30/base-datos/base-datos.shtml#ixzz4ATDfpQuJ
{kind=link}
Page 3
CONCEPTOS IMPORTANTES Base de Datos.- Cualquier conjunto de datos organizados para su almacenamiento en la memoria de un ordenador o computadora, diseñado para facilitar su mantenimiento y acceso de una forma estándar. Los datos suelen aparecer en forma de texto, números o gráficos. Hay cuatro modelos principales de bases de datos: el modelo jerárquico, el modelo en red, el modelo relacional (el más extendido hoy en día). Base de Datos Relacional.- Tipo de base de datos o sistema de administración de bases de datos, que almacena información en tablas (filas y columnas de datos) y realiza búsquedas utilizando los datos de columnas especificadas de una tabla para encontrar datos adicionales en otra tabla. Datos Elementales.- Un dato elemental, tal como indica su nombre, es una pieza elemental de información. El primer paso en el diseño de una base de datos debe ser un análisis detallado y exhaustivo de los datos elementales requeridos. Campos y Subcampos.- Los datos elementales pueden ser almacenados en campos o en subcampos. Un campo es identificado por un rótulo numérico que se define en la FDT de la base de datos. A diferencia de los campos, los subcampos no se identifican por medio de un rótulo, sino por un delimitador de subcampo. Delimitador de Subcampo.- Un delimitador de subcampo es un código de dos caracteres que precede e identifica un subcampo de longitud variable dentro de un campo. DBMS: Data Base Management System (SISTEMA DE MANEJO DE BASE DE DATOS).- Consiste de una base de datos y un conjunto de aplicaciones (programas) para tener acceso a ellos. à Errores que se pueden encontrar en el diseño de una base de datos: Modelo de Datos.- es un conjunto de herramientas conceptuales para describir los datos, las relaciones entre ellos, su semántica y sus limitantes. Redundancia.- Esta se presenta cuando se repiten innecesariamente datos en los archivos que conforman la base de datos. Inconsistencia.- Ocurre cuando existe información contradictoria o incongruente en la base de datos. Dificultad en el Acceso a los Datos.- Debido a que los sistemas de procesamiento de archivos generalmente se conforman en distintos tiempos o épocas y ocasionalmente por distintos programadores, el formato de la información no es uniforme y se requiere de establecer métodos de enlace y conversión para combinar datos contenidos en distintos archivos. Aislamiento de los Datos.- Se refiere a la dificultad de extender las aplicaciones que permitan controlar a la base de datos, como pueden ser, nuevos reportes, utilerías y demás debido a la diferencia de formatos en los archivos almacenados. Anomalías en el Acceso Concurrente.- Ocurre cuando el sistema es multiusuario y no se establecen los controles adecuados para sincronizar los procesos que afectan a la base de datos. Comúnmente se refiere a la poca o nula efectividad de los procedimientos de bloqueo. Problemas de Seguridad.- Se presentan cuando no es posible establecer claves de acceso y resguardo en forma uniforme para todo el sistema, facilitando así el acceso a intrusos. à Niveles de Diseño: Problemas de Integridad.- Ocurre cuando no existe a través de todo el sistema procedimientos uniformes de validación para los datos. Nivel Físico.- Es aquel en el que se determinan las características de almacenamiento en el medio secundario. Los diseñadores de este nivel poseen un amplio dominio de cuestiones técnicas y de manejo de hardware. Nivel Conceptual.- Es aquel en el que se definen las estructuras lógicas de almacenamiento y las relaciones que se darán entre ellas. Ejemplos comunes de este nivel son el diseño de los registros y las ligas que permitirán la conexión entre registros de un mismo archivo, de archivos distintos incluso, de ligas hacia archivos. à Clasificación de Modelos de Datos: Nivel de Edición.- Es aquel en el que se presenta al usuario final y que puede tener combinaciones o relaciones entre los datos que conforman a la base de datos global. Puede definirse como la forma en el que el usuario aprecia la información y sus relaciones. Modelos Lógicos Basados en Objetos.- Son aquellos que nos permiten una definición clara y concisa de los esquemas conceptuales y de visión. Su característica principal es que permiten definir en forma detallada las limitantes de los datos. Modelos Lógicos Basados en Registros.- Operan sobre niveles conceptual y de visión. Sus características principales son que permiten una descripción más amplia de la implantación, pero no son capaces de especificar con claridad las limitantes de los datos. Modelos Físicos de Datos.- Describen los datos en el nivel más bajo y permiten identificar algunos detalles de implantación para el manejo del hardware de almacenamiento. Leer más: http://www.monografias.com/trabajos30/base-datos/base-datos.shtml#ixzz4ATDvT5aW
