4600924
BASE DE DATOS
- Definicion
- Una base de datos es una colección de archivos relacionados que permite el manejo de la
información de alguna compañía. Cada uno de dichos archivos puede ser visto como una colección
de registros y cada registro está compuesto de una colección de campos.
- Una base de datos es una colección de archivos relacionados que permite el manejo de la
información de alguna compañía. Cada uno de dichos archivos puede ser visto como una colección
de registros y cada registro está compuesto de una colección de campos.
- Historia
- El término bases de datos fue escuchado por primera vez en un simposio celebrado en California en
1963. En una primera aproximación, se puede decir que una base de datos es un conjunto de
información relacionada que se encuentra agrupada o estructurada. Desde el punto de vista
informático, una base de datos es un sistema formado por un conjunto de datos almacenados en
discos que permiten el acceso directo a ellos y un conjunto de programas que manipulen ese
conjunto de datos. Por su parte, un sistema de Gestión de Bases de datos es un tipo de software muy
especifico dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la
utilizan; o lo que es lo mismo, una agrupación de programas que sirven para definir, construir y
manipular una base de datos, permitiendo así almacenar y posteriormente acceder a los datos de
forma rápida y estructurada. Actualmente, las bases de datos están teniendo un impacto decisivo
sobre el creciente uso de las computadoras.
- Origen
- Los orígenes de las bases de datos se remontan a la Antigüedad donde ya existían bibliotecas y toda
clase de registros. Además también se utilizaban para recoger información sobre las cosechas y
censos. Sin embargo, su búsqueda era lenta y poco eficaz y no se contaba con la ayuda de máquinas
que pudiesen reemplazar el trabajo manual. Posteriormente, el uso de las bases de datos se
desarrolló a partir de las necesidades de almacenar grandes cantidades de información o datos.
Sobre todo, desde la aparición de las primeras computadoras, el concepto de bases de datos ha
estado siempre ligado a la informática. En 1884 Herman Hollerith creó la máquina automática de
tarjetas perforadas, siendo nombrado así el primer ingeniero estadístico de la historia. En esta
época, los censos se realizaban de forma manual.
- Ante esta situación, Hollerith comenzó a trabajar en el diseño de una maquina tabuladora o
censadora, basada en tarjetas perforadas.
- Posteriormente, en la década de los cincuenta se da origen a las cintas magnéticas, para automatizar
la información y hacer respaldos. Esto sirvió para suplir las necesidades de información de las
nuevas industrias. Y a través de este mecanismo se empezaron a automatizar información, con la
desventaja de que solo se podía hacer de forma secuencial.
- Década de 1960
- Posteriormente en la época de los sesenta, las computadoras bajaron los precios para que las
compañías privadas las pudiesen adquirir; dando paso a que se popularizara el uso de los discos,
cosa que fue un adelanto muy efectivo en la época, debido a que a partir de este soporte se podía
consultar la información directamente, sin tener que saber la ubicación exacta de los datos. En esta
misma época se dio inicio a las primeras generaciones de bases de datos de red y las bases de datos
jerárquicas, ya que era posible guardar estructuras de datos en listas y arboles. Otro de los
principales logros de los años sesenta fue la alianza de IBM y American Airlines para desarrollar
SABRE, un sistema operativo que manejaba las reservas de vuelos, transacciones e informaciones
sobre los pasajeros de la compañía American Airlines.
- Posteriormente en la época de los sesenta, las computadoras bajaron los precios para que las
compañías privadas las pudiesen adquirir; dando paso a que se popularizara el uso de los discos,
cosa que fue un adelanto muy efectivo en la época, debido a que a partir de este soporte se podía
consultar la información directamente, sin tener que saber la ubicación exacta de los datos. En esta
misma época se dio inicio a las primeras generaciones de bases de datos de red y las bases de datos
jerárquicas, ya que era posible guardar estructuras de datos en listas y arboles. Otro de los
principales logros de los años sesenta fue la alianza de IBM y American Airlines para desarrollar
SABRE, un sistema operativo que manejaba las reservas de vuelos, transacciones e informaciones
sobre los pasajeros de la compañía American Airlines.
