4355480
Description
Flashcards by Patrick Wagner, updated more than 1 year ago
|
|
Created by Patrick Wagner
almost 10 years ago
|
|
| Question | Answer |
| Nennen Sie die 5 Phasen des Forschungsablaufes! | - Problemstellung - Untersuchungsplanung, - Versuchsdurchführung, - Statistische Analyse, - Ergebnisinterpretation und diskussion |
| Beschreiben Sie die Aufgaben der Statistik! | - Datenreduktion und Datenbeschreibung - Feststellen und Beschreiben von Zusammenhängen zwischen Parametern - Feststellen von Unterschieden zwischen zwei Grundgesamtheiten durch Stichprobenvergleich - Erstellen von Prognosen |
| Definieren Sie das Ziel und die Methoden der deskriptiven Statistik! | -Deskriptive Statistik: Reduktion von Informationen d.h. Übersichtlich und anschaulich aufbreiten -Methoden: Zusammenfassung in Tabellenform, Veranschaulichung durch Grafiken, Berechnung des arithmetischen Mittels |
| Beschreiben Sie den schematischen Ablauf empirischer Forschung! | - Problemstellung - Theorie, vorliegende Forschungsbefunde - Fragestellung - Auswahl von Konstrukten/Variablen - Formullierung von Hypothesen - Operationalisierung - Auswahl geeigneter Forschungsinstrumente - Datenerhebung - Quant. Qual. Datenauswertung - Interpretation der Ergebnisse |
| Definieren Sie Sie Urliste | - Gibt alle Merkmalsausprägungen eines Merkmals wieder - Ist frei von Text und zusätzlichen Erklärungen - Unübersichtlich - Gibt keinen Einblick in die Struktur des Merkmals und in die Verteilung der Merkmalsausprägungen |
| Definieren Sie die primäre Tafel | - Ist nach bestimmten Kriterien (Größe, Gewicht, Punktzahl) geordnet - Größere Übersichtlichkeit gegenüber Urliste |
| Nennen sie die drei Maße zur Beschreibung von Verteilungen | - Lokationsmaße (beschreiben die Verteilung bzgl. Ihres Schwerpunktes) - Streuungsmaße (Streuung der Daten um einen zentralen Wert) - Formmaße (Anpassung der Verteilung an die Normalverteilung) |
| Welche Lokationsmaße kennen Sie und in wie weit unterscheiden Sie sich? | - Arithmetisches Mittel -definiert als summe aller einzelwerte dividiert durch deren Anzahl • metrisch skalierte Daten • symmetrische Verteilung • Rückschlüsse auf Grundgesamtheit Median - Zentralwert. Wert, der eine Reihe von geordneten Beobachtungen in zwei gleiche Teile zerlegt • ordinalskalierte Daten • wenn man exakten Mittelpunkt der Verteilung kennen möchte • wenn Extremwerte das arithmetische Mittel stark verzerren • wenn eine deutliche Abweichung von der Normalverteilung vorliegt Modus = Höchste Häufigkeit • nominalskalierte Daten • bei mehrgipfligen Verteilungen • wenn grober Überblick über Verteilung gewünscht wird • wenn der häufigste Wert erfragt wird |
| Definieren Sie Interquartilbereich und Quartilabstand und erläutern Sie diese | - Der Quartilabstand gibt die Größe der Spannweite (Range) an, wie weit der meiste Teil der Daten um einen zentralen Wert herum verteilt ist. - Interquartilbereich: IQ = Q3 – Q1 - Perzentile P1-100, Dezile P10-100, Quartile P25,50,75,100 |
| Definiere die Spannweite (Range | - für metrische Skalen - gibt die Differenz zwischen dem größten und dem kleinsten Messwert an - sehr anfällig gegen einzelne Ausreißer - R= x max - x min |
