9024784
Description
Quiz by Benjamin Maier, updated more than 1 year ago
|
|
Created by Benjamin Maier
almost 7 years ago
|
|
Question 1
Question
What is the purpose of a one-way ANOVA (between or within groups)? And how is it different to a t-test?
Answer
-
A one-way ANOVA examines the difference between three (or more) levels/groups in one variable, whereas a t-test only examines the difference between two levels/groups in one variable.
-
A one-way ANOVA examines the difference between three (you can't examine more than three) levels/groups in one variable, whereas a t-test only examines the difference between two levels/groups in one variable.
-
A one-way ANOVA examines the difference between four (or more) levels/groups in one variable, whereas a t-test only examines the difference between three levels/groups in one variable.
-
A one-way ANOVA examines the difference between two (or more) levels/groups in one variable, whereas a t-test only examines the difference between three levels/groups in one variable.
Question 2
Question
In an one-way independent measures ANOVA, how is the variance split in terms of sums of squares? And which sum of squares tells us how much variance is explained by our hypothesis that the three groups are different?
Answer
-
First you have the total sum of squares (SST), which is made up of the model sum of squares (SSM) and the residual sum of squares (SSR). SSM tells us how much variance is explained by our hypothesis or model.
-
First you have the model sum of squares (SSM), which is made up of the total sum of squares (SST) and the residual sum of squares (SSR). SST tells us how much variance is explained by our hypothesis or model.
-
First you have the total sum of squares (SST), which is made up of the model sum of squares (SSM) and the residual sum of squares (SSR). The none of the sum of squares values tell us how much of the variance is explained by our hypothesis.
-
First you have the residual sum of squares (SSR), which is made up of the model sum of squares (SSM) and the total sum of squares (SST). SSM tells us how much variance is explained by our hypothesis or model.
Question 3
Question
In a repeated measure ANOVA how is the variance split in terms of sums of squares? And which sum of squares value tells us how much variance is explained by our hypothesis - that the group will be different in each condition?
Answer
-
First, total sum of squares (SST) shows the total variation in the data, this is made of the sum of squares for between participant variation (SSB) and the sum of squares for within participant variation (SSW). In the SSW we can further split the variation into the model sum of squares (SSM) and the residual sum of squares (SSR). SSM tells us how much variance is explained by our hypothesis.
-
First, total sum of squares (SST) shows the total variation in the data, this is made of the sum of squares for between participant variation (SSB) and the sum of squares for within participant variation (SSW). SSW tells us how much variance is explained by our hypothesis.
-
First, total sum of squares (SST) shows the total variation in the data, this is made of the model sum of squares (SSM) and the residual sum of squares (SSR). SST tells us how much variance is explained by our hypothesis.
-
First, total sum of squares (SST) shows the total variation in the data, this is made of the sum of squares for within participant variation (SSW) and the sum of squares for between participant variation (SSB). In the SSB we can further split the variation into the model sum of squares (SSM) and the residual sum of squares (SSR). SSR tells us how much variance is explained by our hypothesis.
Question 4
Question
Why can't we use the sum of squares to calculate the F ratio in one-way ANOVA?
Answer
-
Because the sum of squares are influenced by the number of scores summed.
-
This is a trick question - we do use the sum of squares, its the mean squares we don't use.
-
Because the sum of squares are influenced by the degrees of freedom but mean squares are not.
-
Because the sum of squares are influenced by the F ratio.
Question 5
Question
In a one-way ANOVA, if our F value is more than 1 - what does this mean?
Answer
-
That our MSM is larger than our MSR. This means that there has been an effect of the variable between the groups/within the group - although we don't know if this is significant.
-
That our MSR is larger than our MSM. This means that there has been an effect of the variable between the groups/within the group - although we don't know if this is significant.
-
That our MSM is larger than our MSR. This means that there has not been an effect of the variable between the groups/within the group - although we don't know if this is significant.
-
That our MSM is larger than our MSR. This means that there has been an effect of the variable between the groups/within the group - and we know that this is significant.
Question 6
Question
Which of the following is NOT an assumption of an independent samples ANOVA?
Answer
-
Sphericity.
-
Interval level data.
-
Normal distribution.
-
Homogeneity of variance.
Question 7
Question
Which of the following is NOT an assumption of a repeated measures ANOVA?
Answer
-
Independence of groups.
-
Sphericity.
-
Interval level data.
-
Normal distribution.