- Década de 1970
- Por lo que respecta a la década de los setenta, Edgar Frank Codd, científico informático ingles
conocido por sus aportaciones a la teoría de bases de datos relacionales, definió el modelo relacional
a la par que publicó una serie de reglas para los sistemas de datos relacionales a través de su
artículo “Un modelo relacional de datos para grandes bancos de datos compartidos”.
- Oracle
- Pero cabe destacar que ORACLE es considerado como uno de los sistemas de bases de datos más
completos que existen en el mundo, y aunque su dominio en el mercado de servidores
empresariales ha sido casi total hasta hace relativamente poco, actualmente sufre la competencia
del SQL Server de la compañía Microsoft y de la oferta de otros Sistemas Administradores de Bases
de Datos Relacionales con licencia libre como es el caso de PostgreSQL, MySQL o Firebird que
aparecerían posteriormente en la década de 1990.
- Pero cabe destacar que ORACLE es considerado como uno de los sistemas de bases de datos más
completos que existen en el mundo, y aunque su dominio en el mercado de servidores
empresariales ha sido casi total hasta hace relativamente poco, actualmente sufre la competencia
del SQL Server de la compañía Microsoft y de la oferta de otros Sistemas Administradores de Bases
de Datos Relacionales con licencia libre como es el caso de PostgreSQL, MySQL o Firebird que
aparecerían posteriormente en la década de 1990.
- Oracle
- Por lo que respecta a la década de los setenta, Edgar Frank Codd, científico informático ingles
conocido por sus aportaciones a la teoría de bases de datos relacionales, definió el modelo relacional
a la par que publicó una serie de reglas para los sistemas de datos relacionales a través de su
artículo “Un modelo relacional de datos para grandes bancos de datos compartidos”.
- Década de 1980
- Por su parte, a principios de los años ochenta comenzó el auge de la comercialización de los sistemas
relacionales, y SQL comenzó a ser el estándar de la industria, ya que las bases de datos relacionales
con su sistema de tablas (compuesta por filas y columnas) pudieron competir con las bases
jerárquicas y de red, como consecuencia de que su nivel de programación era sencillo y su nivel de
programación era relativamente bajo.
- Década años 1990
- En la década de 1990 la investigación en bases de datos giró en torno a las bases de datos orientadas
a objetos. Las cuales han tenido bastante éxito a la hora de gestionar datos complejos en los campos
donde las bases de datos relacionales no han podido desarrollarse de forma eficiente. Así se
desarrollaron herramientas como Excel y Access del paquete de Microsoft Office que marcan el inicio
de las bases de datos orientadas a objetos.
- SIGLO XXI
- En la actualidad, las tres grandes compañías que dominan el mercado de las bases de datos son IBM,
Microsoft y Oracle. Por su parte, en el campo de internet, la compañía que genera gran cantidad de
información es Google. Aunque existe una gran variedad de software que permiten crear y manejar
bases de datos con gran facilidad, como por ejemplo LINQ, que es un proyecto de Microsoft que
agrega consultas nativas semejantes a las de SQL a los lenguajes de la plataforma .NET. El objetivo de
este proyecto es permitir que todo el código hecho en Visual Studio sean también orientados a
objetos; ya que antes de LINQ la manipulación de datos externos tenía un concepto más
estructurado que orientado a objetos; y es por eso que trata de facilitar y estandarizar el acceso a
dichos objetos.
- En la actualidad, las tres grandes compañías que dominan el mercado de las bases de datos son IBM,
Microsoft y Oracle. Por su parte, en el campo de internet, la compañía que genera gran cantidad de
información es Google. Aunque existe una gran variedad de software que permiten crear y manejar
bases de datos con gran facilidad, como por ejemplo LINQ, que es un proyecto de Microsoft que
agrega consultas nativas semejantes a las de SQL a los lenguajes de la plataforma .NET. El objetivo de
este proyecto es permitir que todo el código hecho en Visual Studio sean también orientados a
objetos; ya que antes de LINQ la manipulación de datos externos tenía un concepto más
estructurado que orientado a objetos; y es por eso que trata de facilitar y estandarizar el acceso a
dichos objetos.