| Erläutern Sie die Varianz und die Standardabweichung. | - Standardabweichung ist die Wurzel aus der Varianz. - Die Varianz entspricht der Summe der mittleren quadrierten Abweichung der Messwerte von ihrem Mittelwert, dividiert durch die Anzahl der Freiheitsgrade. Diese sind die um 1 verringerte Anzahl aller Messwerte - Die Varianz ermöglicht keine deskriptive Interpretationsmöglichkeit, deshalb zieht man aus der Varianz die Wurzel und erhält die Standardabweichung. -Die Standardabweichung ist das Maß, das angibt wie stark die einzelnen Merkmalswerte im Durchschnitt vom arithmetischen Mittel abweichen. |
| Wie lautet die Formel für den Variationskoeffizienten und wie ist diese zu interpretieren? | - Macht Streuungen aus verschiedenen Stichproben vergleichbar - V = (Standardabweichung durch Mittelwert) * 100 - Der Variationskoeffizient bringt zum Ausdruck, wie vie Prozent des arithmetischen Mittels die Standardabweichung ausmacht |
| Erläutern sie die Symmetrie/Schiefe und Exzess(Kurtosis) | -überprüft die Anpassung einer Kurve an die Normalverteilung - lässt sich auch durch Lage der Lokationsmaße zueinander charakterisieren -rechtssteile Verteilung -> AM-MD-MO linkssteile Verteilung-> MO-MD-AM -symmetrische Verteilung-> AM-MO-MD -Exzess beschreibt wie flach oder steil eine Verteilung im Vgl.zu einer Normalvert. Ist - Wert um Null= etwa normal verteilt; Wert größer als Null= Verteilung ist spitzer; Wert kleiner als Null= Verteilung flacher als Normalverteilung |
| Erläutern Sie die Induktive Methode | - Das schließen von Einzelfällen auf allgemeingültige Sätze - Problem: So lange nicht jeder Einzelsatz überprüft ist, muss man damit rechnen, dass es Einzelfälle gibt, bei denen sich der Satz nicht bestätigt |
| Erläutern Sie die Deduktive Methode sowie die regressive! | - Aus allgemeinen Gesetzmäßigkeiten lassen sich Einzelvorgänge ableiten (deduzieren) - Bei Nichtzutreffen ist die Gesetzmäßigkeit als All-Satz widerlegt (falsifiziert) -regressiv: Wirkung wird festgestellt, Ursache wird gesucht |
| Definieren Sie den Begriff Experiment. | - systematischer Beobachtungsvorgang. Gleichzeitig systematische Ausschaltung von Störeinflüssen. Kontrolle -> Forscher stellt aktiv die Bedingungen (Wenn-Aussagen) her und beobachtet die Effekte (Dann-Aussagen) |
| Nennen Sie Hauptmerkmale eines Experiments. | - Aktive Manipulation der WENN-Bedingungen statt passive Beobachtung - Prinzip der Willkürlichkeit (planmäßig) - Prinzip der Variierbarkeit (veränderbar) - Prinzip der Wiederholbarkeit (replizierbar) - Kontrolle von Störvariablen |
| Skizzieren Sie die Interne Validität und die Externe Validität | - Ein Versuch ist intern Valide, wenn Veränderungen der AV eindeutig auf den Einfluss der UV zurückzuführen sind - Annahme: Manipulationen der UV bedingen Veränderungen der AV - Externe Validität -> Generalisierbarkeit der Ergebnisse |
| Stellen Sie die Vor- und Nachteile von Feld- und Laborforschung heraus! | Vorteile Labor-> Situtation und Verhalten leicht manipulierbar -> Störvariablen kontrollierbarer und Schaffung optimaler Bedingungen Nachteil Labor-> Umgebung ungewohnt und unnatürlich -> Personene wissen, dass sie untersucht werden und verändern so ihr Verhalten Vorteile FF-> Natürliche Umgebung und Spontanes Verhalten -> Bessere Übertragbarkeit + Geringe Verfälschung durch Wissen um Studie Nachteile FF-> Störvariablen schlecht zu kontrollieren -> Manipulation von Situationen und Verhalten schwer |