Question 8
Question
One-Way ANOVA: If the assumption of homogeneity is broken - which test should you use instead?
Answer
-
Bonferroni.
-
Tukey.
-
Brown-Forsythe.
-
Welch.
Question 9
Question
If your assumption of sphericity is broken - which part of the output should you read instead?
Answer
-
Mauchly.
-
Greenhouse-Geisser.
-
Lower-bound.
-
Levene.
Question 10
Question
Can SPSS calculate an effect size for a one-way ANOVA?
Answer
-
Yes, but only for independent measures - you should calculate it yourself for repeated measures.
-
Yes, but only for repeated measures - you should calculate it yourself for independent measures.
-
Yes, for both.
-
No.
Question 11
Question
I'm doing a three-way ANOVA with a 3x3x2 design. What does this tell you?
Answer
-
That this experiment has 2 IVs. Two of them have 3 levels.
-
That this experiment has 3 IVs. Three of them have 3 levels.
-
That this experiment has 3 levels. Two of them have 3 IVs and one has two.
-
That this experiment has 3 IVs. Two of them have 3 levels and one has two.
Question 12
Question
What information do we get from a factorial ANOVA?
Answer
-
We can see the main effects of each IV.
-
We can see the main effects of each DV.
-
We can see the main effects of each IV and how they interact.
-
We can see the main effects of each DV and how they interact.
Question 13
Question
Within the variability explained by SSM, how can we further split the variance in an independent measures factorial ANOVA?
Answer
-
The variance explained by SSM is made up of the MS for each variable plus the MS for the interactions.
-
The variance explained by SSM is made up of the SS for each variable plus the SS for the interactions
-
The variance explained by SSM is made up of only the SS for each variable.
-
You cannot further split the variance explained by SSM.
Question 14
Question
I have two IVs: stats knowledge (SSA) and psychology knowledge (SSB). How do we calculate SSA?
Answer
-
We collapse across SSB and look only at the scores split by the stats knowledge variable as compared to the grand mean.
-
We collapse and look only at the scores split by the psych knowledge variable as compared to the grand mean.
-
We collapse across SSB and look only at the scores split by the stats knowledge variable as compared to the participants' means.
-
SSA is the same as SSM in this context.
Question 15
Question
Independent Samples Factorial ANOVA: How do I calculate SSAxB? And what does it tell me?
Answer
-
After calculating SSA and SSB then the remaining variance accounted for by SST is the variance from SSAxB. This is the interaction between the two variables.
-
After calculating SSA and SSB then the remaining variance accounted for by SSM is the variance from SSAxB. This is the main effects between the two variables.
-
You do not get SSAxB in independent samples factorial ANOVA.
-
After calculating SSA and SSB then the remaining variance accounted for by SSM is the variance from SSAxB. This is the interaction between the two variables.
Question 16
Question
What is an interaction?
Answer
-
When the effect of one DV on the IV is dependent on another DV.
-
When both IVs have a main effect.
-
When the effect of one IV on the DV is dependent on another IV.
-
When both DVs have a main effect.
Question 17
Question
I've graphed the interaction between stats knowledge (two levels) and psychology knowledge (two levels) and their effect on a test score. What does this interaction show?
Image:
Picture1 (image/png)
{kind=link}
Answer
-
That participants that had good clinical psychology knowledge and good parametric scored highly on the test, however this did not occur for those with good clinical psychology knowledge and good non-parametric knowledge. The converse was true for those in the good neuropsychology group.
-
That participants that had good clinical psychology knowledge and good non-parametric knowledge scored highly on the test, however this did not occur for those with good clinical psychology knowledge and good parametric knowledge. The converse was true for those in the good neuropsychology knowledge group.
-
That participants that had good clinical psychology knowledge and good parametric knowledge scored highly on the test, however this did not occur for those with good clinical psychology knowledge and good non-parametric knowledge. The same was true for those in the good neuropsychology knowledge group.
-
That participants that had good clinical psychology knowledge scored highly on the test, however, the converse was true for those in the good neuropsychology knowledge group.
Question 18
Question
If my study is a between-subjects-design - am I concerned about whether my data breaks the assumption of homogeneity or the assumption of sphericity? And what would I expect to see if this assumption had been met?
Answer
-
Homogeneity of variance - the Levene's test should be significant.
-
Sphericity - the Mauchly's test should not be significant.
-
Homogeneity of variance - the Levene's test should not be significant.