- SIGLO XXI
- En la década de 1990 la investigación en bases de datos giró en torno a las bases de datos orientadas
a objetos. Las cuales han tenido bastante éxito a la hora de gestionar datos complejos en los campos
donde las bases de datos relacionales no han podido desarrollarse de forma eficiente. Así se
desarrollaron herramientas como Excel y Access del paquete de Microsoft Office que marcan el inicio
de las bases de datos orientadas a objetos.
- Década años 1990
- Por su parte, a principios de los años ochenta comenzó el auge de la comercialización de los sistemas
relacionales, y SQL comenzó a ser el estándar de la industria, ya que las bases de datos relacionales
con su sistema de tablas (compuesta por filas y columnas) pudieron competir con las bases
jerárquicas y de red, como consecuencia de que su nivel de programación era sencillo y su nivel de
programación era relativamente bajo.
- Década de 1960
- Posteriormente, en la década de los cincuenta se da origen a las cintas magnéticas, para automatizar
la información y hacer respaldos. Esto sirvió para suplir las necesidades de información de las
nuevas industrias. Y a través de este mecanismo se empezaron a automatizar información, con la
desventaja de que solo se podía hacer de forma secuencial.
- Ante esta situación, Hollerith comenzó a trabajar en el diseño de una maquina tabuladora o
censadora, basada en tarjetas perforadas.
- Los orígenes de las bases de datos se remontan a la Antigüedad donde ya existían bibliotecas y toda
clase de registros. Además también se utilizaban para recoger información sobre las cosechas y
censos. Sin embargo, su búsqueda era lenta y poco eficaz y no se contaba con la ayuda de máquinas
que pudiesen reemplazar el trabajo manual. Posteriormente, el uso de las bases de datos se
desarrolló a partir de las necesidades de almacenar grandes cantidades de información o datos.
Sobre todo, desde la aparición de las primeras computadoras, el concepto de bases de datos ha
estado siempre ligado a la informática. En 1884 Herman Hollerith creó la máquina automática de
tarjetas perforadas, siendo nombrado así el primer ingeniero estadístico de la historia. En esta
época, los censos se realizaban de forma manual.
- El término bases de datos fue escuchado por primera vez en un simposio celebrado en California en
1963. En una primera aproximación, se puede decir que una base de datos es un conjunto de
información relacionada que se encuentra agrupada o estructurada. Desde el punto de vista
informático, una base de datos es un sistema formado por un conjunto de datos almacenados en
discos que permiten el acceso directo a ellos y un conjunto de programas que manipulen ese
conjunto de datos. Por su parte, un sistema de Gestión de Bases de datos es un tipo de software muy
especifico dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la
utilizan; o lo que es lo mismo, una agrupación de programas que sirven para definir, construir y
manipular una base de datos, permitiendo así almacenar y posteriormente acceder a los datos de
forma rápida y estructurada. Actualmente, las bases de datos están teniendo un impacto decisivo
sobre el creciente uso de las computadoras.
- Cracteristicas
- Durante las décadas de los 60 y 70 surge el concepto de las bases de datos; sin embargo, el objetivo
principal siempre ha sido la administración óptima de la información y el uso que se le puede dar a
la misma. Hoy, las necesidades de las empresas han cambiado y la necesidad de interactuar con
diversas fuentes de información ha desafiado a las bases de datos. Lo anterior ha provocado que los
volúmenes de información sean mayores, su formato muy diverso lo que incrementa así los tiempos
de respuesta para analizar la información y tomar decisiones.