| Erläutern Sie Vor- und Nachteile einer Längsschnitts- / Querschnitsstudie. | - Dieselbe Stichprobe von Individuen wird mehrmals zu verschiedenen Zeitpunkten mit demselben Messinstrument untersucht (Längsschnittstudie) -Vorteile -> Unterschiede in den Messwerten dürfen als Intraindividuelle Verändeurngen interpretiert weren (Nachteile-> Wetter, Mortalitätsrate etc.) - Zu einem bestimmten Zeitpunkt werden mehrere Stichproben mit demselben Messinstrument einmal untersucht (Querschnittstudie) Vorteile-> kurze Durchführungsdauer, N bleibt konstant Nachteile-> Generalisierung der Befunde über Zeitpunkt der Untersuchung hinaus nicht möglich |
| Erläutern Sie das MAXKONMIN-Prinzip! | - MAXimiere die Primärvarianz. Wähle Stufen der UV so, dass möglichst große Unterschieden in der AV zwischen den Gruppen entstehen, durch bspw: Wahl von extremen experimentellen Bedingungen - KONtrolliere die Sekundärvarianz. Bekannte Störfaktoren sollen in allen Gruppen gleich wirken(interne Validität) , durch bspw: statistische&experimentelle Kontrolle, Eliminierung&Konstanth. - MINimiere die Fehlervarianz. Vermeide Fehler auf Seiten der Versuchssituation durch bspw: Randomisierung oder Blockbildung |
| Erläutern sie Parallelisierung! | - Umwandlung möglicher Störvariablen, die einen Einfluss auf die AV haben, in UV - Anwendung bei kleinen Stichproben |
| Definieren Sie das Ziel und die Methoden der schließenden Statistik (Inferenzstatistik)! | - Datenanalyse und -bewertung statt Beschreibung - Ziel: Verlässliche Aussagen über Sachverhalte und Personengruppen zu machen, ohne diese in vollem Umfang untersucht zu haben. (induktiver Schluss --> vom Teil auf das Ganze) - Durch: Schätzen von Pramatern, Bestimmung von Konfidenzintervallen, Testen von Hypothesen (Unterschiede/Zusammenhänge aufdecken) |
| Was macht die Wahrscheinlichkeitsrechnung? | - Schließt vom Stichprobenbefund auf die Grundgesamtheit - Ausgangspunkt: Zufälliges Ereignis das beliebig oft wiederholt werden kann - Über die Folge zufälliger Ereignisse kann man Erwartungen formullieren. |
| Erläutere den Bernoulliprozess und die Binomialverteilung! | - Abfolge von Ereignissen die zufällig, alternativ, unabhängig voneinander oder mit konstanter Wahrscheinlichkeit auftreten - bei n Versuchen, kann das Ereignis A x-mal auftreten -> Binomialverteilung ist die Wahrscheinlichkeitsfunktion(fx) für Häufigkeiten des Auftretens von A bei n Bernoulli-Versuchen - je größer die Anzahl der Versuche n, desto symmetrischer wird die Bino.verteilung |
| Nennen Sie die Merkmale einer Normalverteilung | 1. Die Verteilung hat einen glockenförmigen Verlauf. 2. Die Verteilung ist symmetrisch 3. Modalwert, Median und arithmetisches Mittel fallen zusammen. 4. Die Verteilung nähert sich asymptotisch der x-Achse. 5. Zwischen den zu den Wendepunkten gehörenden x-Werten befindet sich ca. 2/3 der Gesamtfläche |
| Erklären sie die Z-Transformation und die Standardnormalverteilung | - Mittel zur Standardisierung - Von jedem Messwert Xi wird der Mittelwert der Verteilung (also aller Werte) subtrahiert und der resultierende Wert wird jeweils durch die Standardabweichung dividiert. Zi = Xi – X[quer]) durch S - Es resultiert eine standardisierte Verteilung Zi mit Mw. = 0 und st.abw. s=s² = 1 |
| Was für eine Bedeutsamkeit hat die Normalverteilung? | - NV als empirische Verteilung und Verteilungsmodell für statistische Kennwerte - NV als mathematische Basisverteilung und in der statistischen Fehlertheorie |