Page 4
Crear una relación de uno a varios Considere este ejemplo: las tablas Proveedores y Productos de la base de datos de pedidos de productos. Un proveedor puede suministrar cualquier número de productos y, por consiguiente, para cada proveedor representado en la tabla Proveedores, puede haber muchos productos representados en la tabla Productos. La relación entre la tabla Proveedores y la tabla Productos es, por tanto, una relación de uno a varios. Para representar una relación de uno a varios en el diseño de la base de datos, tome la clave principal del lado "uno" de la relación y agréguela como columna o columnas adicionales a la tabla en el lado "varios" de la relación. En este caso, por ejemplo, agregaría la columna Id. de proveedor de la tabla Proveedores a la tabla Productos. Access utilizaría entonces el número de identificador de proveedor de la tabla Productos para localizar el proveedor correcto de cada producto. La columna Id. de proveedor de la tabla Productos se denomina clave externa. Una clave externa es la clave principal de otra tabla. La columna Id. de proveedor de la tabla Productos en una clave externa porque también es la clave principal en la tabla Proveedores. El punto de partida para la unión de tablas relacionadas se proporciona estableciendo parejas de claves principales y claves externas. Si no está seguro de las tablas que deben compartir una columna común, al identificar una relación de uno a varios se asegurará de que las dos tablas implicadas requerirán una columna compartida. Volver al principio Crear una relación de varios a varios Considere la relación entre la tabla Productos y la tabla Pedidos. Un solo pedido puede incluir varios productos. Por otro lado, un único producto puede aparecer en muchos pedidos. Por tanto, para cada registro de la tabla Pedidos puede haber varios registros en la tabla Productos. Y para cada registro de la tabla Productos puede haber varios registros en la tabla Pedidos. Este tipo de relación se denomina relación de varios a varios porque para un producto puede haber varios pedidos, y para un pedido puede haber varios productos. Tenga en cuenta que para detectar las relaciones de varios a varios entre las tablas, es importante que considere ambas partes de la relación. Los temas de las dos tablas (pedidos y productos) tienen una relación de varios a varios. Esto presenta un problema. Para comprender el problema, imagine qué sucedería si intenta crear la relación entre las dos tablas agregando el campo Id. de producto a la tabla Pedidos. Para que haya más de un producto por pedido, necesita más de un registro en la tabla Pedidos para cada pedido y, en ese caso, tendría que repetir la información de pedido para cada fila relacionada con un único pedido, lo que daría lugar a un diseño ineficaz que podría producir datos inexactos. El mismo problema aparece si coloca el campo Id. de pedido en la tabla Productos: tendría varios registros en la tabla Productos para cada producto. ¿Cómo se soluciona este problema? La solución a este problema consiste en crear una tercera tabla que descomponga la relación de varios a varios en dos relaciones de uno a varios. Insertaría la clave principal de cada una de las dos tablas en la tercera tabla y, por consiguiente, la tercera tabla registraría todas las apariciones o instancias de la relación. Cada registro de la tabla Detalles de pedidos representa un artículo de línea de un pedido. La clave principal de la tabla Detalles de pedidos consta de dos campos: las claves externas de las tablas Pedidos y Productos. El campo Id. de pedido no se puede utilizar en solitario como clave principal, ya que un pedido puede tener varios artículos de línea. El identificador de pedido se repite para cada artículo de línea del pedido, por lo que el campo no contiene valores únicos. Tampoco serviría utilizar solamente el campo Id. de producto, porque un producto puede aparecer en varios pedidos. Pero los dos campos juntos producen un valor exclusivo para cada registro. En la base de datos de ventas de productos, la tabla Pedidos y la tabla Productos no se relacionan directamente entre sí, sino indirectamente a través de la tabla Detalles de pedidos. La relación de varios a varios entre los pedidos y los productos se representa en la base de datos mediante dos relaciones de uno a varios: La tabla Pedidos y la tabla Detalles de pedidos tienen una relación de uno a varios. Cada