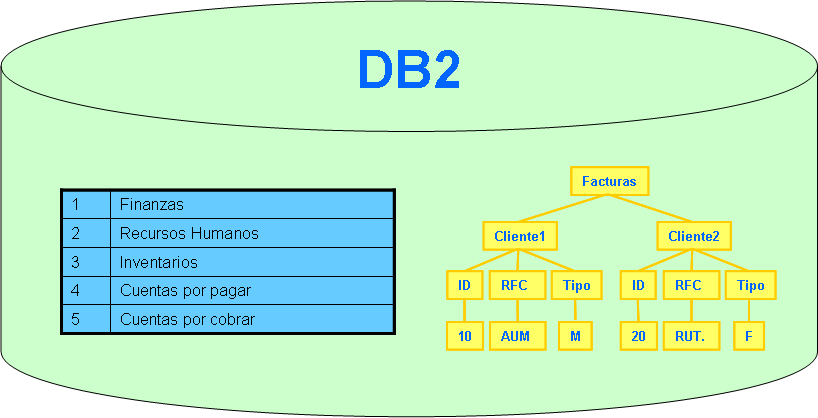
- ¿Qué es una base de datos?
- De una manera simple, es un contenedor que permite almacenar la información de forma ordenada
con diferentes propósitos y usos. Por ejemplo, en una base de datos se puede almacenar
información de diferentes departamentos (Ventas, Recursos Humanos, Inventarios, entre otros). El
almacenamiento de la información por sí sola no tiene un valor, pero si combinamos o relacionamos
la información con diferentes departamentos nos puede dar valor. Por ejemplo, combinar la
información de las ventas del mes de junio del 2014 para el producto ‘X’ en la zona norte nos da un
indicativo del comportamiento de las ventas en un periodo de tiempo.
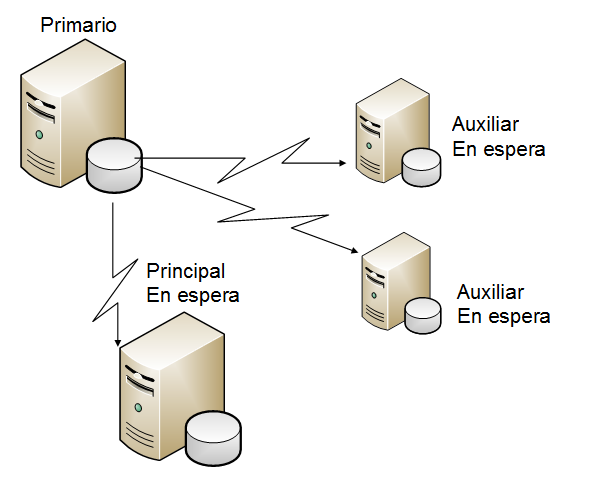
- ¿Qué es HADR?
- Sus siglas en inglés significan High Availability Disaster Recovery. Es una característica de replicación
de datos que brinda una solución de Alta Disponibilidad cuando surge una falla parcial o total en uno
de los servidores principales. Es una solución que soporta un Servidor como Primario y hasta tres
Servidores como Secundarios. Si el servidor primario falla, uno de los servidores secundarios tomará
el control y pasará a ser ahora el servidor primario. La replicación de la información se hace a través
de los archivos log de transacciones.
- Ventajas Minimiza el impacto de interrupciones planeada y no planeadas. Permite la actualización
del software sin interrumpir la operación. Para el aplicativo es transparente, no se requiere
modificar la aplicación. No se requiere Hardware especializado. Fácil administración y configuración.
- ¿Qué es PureScale?
- Es una arquitectura basada en Clúster. Un Clúster es un conjunto de varios ordenadores unidos por
una red de alta velocidad, de tal forma que es visto como un solo computador más potente. Es una
característica de DB2 que reduce el riesgo y los costos del crecimiento del negocio al proporcionar
capacidad extrema, disponibilidad continua y transparente para el aplicativo. Capacidad extrema
significa que puede crecer su sistema como sea necesario.