| Erklären sie das Schätzen von Parametern | - auf Basis von Stichprobenkennwerten taugliche Näherungswerte für die entsprechenden Populationsparameter zu berechnen - Auswahl der Stichprobe hat entscheid. Einfluss auf Generalisierbarkeit der Befunde |
| Wie lautet die Formel für den Standardfehler SE und wie ist diese zu interpretieren? | - Mit Hilfe des Stichprobenfehlers des arithmetischen Mittels können Konfidenzintervalle berechnet und Hypothesen geprüft werden - SE = Population geteilt durch die Wurzel aus der Stichprobe (n) -Berechnung des Standardfehlers (SE) zum Vergleich von Stichproben und Populationsmittelwerten |
| Was ist ein Konfidenzintevall (Vertrauensintervall)? | - Bereich des Merkmals indem sich 95-99% aller möglichen Populationsparameter befinden, die den Stichprobenwert erzeugt haben können - +- 1,96 (95% wahrschk.) mal den SE = Intervall (70,37; 73,43) |
| Erklären Sie den Statistischen Test sowie den Begriff der "Signifikanz" und erläutern Sie in dem Zusammenhang das Signifikanzniveau! | - ein Verfahren, das aufgrund von Stichprobenergebnissen, darüber entscheidet, ob eine statistische Hypothese angenommen oder verworfen wird - Signifikanz= Bedeutsamkeit eines statistischen Versuchsergebnisses, das die Entscheidung über eine Hypothese ermöglich - das Signifikanzniveau eines Tests ist die Wahrscheinlichkeit, mit der die Nullhypothese abgelehnt wird, obwohl diese in Wahrheit zutrifft. |
| Nennen Sie die einzelnen Schritte eines Hypothesentests. | 1. Formulierung einer empirisch überprüfbaren Hypothese 2. Konstruieren einer Entscheidungsregel 3. Ziehen einer Stichprobe 4. Berechnen der Prüfvariablen 5. Anwendung der Entscheidungsregel Der Annahme- Ablehnungsbereich einer Hypothese ist durch so genannte Rückweisungspunkte begrenzt (kritische Werte) Diese müssen bei jedem Test berechnet werden. 6. Ableitung einer Entscheidung (H0 wurd verworfen oder angenommen) (Alpha Fehler -> H0 Ablehnung, obwohl sie in Wirklichkeit zutrifft) (Beta Fehler -> H1 Annahme, obwohl sie in Wirklichkeit falsch ist) |
| Definiere die Irrtumswahrscheinlichkeit(p) | - Wahrscheinlichkeit, dass das gefundene Ergebnis oder extremere Ergebnisse bei Gültigkeit von H0 eintreten |
| Nenne die Arten der Zusammenhänge zwischen X und Y! | - Hohe Werte von X , entsprechen hohen von Y und umgekehrt = Pos. Zsmenhang - Hohe Werte von X entsprechen niedrigen von Y und umgekehrt = Neg. Zsmenhang - Hohe Werte von X sind manchmal mit hohen, mittleren oder niedrigen Werten Y gepaart = kein Zusammenhang - r=0, 20-40 , 40-70, 70-90, r>90= Sehr starker Zsh., r=1 perfekter Zusammenhang |
| Benenne die 4 Fälle des Ursache-Wirkungs-Zusammenhangs. | - einseitige Steuerung: X bewirkt Y - Gegenseitige Steuerung: X wirkt auf Y, und Y wirkt auf X zurück - Drittseitige Steuerung: X&Y hängen gleichermaßen von einer dritten Variable Z ab - Komplexe Steuerung: Das Bedingungsgefüge bewirkt Y |
| Was ist eine Scheinkorrelation? Zeigen Sie anhand eines Beispiels! | - Kovariation zweier Variablen kann auf kausale Beziehung der beiden Variablen oder auf Beeinflussung durch eine/mehrere Drittvariablen zurückgehen - Bsp.: Korrelation zwischen Schuhgröße und Lesbarkeit der Handschrift |
| Was ist eine Partialkorrelation? | - gibt den Zusammenhang zweier Variablen an, aus dem der lineare Einfluss einer dritten Variable eliminiert wurde |