-
Sphericity - the Mauchly's test should be significant.
Question 19
Question
After completing our factorial ANOVA - why do we employ syntax to look at the interaction?
Answer
-
Because this is the best way to explore the differences between the different levels of an interaction.
-
Trick question - this is only used the examine main effects.
-
We don't - multiple comparisons tells us enough.
-
Because we want to examine the differences between the IVs.
Question 20
Question
Factorial ANOVA: Why can't we only interpret the F from the SSM line of the output?
Answer
-
Trick question - we only interpret the SSM line of output in factorial ANOVA.
-
Because we need to know how much variance is explained by the SSR output, which is part of the variance explained by SSM.
-
Because we don't just need to know how much variance is explained by the model but whether each individual variable is explaining a significant amount of variance.
-
Because we don't just need to know how much variance is explained by the model but whether each individual variance and their interactions are explaining a significant amount of variance.
Question 21
Question
How do we partition the variance for SSM in factorial repeated measures ANOVA?
Answer
-
We split it into SSA and SSB.
-
We split it into SSA, SSB and SSAxB.
-
We don't split the variance beyond SSM.
-
We split it into SSA and SSAxB.
Question 22
Question
How do we partition the variance for SSR in a repeated measures factorial ANOVA?
Answer
-
We don't partition the variance of SSR.
-
Into SSRA and SSRB.
-
Into SSRA, SSRB and SSRAxB
-
Into SSRA and SSRAxB.
Question 23
Question
Factorial Repeated Measures ANOVA: Which formula do I use to calculate F for one of my main effects?
Answer
-
MSA/MSRA
-
MSA/MSR
-
MSA/dfA
-
MSA/MSB
Question 24
Question
In a repeated measures ANOVA are we concerned with Homogeneity of Variance or Sphericity? And what do we expect to see if the assumption has been met?
Answer
-
Sphericity - Mauchly's test should be significant.
-
Homogeneity of Variance - Levene's test should not be significant.
-
Sphericity - Mauchly's test should not be significant.
-
Homogeneity of Variance - Levene's test should be significant.
Question 25
Question
Below is my syntax for a 2-way-3x2 repeated measures ANOVA. IV1 Time of Meal (Breakfast, Lunch and Dinner), IV2 Day (Day1, Day2). I'm missing a section of the syntax - complete it.
GLM BreakfastDay1 BreakfastDay2 LunchDay1 LunchDay2 DinnerDay1 DinnerDay2
/WSFACTOR [COMPLETE THIS LINE]
/EMMEANS = TABLES(TimeMeal*Day) COMPARE(Day)
Answer
-
TimeMeal 2 Day 3
-
Day 3 TimeMeal 2
-
TimeMeal 3 Day 2
-
TimeDay6
Question 26
Question
How is an interaction different from a main effect?
Answer
-
For a main effect: IV1 will have the same effect on the DV in all levels of IV2. In an interaction: IV1 will only effect the DV in specific levels of IV2.
-
For main effect: IV1: IV1 will have the same effect on the DV in specific levels of IV2. In an interaction: IV1 will ave the same effect on the DV in all levels of IV2.
-
Main effects and interactions are the same.
-
For a main effect: DV1 will have the same effect on the IV in all levels of DV2. In an interaction: DV1 will only effect the IV in specific levels of DV2.
Question 27
Question
I've conducted an experiment examining real vs sham brain stimulation on a verbal fluency experiment. I've recorded number of words produced to the letter S in one minute at Pre, During and Post stimulation. The graph of my results is below. What is the interaction showing?