- Ventajas Evitar riesgos y costos en cambios a la aplicación. Diseñado para sistemas que requieren de
disponibilidad continua (24x7). Si uno o varios miembros fallan la transacción y operación del
sistema continua. Utiliza la misma arquitectura del indiscutible estándar de Oro, los Sistemas Z.
Agregar o quitar miembros de una manera fácil. No se requiere tunear la infraestructura de la base
de datos. Balanceo automático de cargas de trabajo. Construido y disponible en Power Systems y
servidores System x. El núcleo del sistema es una arquitectura de disco compartido.
- La implementación de HADR o PureScale dependerá de las necesidades y capacidades de cada
empresa. Otras soluciones han sido implementadas a nivel base de datos para hacer frente a los
problemas de performance. DB2 ofrece una gran variedad de alternativas para hacer frente a los
problemas de performance. DPF (Database Partition Feature). Particionamiento de bases de datos.
Table Partitioning. Particionamiento de tablas. MDC (Multi-Dimension Clustering). Convertir tablas en
múltiples dimensiones. Para tener un mejor entendimiento del tema de particionamiento se hace la
analogía de la frase “divide y vencerás”. Es el mismo principio utilizado en estas características de
DB2.
- Estructura de la base de datos
- La estructura de la base de datos es bastante sencilla. Las convenciones utilizadas aparecen
implícitamente en este documento. Por ejemplo, la mayoría de los objetos se indexan con un entero
autoincrementado cuyo nombre es de tipo id_objet, y que se declara como clave primaria en la tabla
apropiada.
- Modelo relacional de datos:
- En el nivel conceptual, el modelo relacional de datos está representado por una colección de
relaciones almacenadas. Cada registro de tipo conceptual en un modelo relacional de datos se
implanta como un archivo almacenado distinto.
- En el nivel conceptual, el modelo relacional de datos está representado por una colección de
relaciones almacenadas. Cada registro de tipo conceptual en un modelo relacional de datos se
implanta como un archivo almacenado distinto.
- Submodelo de datos:
- Los esquemas externos de un sistema relacional se llaman submodelos relacionales de datos; cada
uno consta de uno a más escenarios (vistas) para describir los datos requeridos por una aplicación
dada. Un escenario puede incluir datos de una o más tablas de datos. Cada programa de aplicación
está provisto de un buffer (“Area de trabajo de usuario”) donde el DBMS puede depositar los datos
recuperados de la base para su procesamiento, o puede guardar temporalmente sus salidas antes de
que el DBMS las escriba en la base de datos.
- Los esquemas externos de un sistema relacional se llaman submodelos relacionales de datos; cada
uno consta de uno a más escenarios (vistas) para describir los datos requeridos por una aplicación
dada. Un escenario puede incluir datos de una o más tablas de datos. Cada programa de aplicación
está provisto de un buffer (“Area de trabajo de usuario”) donde el DBMS puede depositar los datos
recuperados de la base para su procesamiento, o puede guardar temporalmente sus salidas antes de
que el DBMS las escriba en la base de datos.
- Esquema de almacenamiento:
- En el nivel interno, cada tabla base se implanta como un archivo almacenado. Para las
recuperaciones sobre las claves principal o secundaria se pueden establecer uno o más índices para
accesar un archivo almacenado.
- En el nivel interno, cada tabla base se implanta como un archivo almacenado. Para las
recuperaciones sobre las claves principal o secundaria se pueden establecer uno o más índices para
accesar un archivo almacenado.
- Sublenguaje de datos:
- Es un lenguaje de manejo de datos para el sistema relacional, el álgebra relacional y cálculo
relacional, ambos lenguajes son “relacionalmente completos”, esto es, cualquier relación que pueda
derivarse de una o más tablas de datos, también se puede derivar con u solo comando del
sublenguaje. Por tanto, el modo de operación de entrada/Salida en un sistema relacional se puede
procesar en la forma: una tabla a la vez en lugar de: un registro a la vez; en otras palabras, se puede
recuperar una tabla en vez de un solo registro con la ejecución de un comando del sublenguaje de
datos.