| Beschreibe ein Schaubild zu Zusammenhangsmaße und Skalenniveau | - Nominal/Nominal = Vierfelderkoeffizient / Kontingenzkoeffizient - Nominal/Intervall = Punktbiseraler Koeffizient - Ordinal/Ordinal = Spearman Rankkoeffizient; Interv./Int.= Produkt-Mom-Korr.k.efz. |
| Erläutere den Phi-Koeffizienten sowie den Kontingenzkoeffizienten | - nur für 4-Felder-Tafel und wenn beide Variablen nominalskaliert sind -> √ x2/n - Kontingenzkoe. C bei mehr als zwei Ausprägungen der nominalskalierten Merkmale - für verschieden große Tabellen ist er nicht vergleichbar, dann Cramer-Koeffizient V - C&V können nur zwischen 0 und +1 variieren ( C= √x2/x2+n; V=√x2/n*(R-1)) -x2=(f count – f expected)2/ f expected -> f exp= Zeilens.*Spaltens./Gsmt.summe |
| Erkläre den Punktbiserialen Korrelationskoeffizienten! | - wenn je eine variable nominal-/ intervallskaliert ist - Bsp.: Klimmzüge und Vereinszugehörigkeit |
| Definiere den Rangkorrelationskoeffizienten nach Spearman | - beruht auf den zugeordneten Rangnummern, die vergeben werden nach Sortierung nach Größe (bei gleichen Rang-> gemittelter Rangplatz für beide) - rs= 1-(6*di2)/ n(n2-1) -> di2 = Rang yi – Rang xi, quadriert Ergebnis und addiert Alle - kritischen Wert für rs aus Tabelle-> ist er größer dann signifikanter Zusammenhang |
| Erkläre die Kovarianz | - damit lässt sich bestimmen, wie sich die relativen Positionen von gepaarten Messwerten aus zwei Variablen zueinander verhalten - kann nur hinsichtlich ihres Vorzeichens und nicht ihrer Größe interpretiert werden -> Summe (xi -xquer)(yi-yquer) / n-1 (kann maximal den Wert sx*sy annehmen) - positives Vorzeichen = überdurchs. Werte von X stärker mit überds.von Y gepaart (oder andersrum) & neg.Vorzeichen = überds. von X mit unterds. von Y gepaart |
| Erläutere den Produkt-Moment-Korrelationskoeffizienten | - X&Y intervallskaliert und Zusammenhang ist linear sowie beide sind normalverteit - Kovarianz berechnen, dann durch sx*sy= 0,8 o.ä -Signifikanz-> F.grad= n-2 -> krit. Wert ablesen; Prüfgröße V berechnen-> r*√n-2/1-r2 |
| Erkläre den Determinationskoeffizienten | - bringt zum Ausdruck, wie groß der Anteil wechselseitig erklärbarer Varianz der beiden Merkmale ist -> bsp.: r2= 0,68 = 68% Varianzanteil der einen Variable ist durch die andere determiniert - durch Erhebung einer der beiden Übungen kann man mit einer Genauigkeit von 68% das Ergebnis der anderen voraussagen |
| Was sind 1. parametrische und 2. nonparametrische Tests? Unterscheiden Sie! | 1. Strenge Modellvoraussetzungen bezüglich Populationsparameter - >Normalverteilung, Varianzhomogenität - Hohes Messniveau der Daten nötig (mindestens Intervallniveau) - Große Stichprobe, hohe Teststärke und hoher Aufwand nötig 2.Keine bzw. Schwache Modellvoraussetzungen - Anwendbar, wenn Beobachtungen aus unterschiedlichen Populationen stammen - niedriges Messniveau der Daten reicht aus (Nominalniveau) - Schon bei kleinen Stichprobenumfänge anwendbar - Geringe Teststärke und leicht anzuwenden |
| Wie kann die Wirkung der UV bei Unterschiedshypothesen beschrieben werden? | - Zentrale Tendenz, Dispersion und Verteilungsform |
| Erläutern sie den KS-Test. | - H0-> Stichprobe stammt aus einer normal verteilten Grundgesamtheit - anwendbar auch bei kleineren Stichproben; Klassenbildung erforderlich - Berechnung der Prüfgröße V (V kleiner als kritischer Wert dann Annahme H0) - V= max Differenz von kum.Häufigkeiten und Phi von x(abgeschnittene Fläche)/n |