Image:
Picture1 (image/png)
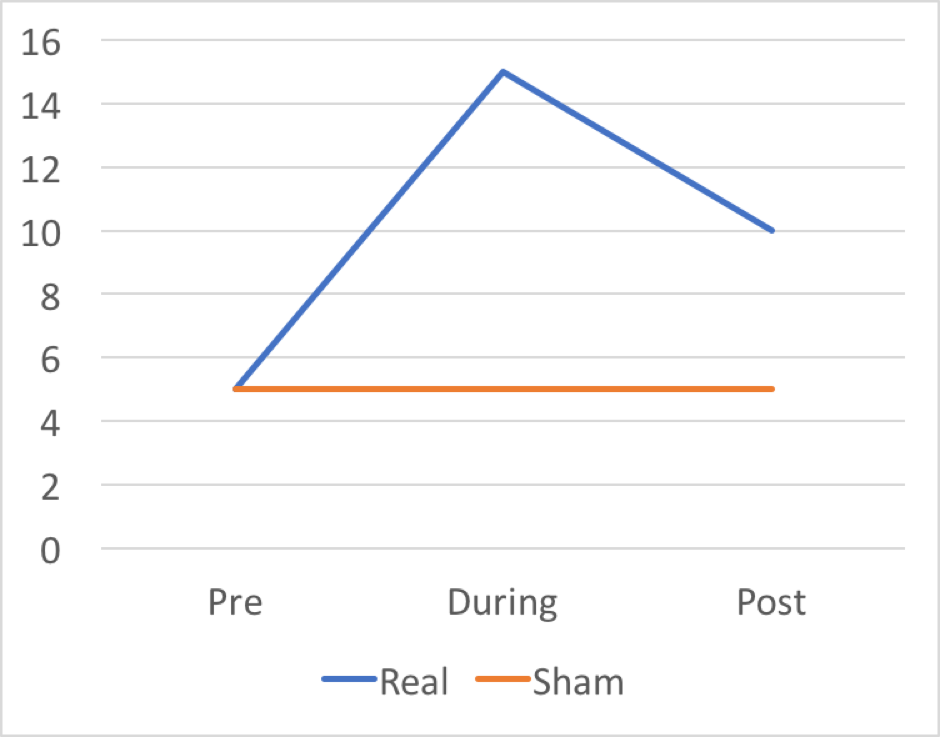{kind=link}
Answer
-
Sham stimulation increased performance as compared to Real, but only During stimulation and Post stimulation - there was no difference Pre stimulation.
-
Real stimulation increased performance as compared to Sham, but only During stimulation and Post stimulation - there was no difference Pre stimulation.
-
Real stimulation increased performance as compared to Sham, but only Pre stimulation and Post stimulation - there was no difference During stimulation.
-
There is no interaction between these variables.
Question 28
Question
Which is a mixed factorial design?
Answer
-
A design which has 3+ IVs. At least one of which is between subjects and one within subjects.
-
A design which has 2+ IVs. At least one of which is between subjects and one within subjects.
-
A design which has 2+ IVs. Both of which is between subjects.
-
A design which has 2+ IVs. Both of which is within subjects.
Question 29
Question
In a mixed factorial ANOVA are we concerned with Homogeneity of Variance or Sphericity?
Answer
-
Only Homogeneity of Variance.
-
Only Sphericity which applies when the within subjects IV has 3+ levels as with repeated measures designs that are not mixed.
-
Both, but Sphericity only applies when the within subjects IV has 3+ levels as with repeated measures designs that are not mixed.
-
Only Sphericity which applies when the within subjects IV has 2+ levels as with repeated measures designs that are not mixed.
Question 30
Question
In SPSS, what process do we use to complete a mixed factorial ANOVA?
Answer
-
The same as for independent measures ANOVA but we add in the between subjects variable at the 'define' stage.
-
Mixed ANOVA uses its own process which is entirely different from repeated and independent measures ANOVA.
-
The same as for repeated measures ANOVA but we add in the between subjects variable at ehe 'Post Hoc' stage.
-
The same as for repeated measures ANOVA but we add in the between subjects variable at the 'define' stage.
Question 31
Question
Assuming the data meet the assumption of parametric tests, non-parametric tests compared to their parametric counterparts _______________.
Answer
-
are less conservative
-
are less likely to accept the alternative hypothesis
-
have less statistical power
-
All of the above.
Question 32
Question
A researcher measured leadership skills in police officers, doctors, and accountants. There were unequal group sizes and the data were skewed. What test should be used to analyse the data?
Answer
-
Wilcoxon test.
-
Kruskal-Wallis test.
-
One-Way ANOVA.
-
Friedman test.
Question 33
Question
The results of the test used to analyse the data in the Question: "A researcher measured leadership skills in police officers, doctors, and accountants. There were unequal group sizes and the data were skewed. What test should be used to analyse the data?" showed a significant result. How should the researcher carry out post-hoc tests?
Answer
-
Compare groups using the Mann Whitney test.
-
Compare groups using the Wilcoxon test.
-
Compare groups using a t-test.
-
None of the above. Post-hoc analyses cannot be carried out with non-parametric data.
Question 34
Question
An advantage of non-parametric statistics is that __________.
Answer
-
you need a computer to calculate them
-
they have many assumptions to meet
-
they are easy to calculate
-
they are very powerful
Question 35
Question
Which of the following tests is analogous to a standard within-subjects ANOVA?