- Es un lenguaje de manejo de datos para el sistema relacional, el álgebra relacional y cálculo
relacional, ambos lenguajes son “relacionalmente completos”, esto es, cualquier relación que pueda
derivarse de una o más tablas de datos, también se puede derivar con u solo comando del
sublenguaje. Por tanto, el modo de operación de entrada/Salida en un sistema relacional se puede
procesar en la forma: una tabla a la vez en lugar de: un registro a la vez; en otras palabras, se puede
recuperar una tabla en vez de un solo registro con la ejecución de un comando del sublenguaje de
datos.
- Modelo relacional de datos:
- La estructura de la base de datos es bastante sencilla. Las convenciones utilizadas aparecen
implícitamente en este documento. Por ejemplo, la mayoría de los objetos se indexan con un entero
autoincrementado cuyo nombre es de tipo id_objet, y que se declara como clave primaria en la tabla
apropiada.
- Estructura de la base de datos
- La implementación de HADR o PureScale dependerá de las necesidades y capacidades de cada
empresa. Otras soluciones han sido implementadas a nivel base de datos para hacer frente a los
problemas de performance. DB2 ofrece una gran variedad de alternativas para hacer frente a los
problemas de performance. DPF (Database Partition Feature). Particionamiento de bases de datos.
Table Partitioning. Particionamiento de tablas. MDC (Multi-Dimension Clustering). Convertir tablas en
múltiples dimensiones. Para tener un mejor entendimiento del tema de particionamiento se hace la
analogía de la frase “divide y vencerás”. Es el mismo principio utilizado en estas características de
DB2.
- Ventajas Evitar riesgos y costos en cambios a la aplicación. Diseñado para sistemas que requieren de
disponibilidad continua (24x7). Si uno o varios miembros fallan la transacción y operación del
sistema continua. Utiliza la misma arquitectura del indiscutible estándar de Oro, los Sistemas Z.
Agregar o quitar miembros de una manera fácil. No se requiere tunear la infraestructura de la base
de datos. Balanceo automático de cargas de trabajo. Construido y disponible en Power Systems y
servidores System x. El núcleo del sistema es una arquitectura de disco compartido.
- Es una arquitectura basada en Clúster. Un Clúster es un conjunto de varios ordenadores unidos por
una red de alta velocidad, de tal forma que es visto como un solo computador más potente. Es una
característica de DB2 que reduce el riesgo y los costos del crecimiento del negocio al proporcionar
capacidad extrema, disponibilidad continua y transparente para el aplicativo. Capacidad extrema
significa que puede crecer su sistema como sea necesario.
- ¿Qué es PureScale?
- Ventajas Minimiza el impacto de interrupciones planeada y no planeadas. Permite la actualización
del software sin interrumpir la operación. Para el aplicativo es transparente, no se requiere
modificar la aplicación. No se requiere Hardware especializado. Fácil administración y configuración.
- Sus siglas en inglés significan High Availability Disaster Recovery. Es una característica de replicación
de datos que brinda una solución de Alta Disponibilidad cuando surge una falla parcial o total en uno
de los servidores principales. Es una solución que soporta un Servidor como Primario y hasta tres
Servidores como Secundarios. Si el servidor primario falla, uno de los servidores secundarios tomará
el control y pasará a ser ahora el servidor primario. La replicación de la información se hace a través
de los archivos log de transacciones.
- ¿Qué es HADR?
- De una manera simple, es un contenedor que permite almacenar la información de forma ordenada
con diferentes propósitos y usos. Por ejemplo, en una base de datos se puede almacenar
información de diferentes departamentos (Ventas, Recursos Humanos, Inventarios, entre otros). El
almacenamiento de la información por sí sola no tiene un valor, pero si combinamos o relacionamos
la información con diferentes departamentos nos puede dar valor. Por ejemplo, combinar la
información de las ventas del mes de junio del 2014 para el producto ‘X’ en la zona norte nos da un
indicativo del comportamiento de las ventas en un periodo de tiempo.