| Erläutere das x2Verfahren zur Prüfung auf Normalverteilung | - H0-> Stichprobe ist normal verteilt - Voraussetzung: Hinreichend großer Stichprobenumfang Stichprobe wird in Klassen aufgeteilt - Summe f count- fexpected/ f expected - Prüfung der Normalverteilung auch auf Basis der Schiefe(0) und Exzess(0) möglich |
| Beschreiben Sie den McNemar-Test. | - Untersucht, ob sich etwas verändert oder nicht (abhängige Stichprobe) - Das McNemar – chi² berücksichtigt nur diejendigen Fälle, bei denen eine Veränderung eingetreten ist-> (b-c)2/b+c ; df=1 |
| Erläutern Sie den U-Test nach Whitney. | - Für zwei unabhängige Stichproben - Untersuchung derselben Variable X in zwei verschiedenen Stichproben (Gruppen) - H0: X hat in beiden Stichproben die gleiche Verteilung. (U>U krit.W., Annahme H0) - Statt der Messwerte werden ihre Rangplätze verwendet - Anwendung bei metrischen Merkmalen mit n kleiner als 10 oder wenn bei mindestens einer Stichprobe keine Normalverteilung vorliegt |
| Erläutern Sie den Wilcoxon-Test | - Für abhängige Stichproben. (Test für Paardifferenzen) - Untersuchung derselben Stichprobe mit zwei Messwerten je Versuchperson (Beobachtungspaare) - Anwendung wenn die Voraussetzungen für den t-Test nicht erfüllt werden können - Verwendung der Rangplätze |
| Erkläre den t-Test für unabhängige Stichproben. | - Untersuchung der selben Variablen X in zwei Stichproben - Gehören die beiden Mittelwerte zur gleichen Grundgesamtheit? Berechnung von t - Anwendungsvoraussetzung: Intervallskalierte Daten, Normalverteilung der xi in beiden Stichproben und homogene/gleiche Streuung s bzw. s2 - wenn t< t kritischer Wert, dann Annahme von H0; fd= n1+n2 - 2 |
| Erläutern Sie den F-Test. | - Vergleich von Stichprobenvarianzen durch Überprüfung der Varianzhomogenität - Weichen die Stichprobenvari. zufällig voneinander ab oder sind sie sign. verschie.? - größere Varianz durch kleinere Varianz (F-Verteilung hat 2 Parameter f1 und f2) - F< F krit. Wert, Annahme von H0 -> Varianzen sind homogen; f1/2= n1-1 und n2-1 |
| Erläutern Sie den t-Test bei abhängigen Stichproben | - Untersuchung derselben Stichprobe mit zwei Messwerten je Versuchsperson - Voraussetzung: Intervallskallierte Daten, Normalverteilt - Betrachtung der Differenzen zwischen Messwerten: Mittelwert des 1. Zeitpunktes und Mittelwert des 2. Zeitpunktes - Unterscheidet sich d quer signifikant von 0? Berechnung der Prüfgröße t; fd= n-1 |
| Ablauf: | 1. Formulierung einer empirisch überprüfbaren Hypothese 2. Konstruktion einer Entscheidungsregel 3. Ziehen einer Stichprobe 4. Berechnen der Prüfvariablen 5. Anwendung der Entscheidungsregel 6. Ableiten einer Entscheidung |
| Womit befasst sich die Regressionsanalyse? | - mit der Untersuchung und Quantifizierung von Abhängigkeiten zwischen metrisch skalierten Variablen -> wesentliche Aufgabe ist es, eine lineare Funktion zu finden, die die Abhängigkeit der AV von einer oder mehreren UV quantifiziert - Sie schätzt den Wert einer Variablen aufgrund der Kenntnis des Wertes einer anderen Variablen desselben Elements - Art des Zusammenhangs kann genauer ermittelt werden |