pedido tiene varios artículos de línea, pero cada artículo está asociado a un único pedido. La tabla Productos y la tabla Detalles de pedidos tienen una relación de uno a varios. Cada producto puede tener varios artículos asociados, pero cada artículo de línea hace referencia únicamente a un producto. Desde la tabla Detalles de pedidos puede determinar todos los productos de un determinado pedido, así como todos los pedidos de un determinado producto. Después de incorporar la tabla Detalles de pedidos, la lista de tablas y campos sería similar a la siguiente: Volver al principio Crear una relación de uno a uno Otro tipo de relación es la relación de uno a uno. Suponga, por ejemplo, que necesita registrar información complementaria sobre productos que apenas va a necesitar o que sólo se aplica a unos pocos productos. Como no necesita la información con frecuencia, y como almacenar la información en la tabla Productos crearía un espacio vacío para todos los productos que no necesitan esa información, la coloca en una tabla distinta. Al igual que en la tabla Productos, utiliza el identificador de producto como clave principal. La relación entre esta tabla complementaria y la tabla Productos es una relación de uno a uno. Para cada registro de la tabla Productos hay un único registro coincidente en la tabla complementaria. Cuando identifique esta relación, ambas tablas deben compartir un campo común. Cuando necesite crear una relación de uno a uno en la base de datos, considere si puede incluir la información de las dos tablas en una tabla. Si no desea hacer eso por algún motivo (quizás porque se crearía una gran cantidad de espacio vacío), puede representar esa relación en su diseño guiándose por las pautas siguientes: Si las dos tablas tienen el mismo tema, probablemente podrá definir la relación utilizando la misma clave principal en ambas tablas. Si las dos tablas tienen temas diferentes con claves principales distintas, elija una de las tablas (cualquiera de ellas) e inserte su clave principal en la otra tabla como clave externa. Determinar las relaciones entre las tablas le ayudará a asegurarse de que tiene las tablas y columnas correctas. Cuando existe una relación de uno a uno o de uno a varios, las tablas implicadas deben compartir una o varias columnas comunes. Cuando la relación es de varios a varios, se necesita una tercera tabla para representar la relación. Volver al principio Ajustar el diseño Cuando tenga las tablas, los campos y las relaciones necesarias, debe crear y rellenar las tablas con datos de ejemplo y probar que funcionan con la información: creando consultas, agregando nuevos registros, etc. Esto le permitirá encontrar posibles problemas, como la necesidad de agregar una columna que olvidó insertar durante la fase de diseño, o dividir una tabla en dos tablas para eliminar datos duplicados. Compruebe si puede usar la base de datos para obtener las respuestas que desea. Cree formularios e informes provisionales y compruebe si muestran los datos según lo previsto. Compruebe si existen datos duplicados innecesarios y, si encuentra alguno, modifique el diseño para eliminar la duplicación.
{kind=link}
Page 5
Diseñar y modelar una base de datos Al diseñar una base de datos determinamos las tablas y campos que darán forma a nuestra base de datos. El hecho de tomarnos el tiempo necesario para identificar, organizar y relacionar la información nos evitará problemas posteriores. Es por eso que para diseñar una base de datos es necesario conocer la problemática y todo el contexto sobre la información que se almacenará en nuestro repositorio de datos. Debemos determinar la finalidad de la base de datos y en base a eso reunir toda la información que será registrada. A continuación los 5 pasos esenciales para realizar un buen diseño y modelo de una base de datos. 1. Identificar las tablas De acuerdo a los requerimientos que tengamos para la creación de nuestra base de datos, debemos identificar adecuadamente los elementos de información y dividirlos en entidades (temas principales) como pueden ser las sucursales, los productos, los clientes, etc. Para cada uno de los objetos identificados crearemos una tabla. Si en una base de datos los objetos principales son los empleados y los departamentos de la empresa entonces tendremos una tabla para cada uno de ellos. Si en otra base de datos los objetos principales son los libros, autores y editores entonces necesitaremos tres tablas en nuestra base de datos. 