- Tipos de bases de datos
- Existen muchas empresas con diferentes giros y dependiendo del giro será el tipo de procesamiento
que se le dará a la información, esto determinará el tipo de base de datos a utilizar. Existen
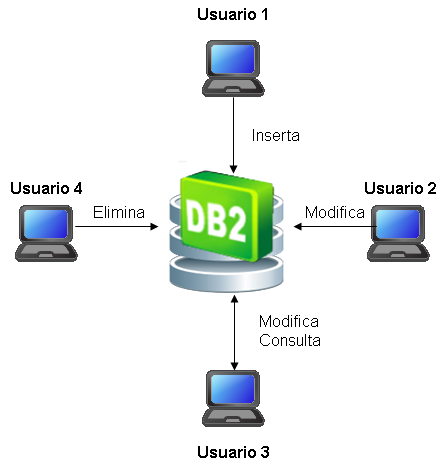
diferentes tipos de bases de datos pero las más comunes son las OLTP y OLAP. Las bases de datos de
tipo OLTP (On Line Transaction Processing) también son llamadas bases de datos dinámicas lo que
significa que la información se modifica en tiempo real, es decir, se insertan, se eliminan, se
modifican y se consultan datos en línea durante la operación del sistema. Un ejemplo es el sistema
de un supermercado donde se van registrando cada uno de los artículos que el cliente está
comprando y a su vez el sistema va actualizando el Inventario.
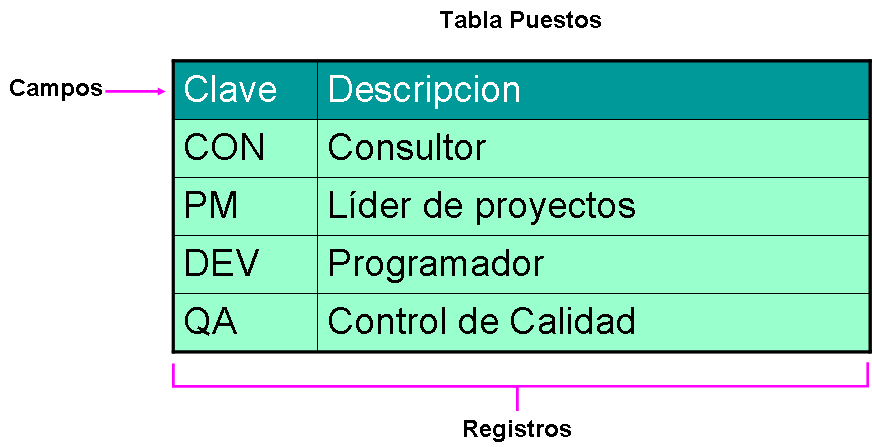
- Tipo de información que se puede almacenar
- Cuando surgen las bases de datos el tipo de información que se podía almacenar era de tipo
estructurada. La información es almacenada en un objeto llamado “Tabla” la cual nos permite
organizar la información. Por ejemplo, la tabla de “Empleados” contiene información relacionada al
#Empleado, Nombre, Apellido, #Seguro Social, etc. Cada uno de estos elementos en una base de
datos recibe el nombre de “Campo” y el conjunto de estos elementos recibe el nombre de “Registro”
(También llamado Columna y Renglón, Hilera o Fila).
- os tipos de datos que se pueden almacenar son diversos, pero los más comunes son de tipo
Numérico, Decimales y tipo Texto. Conforme han evolucionado las bases de datos se han expandido
los tipos de datos que pueden almacenar. Por mencionar algunos tipos están los CLOB (Character
Large Object) y BLOB (Binary Large Object). Los CLOB son utilizados para almacenar documentos y
los BLOB para almacenar una imagen o video.