Answer
-
Mann-Whitney.
-
Friedman.
-
Wilcoxon.
-
Kruskal-Wallis.
Question 36
Question
Tied scores (when two or more scores have the same value) may present a problem in non-parametric tests. The way to deal with them in a Kruskal-Wallis test is to _________.
Answer
-
Throw out the tied data.
-
Assign any tied values the average of the ranks they would been received had they not been tied.
-
Use a random number table to assign ranks to the tied values.
-
Assign any tied numbers the lower of the ranks they would have received had they not been tied.
Question 37
Question
A dataset contains the following values: 23, 28, 37, 23, 45, 49, 37, 62. Rank the values. Which rank is associated with value 37?
Answer
-
3.5
-
4
-
4.5
-
6
Question 38
Question
Researchers wanted to examine whether the 'see-food' diet was effective. A group of volunteers were placed on the diet and their weight (in kilograms) was measured at the beginning of the diet, after 1 month, after 2 months, then at the end of the diet after 3 months. The data were not normally distributed. Which test would be appropriate to analyse this data?
Answer
-
Mann-Whitney.
-
Friedman.
-
Wilcoxon.
-
Kruskal-Wallis.
Question 39
Question
The SPSS output from the study described in the question: "Researchers wanted to examine whether the 'see-food' diet was effective. A group of volunteers were placed on the diet and their weight (in kilograms) was measured at the beginning of the diet, after 1 month, after 2 months, then at the end of the diet after 3 months. The data were not normally distributed. Which test would be appropriate to analyse this data?"
What is the correct way to report these results? (x^2 = Chi-squared)
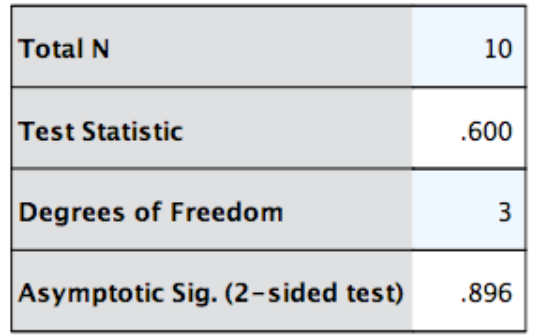{kind=link}
Answer
-
The weight of participants did not significantly change during the diet, x^2 (3) = 0.60, p = .90
-
The weight of participants did not significantly change during the diet, x^2 (x) = 0.60, p = .89
-
The weight of participants significantly changed during the diet, x^2 (3) = 0.60, p < .50
-
The weight of participants significantly changed during the diet, x^2 (3) = .60, p > .05
Question 40
Question
In a Kruskal-Wallis test, the ___________ the value of H, the more likely you are to reject the null hypothesis.
Answer
-
larger
-
smaller
-
more negative
-
H is not relevant for the Kruskal-Wallis test.
Question 41
Question
What assumption does ANCOVA have that ANOVA does not?
Answer
-
Homogeneity of Variance.
-
Homoscedasticity.
-
Homogeneity of Sample Size.
-
Homogeneity of Regression Slopes.
Question 42
Question
ANCOVA is _____________.
Answer
-
used to correct for unmeasured variables that could affect the outcome variable
-
a method of portioning the results of ANOVAs to investigate where differences between independent variables lie
-
a robust version of ANOVA
-
an extension of ANOVA that partials out the effect of other measured variables
Question 43
Question
A researcher conducted a study to examine whether people's attachment styles are associated with differences in relationship satisfaction. Participants were divided into three groups according to their attachment styles (secure, dismissing, and fearful) and their relationship satisfaction was measured. Depression levels were also measured, as it is known that relationship satisfaction covaries with depression. Which variable should the researcher use a covariate in the data analysis?
Answer
-
Attachment style.
-
Secure attachment.
-
Depression.
-
Relationship satisfaction.
Question 44
Question
Regarding the study described in the question:
"A researcher conducted a study to examine whether people's attachment styles are associated with differences in relationship satisfaction. Participants were divided into three groups according to their attachment styles (secure, dismissing, and fearful) and their relationship satisfaction was measured. Depression levels were also measured, as it is known that relationship satisfaction covaries with depression. Which variable should the researcher use a covariate in the data analysis?"
which of the below questions would be relevant to the data analysis?