2. Determinar los campos Cada entidad representada por una tabla posee características propias que lo describen y que lo hacen diferente de los demás objetos. Esas características de cada entidad serán nuestros campos de la tabla los cuales describirán adecuadamente a cada registro. Por ejemplo, una tabla de libros impresos tendrá los campos ISBN, título, páginas, autor, etc. 3. Determinar las llaves primarias Una llave primaria es un identificador único para cada registro (fila) de una tabla. La llave primaria es un campo de la tabla cuyo valor será diferente para todos los registros. Por ejemplo, para una tabla de libros, la llave primaria bien podría ser el ISBN el cual es único para cada libro. Para una tabla de productos se tendría una clave de producto que los identifique de manera única. 4. Determinar las relaciones entre tablas Examina las tablas creadas y revisa si existe alguna relación entre ellas. Cuando encontramos que existe una relación entre dos tablas debemos identificar el campo de relación. Por ejemplo, en una base de datos de productos y categorías existirá una relación entre las dos tablas porque una categoría puede tener varios productos asignados. Por lo tanto el campo con el código de la categoría será el campo que establezca la relación entre ambas tablas. 5. Identificar y remover datos repetidos Finalmente examina cada una de las tablas y verifica que no exista información repetida. El tener información repetida puede causar problemas de consistencia en los datos además de ocupar más espacio de almacenamiento. Por ejemplo, una tabla de empleados que contiene el código del departamento y el nombre del departamento comenzará a repetir la información para los empleados que pertenezcan al mismo departamento. ¿Qué pasaría si el nombre del departamento cambiara de Informática a Tecnología? Tendríamos que ir registro por registro modificando el nombre correspondiente y podríamos dejar alguna incongruencia en los datos. Una mejor solución es tener una tabla exclusiva de departamentos y solamente incluir la clave del departamento en la tabla de empleados. De esta manera dejamos de repetir el nombre del departamento en la tabla de empleados y ahorramos espacios de almacenamiento. Y en caso de un cambio de nombre de departamento solamente debemos realizar la actualización en un solo lugar. El diseño de bases de datos es un tema muy extenso y es difícil considerar todos sus aspectos en un solo artículo. Sin embargo, al seguir estas 5 reglas básicas del diseño de bases de datos estaremos dando un paso hacia adelante en las buenas prácticas de creación y gestión de bases de datos.
{kind=link}
Page 6
{kind=link}
GDB: Sistemas de Gestión de Bases de Datos Introducción Arquitectura de Red Arquitectura Jerárquica Arquitectura Relacional Administrador de la Base de Datos Diccionario de Datos Objetivos de los SGBD Características que debe ofrecer un Sistema de Gestión de Bases de Datos Diseño conceptual de una Base de Datos Modelo Entidad-Relación Entidades Atributos Relaciones Cardinalidades Claves Entidades débiles Atributos multievaluados y compuestos Clase de pertenencia Paso a tablas Software: Diagramas Entidad-Relación Modelo relacional Características principales del modelo de bases de datos relacional Algebra relacional Conjunto de operadores que permiten el acceso a la información contenida en una base de datos relacional Integridad referencial Conceptos y mecanismos para conservar la integridad de todos los datos Proceso de Normalización Dependencias funcionales Recubrimiento Minimal No Redundante Cálculo de claves Formas normales 1FN 2FN 3FN FNBC SQL: Structured Query Language Crear, Modificar, Borrar tablas Inserción, Modificación, Borrado de tuplas Vistas Consultas: Sentencia SELECT Software: Consola SQL Tipos de arquitecturas Arquitectura cliente/servidor frente a la arquitectura centralizada Componentes Software Servicios de usuario Servicios de negocio Servicios de datos Modelo cliente / servidor 2 Capas 3 Capas Objetos de acceso a datos Data Access Object (DAO) Microsoft Access Creación de una Base de Datos Visual Basic Entorno Visual Basic 6 Sintaxis básica de Visual Basic Práctica: Aplicación de gestión Aplicación implementada en Visual Basic que permitirá el acceso a una base de datos Access
Guia acreditada por:ingeniera perla violeta sanchez tapia
Page 7
apuntes terminales para el parcial completo: Ing.Perla Violeta Sanchez Tapia
con el fin de autorizar nuestra guia de apuntes y sea util paara terminar con tu conocimineto y sar soporte para un mejor entendimieneto de la clase y mejorar tu forma de aprendisaje para tus apuntes seleccionados y eficazes en la materia recopilados de los cuadernos de sus alumnos para lucro de su materia y aprendisaje..
Want to create your own Notes for free with GoConqr? Learn more.