- Una ventaja competitiva que tiene DB2 es que los documentos XML se almacenan de forma nativa,
es decir, el documento se almacena dentro de la base de datos, lo que permite consultar la
información de forma directa y con mucho mejor desempeño. Incluso se pueden crear índices a nivel
documento XML para consultar un nodo en específico, y así acceder más rápido a la información.
Otra ventaja es la compresión de documento XML lo cual incrementa el ahorro en almacenamiento.
- Con la evolución en las tecnologías de la información y las nuevas necesidades en el manejo de la
información nace el concepto Big Data. Existen diferentes definiciones, pero la más sencilla es el
manejo de grandes volúmenes de información que vienen de diferentes fuentes de datos
(Estructurados, No estructurados, XML, HTML, etc.) de una manera rápida sin afectar la
disponibilidad de la información y operación de los sistemas. Las consultas hechas en Big Data
ayudan al análisis y a la toma de decisiones.
- Con la evolución en las tecnologías de la información y las nuevas necesidades en el manejo de la
información nace el concepto Big Data. Existen diferentes definiciones, pero la más sencilla es el
manejo de grandes volúmenes de información que vienen de diferentes fuentes de datos
(Estructurados, No estructurados, XML, HTML, etc.) de una manera rápida sin afectar la
disponibilidad de la información y operación de los sistemas. Las consultas hechas en Big Data
ayudan al análisis y a la toma de decisiones.
- Una ventaja competitiva que tiene DB2 es que los documentos XML se almacenan de forma nativa,
es decir, el documento se almacena dentro de la base de datos, lo que permite consultar la
información de forma directa y con mucho mejor desempeño. Incluso se pueden crear índices a nivel
documento XML para consultar un nodo en específico, y así acceder más rápido a la información.
Otra ventaja es la compresión de documento XML lo cual incrementa el ahorro en almacenamiento.
- os tipos de datos que se pueden almacenar son diversos, pero los más comunes son de tipo
Numérico, Decimales y tipo Texto. Conforme han evolucionado las bases de datos se han expandido
los tipos de datos que pueden almacenar. Por mencionar algunos tipos están los CLOB (Character
Large Object) y BLOB (Binary Large Object). Los CLOB son utilizados para almacenar documentos y
los BLOB para almacenar una imagen o video.
- Cuando surgen las bases de datos el tipo de información que se podía almacenar era de tipo
estructurada. La información es almacenada en un objeto llamado “Tabla” la cual nos permite
organizar la información. Por ejemplo, la tabla de “Empleados” contiene información relacionada al
#Empleado, Nombre, Apellido, #Seguro Social, etc. Cada uno de estos elementos en una base de
datos recibe el nombre de “Campo” y el conjunto de estos elementos recibe el nombre de “Registro”
(También llamado Columna y Renglón, Hilera o Fila).
- Tipo de información que se puede almacenar
- Existen muchas empresas con diferentes giros y dependiendo del giro será el tipo de procesamiento
que se le dará a la información, esto determinará el tipo de base de datos a utilizar. Existen
diferentes tipos de bases de datos pero las más comunes son las OLTP y OLAP. Las bases de datos de
tipo OLTP (On Line Transaction Processing) también son llamadas bases de datos dinámicas lo que
significa que la información se modifica en tiempo real, es decir, se insertan, se eliminan, se
modifican y se consultan datos en línea durante la operación del sistema. Un ejemplo es el sistema
de un supermercado donde se van registrando cada uno de los artículos que el cliente está
comprando y a su vez el sistema va actualizando el Inventario.
- ¿Qué es una base de datos?
- Durante las décadas de los 60 y 70 surge el concepto de las bases de datos; sin embargo, el objetivo
principal siempre ha sido la administración óptima de la información y el uso que se le puede dar a
la misma. Hoy, las necesidades de las empresas han cambiado y la necesidad de interactuar con
diversas fuentes de información ha desafiado a las bases de datos. Lo anterior ha provocado que los
volúmenes de información sean mayores, su formato muy diverso lo que incrementa así los tiempos
de respuesta para analizar la información y tomar decisiones.
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.