Answer
-
Does relationship satisfaction have a significant effect on the relationship between attachment and depression?
-
What would the means of the groups be on relationship satisfaction if their levels of depression were constant?
-
What would the mean relationship satisfaction be if levels of depression were constant?
-
What would the mean depression score be for the three groups of attachment styles if their levels of relationship satisfaction were constant?
Question 45
Question
What problem do you foresee with the study described in the question:
"A researcher conducted a study to examine whether people's attachment styles are associated with differences in relationship satisfaction. Participants were divided into three groups according to their attachment styles (secure, dismissing, and fearful) and their relationship satisfaction was measured. Depression levels were also measured, as it is known that relationship satisfaction covaries with depression. Which variable should the researcher use a covariate in the data analysis?"?
Answer
-
There could be more than three groups.
-
It is likely that there will be a linear association between depression and relationship satisfaction.
-
It is likely that the regression lines will be parallel.
-
Depression might also be related to attachment style.
Question 46
Question
The larger the F statistic, the larger the ________ compared to the ________.
Answer
-
variation between groups; variation within groups
-
variation within groups; variation between groups
-
variation between groups; total variation
-
total variation; variation between groups
Question 47
Question
A covariate is best described as ___________.
Answer
-
a variable that is related to the dependent variable
-
a variable that is directly influenced by the dependent variable
-
a variable that is related to the independent variable
-
a variable that is unrelated to all other variables in the study
Question 48
Question
A researcher wanted to see whether giving students caffeine would improve their memory. He gave all students a memory test, then he randomly assigned participants to two groups. One group received a caffeinated drink and the other group received a decaffeinated drink. Both group then took another memory test (with different questions). The researcher used ANCOVA to analyse the data. Which variable was the covariate?
Answer
-
Caffeine.
-
Score on the first memory test.
-
Score on the second memory test.
-
There was no covariate.
Question 49
Question
The SPSS output from the ANCOVA is shown below. What is the correct way to report these results?
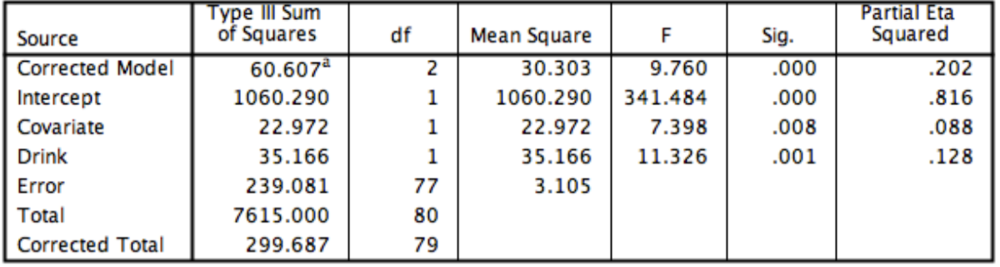{kind=link}
Answer
-
There was a significant effect of caffeine on memory after controlling for the effect of the covariate, F (1, 77) = 11.33, p = .001
-
There was no significant effect of caffeine on memory after controlling for the effect of the covariate, F (1, 77) = 11.33, p > .05
-
There was a significant effect of caffeine on memory after controlling for the effect of the covariate, F (1, 77) = 7.40, p = .008
-
There was no significant effect of caffeine on memory after controlling for the effect of covariate, F (1, 77) = 341.48, p < .001
Question 50
Question
According to this output, which of the following statements is true?
Answer
-
There was no significant relationship between the covariate and the dependent variable.
-
There was a significant relationship between the covariate and the dependent variable.
-
The data violate the assumption of equal variances.
-
The data do not violate the assumption of equal variances.
Question 51
Question
What would you use Box's test for?
Answer
-
To test for multivariate normality.
-
To test for a plausible linear combination of the dependent variables.
-
To test for homogeneity of variance.
-
To test for homogeneity of covariance matrices.
Question 52
Question
If you MANOVA is statistically significant:
Answer
-
You could conduct separate Bonferroni-corrected ANOVAs on each dependent variable.
-
There is no added value in performing discriminant function analysis.
-
You could conclude that all groups differ significantly.
-
None of the above are correct.
Question 53
Question
How does MANOVA handle the dependent variables (DVs) in the analysis?
Answer
-
The DVs are compiled into a linear combination.
-
The DVs are entered sequentially into a model.
-
The DVs are entered stepwise into an analysis.
-
The DVs are standardised and summed.
Question 54
Question
Which one of these might you consider a violation in MANOVA, suggesting it may be better to use an alternative analysis?
Answer
-
You have 30 participants per group in you between participants design.
-
You have equal numbers of participants and it is a large sample size.
-
You have normally distributed dependent variables and all linear combinations of the dependent variables.
-
Box's M has an associated p-value of <0.05 and you have unequal sample sizes.
Question 55
Question
The difference between MANOVA and ANOVA is that MANOVA has the ability to handle __________.
Answer
-
several dependent variables
-
several independent variables
-
non-metric independent variables
-
data with large error terms
Question 56
Question
A researcher wanted to examine the effects of a new antidepressant drug. She recruited 60 clinically depressed participants and randomly allocated them to three conditions: No dose (placebo), low dose and medium dose of the drug. She administered the drugs to participants for one month, then measured their mood levels by asking them to complete a self-report measure. However, she decided that mood should not just be measured by self-report, so she also asked the participants' psychiatrists to give their ratings of each person's mood. All mood ratings were measured on a 1-50 scale, with 1 indicating the lowest possible mood and 50 indicating the highest possible mood. The SPSS output from the data analysis is shown below.
Are the assumptions of MANOVA met?
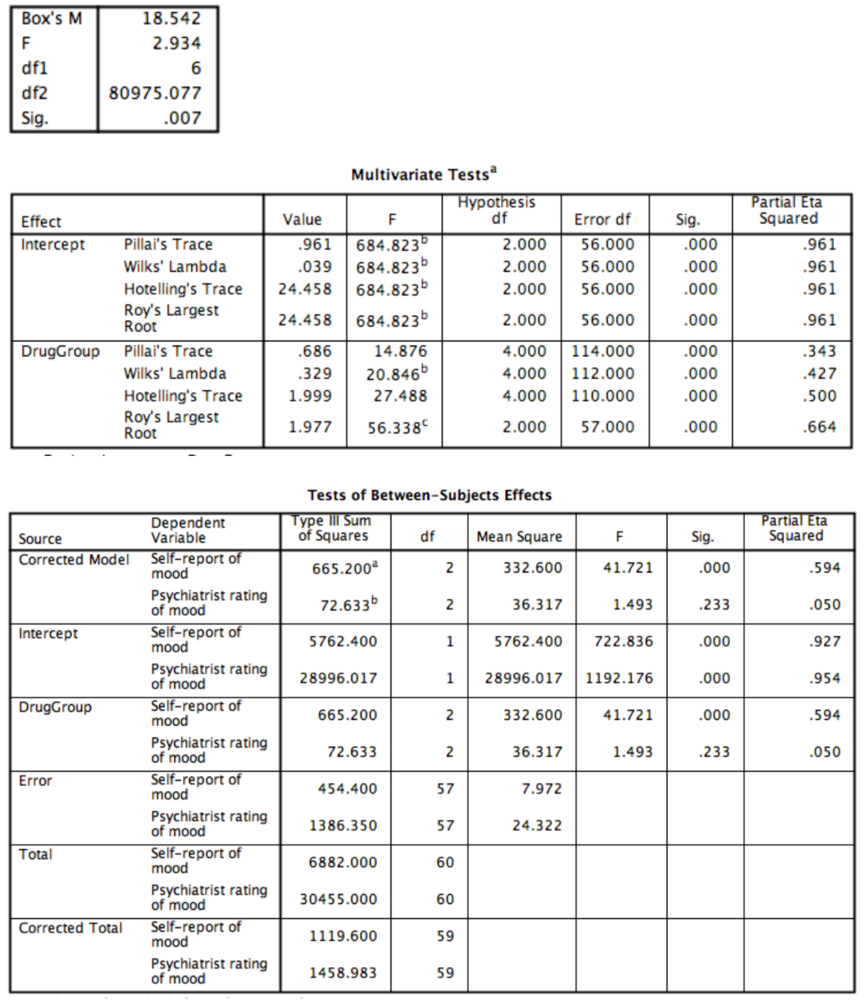{kind=link}
Answer
-
Yes.
-
No, the assumption of equality of covariance matrices is violated.
-
No, the assumption of multivariate normality is violated.
-
It is not possible to tell from this output.
Question 57
Question
A researcher wanted to examine the effects of a new antidepressant drug. She recruited 60 clinically depressed participants and randomly allocated them to three conditions: No dose (placebo), low dose and medium dose of the drug. She administered the drugs to participants for one month, then measured their mood levels by asking them to complete a self-report measure. However, she decided that mood should not just be measured by self-report, so she also asked the participants' psychiatrists to give their ratings of each person's mood. All mood ratings were measured on a 1-50 scale, with 1 indicating the lowest possible mood and 50 indicating the highest possible mood. The SPSS output from the data analysis is shown below.
Which of the following statements about the output is true?
Answer
-
There is a significant multivariate difference between the drug groups.
-
Significant univariate differences are only present for psychiatrist ratings of mood.
-
Self-report ratings of mood are significantly higher than psychiatrist ratings of mood.
-
All of the above are true.
Question 58
Question
A researcher wanted to examine the effects of a new antidepressant drug. She recruited 60 clinically depressed participants and randomly allocated them to three conditions: No dose (placebo), low dose and medium dose of the drug. She administered the drugs to participants for one month, then measured their mood levels by asking them to complete a self-report measure. However, she decided that mood should not just be measured by self-report, so she also asked the participants' psychiatrists to give their ratings of each person's mood. All mood ratings were measured on a 1-50 scale, with 1 indicating the lowest possible mood and 50 indicating the highest possible mood. The SPSS output from the data analysis is shown below.
Which of the following might be a problem with the study described here?
Answer
-
There may have been individual differences in mood at the beginning of the study.
-
There was only one independent variable.
-
The dependent variables were measured on different scales.
-
All of the above.
Question 59
Question
A researcher wanted to examine the effects of a new antidepressant drug. She recruited 60 clinically depressed participants and randomly allocated them to three conditions: No dose (placebo), low dose and medium dose of the drug. She administered the drugs to participants for one month, then measured their mood levels by asking them to complete a self-report measure. However, she decided that mood should not just be measured by self-report, so she also asked the participants' psychiatrists to give their ratings of each person's mood. All mood ratings were measured on a 1-50 scale, with 1 indicating the lowest possible mood and 50 indicating the highest possible mood. The SPSS output from the data analysis is shown below.
Which statistic test gives the largest effect size for the effect of the drug?
Answer
-
Pillai's Trace.
-
Wilks' Lambda.
-
Roy's Largest Root.
-
They are all equal.
Question 60
Question
Poor research practices such as trying out several statistical analyses to get a significant results may increase the likelihood of ___________.
Answer
-
a Type 1 error occurring
-
a Type 2 error occurring
-
incorrectly accepting the null hypothesis
-
having insufficient statistical power
Question 61
Question
A Type 1 error means ___________.
Answer
-
we have rejected the null hypothesis when it is, in fact, true
-
we have rejected the alternative hypothesis when it is, in fact, true
-
we have accepted the null hypothesis when it is, in fact, false
-
None of the above.
Question 62
Question
The tendency for statistically significant findings to be published over nonsignificant findings is known as _________.
Answer
-
sampling error
-
type 2 error
-
publication bias
-
meta-analysis
Question 63
Question
Statistical power can be increased by _________.
Answer
-
including more independent variables
-
decreasing the sample size
-
increasing the sample size
-
including more dependent variables
Question 64
Question
When power = 0.56, what are you chances of finding an effect (if one exists)?
Answer
-
44%
-
5%
-
56%
-
95%
Question 65
Question
The power of a statistical test can be defined as __________.
Answer
-
the probability of not making a type 2 error
-
the probability of not making type 1 error
-
the probability of rejecting the null hypothesis when it is actually true
-
All of the above.
Question 66
Question
An effect size shows ___________.
Answer
-
whether to reject the Null Hypothesis
-
the magnitude of a result in a study
-
the likelihood of committing a type I error
-
whether a result is statistically significant
Question 67
Question
Prospective power analysis involves calculating ________.
Answer
-
the level of power which would be necessary to give a particular effect size
-
the effect size which would be given by a particular sample size
-
the sample size which would be necessary for a given effect size to give certain level of power
-
the level of alpha which would be given by a particular level of power for a given sample size
Question 68
Question
The combination of effect sizes from more than one study is known as _________.
Answer
-
power analysis
-
discriminatory analysis
-
meta-analysis
-
multivariate analysis
Question 69
Question
Unlike p-values, effect sizes are _________.
Answer
-
calculated from tables of critical values
-
limited to a range from 0 to 1
-
not influenced by sample size
-
very sensitive to outliers
Want to create your own Quizzes for free with GoConqr? Learn more.