| Nenne die Unterschiede zwischen der Regressions- und der Varianzanalyse. | - UV bei Var.a. besitzen kategoriale Ausprägungen, bei Reg.a. sind sie intervallskaliert - mittels Reg.a. sollen Ursachen-Wirkungszusammenhänge erklärt werden |
| Wie läuft eine Berechnung der Regressionsgeraden ab? | - Summe der Abweichungen jedes Punktes zu G soll Minimum werden - Eine Regressionslinie ist eine Gerade G, für welche die Summe der Quadrate der Abweichungen aller Punkte ein Minimum bildet - durch Methode der kleinsten Quadratsumme für y=a1+b1x und für x= a2+b2y - Parameter a und b sind also zu bestimmen a1= y quer - b1 * x quer und b1= (xi – x quer)*(yi-y quer) / (xi – x quer)2 |
| Erkläre die multiple lineare Regression. | - das Kriterium wird durch mehrere Prädiktoren vorhergesagt (Y=b1*x1+b2*x2...+a) - es gibt einen spezifischen Einfluss des ersten Prädiktors aufs Kriterium, einen des zweiten und einen gemeinsamen Einfluss der Prädiktoren auf das Kriterium - spezifischen Varianzanteil eines Prädiktors bestimmen (Beta Gewicht) -> je höher der einzigartige Anteil, desto mehr Vorhersagekraft besitzt ein Prädiktor |
| Definiere das Beta-Gewicht. | - normierter Regressionskoeffizient (Maß für Stärke des Einflusses eines Prädiktors) - Vorzeichen gibt Richtung des Einflusses vor - durch die Beta-Gewichte kann eine Reihenfolge der Prädiktoren bezüglich der Stärke ihres Einflusses auf das Kriterium erstellt werden |
| Definiere die Varianzanalyse | - statistische Technik zur gemeins. Untersuchung von 2 oder mehreren Mittelwerten - wie wirken sich ein oder mehrere UVs auf ein oder mehrere AVs aus? - UV = Faktoren mit unterschiedlichen Ausprägungen -> Faktorenstufen/Gruppen - Skalenniveau der Faktoren beliebig (meist Nominal), der AV immer intervallskaliert - ein-/mehrfaktoriell, uni-/multivariat, ohne/mit Messwiederholung |
| Erläutere Generelles zur Varianzanalyse | - vergleicht Mittelwerte durch Zerlegung der Varianz in Streuung zwischen und innerhalb der Gruppen (und man hat einen Einflussfaktor mit k > 2 Ausprägungen) Varianz zwischen den Gruppen (Treatmentvarianz) relativ groß, bei gleichzeitig nicht allzu großer Varianz innerhalb der Gruppe (Fehlervarianz), so kann man davon ausgehen, dass die Gruppenzugehörigkeit einen Einfluss auf die AV hat - H0: Gruppen unterscheiden sich nicht in ihrer mittleren Maximalkraft - H1: Gruppen unterscheiden sich in ihrer mittleren Maximalkraft - der Messwert einer Person setzt sich zusammen aus Populationsmittelwert + Gruppeneffekt + Fehlerwert - Ziel: testen, ob Varianz zwischen signifikant größer ist als die Varianz innerhalb ja, dann besteht ein Unterschied zwischen den Mittelw. (auf UV zurückzuführen) nein, dann besteht kein Mittelwertsunterschied zwischen den Gruppen |
| Erkläre den Vorgang der ANOVA an einem Beispiel | - Voraussetzungen: Normalverteilung (der Faktorstufen), Varianzhomogenität(F-test) und Intervallskalenniveau der AV…(trifft eins nicht zu -> Kruskal-Wallis-Test) -H0:Alle Mittelwerte entstammen derselben Population -H1: mindestens ein Mittelwert entstammt einer unterschiedlichen Population Beispiel: Drei Waschmittel (Faktorenstufen), mit jedem Waschmittel wurden fünf Mützen gewaschen. Frage: Beeinflussen die Waschmittel die Dehnung(AV) der Mützen? H0: Die Waschmittel unterscheiden sich nicht in ihrem Einfluss auf die Dehnung der Mützen H1: Die Waschmittel unterscheiden sich in ihrem Einfluss auf die Dehnung der Mützen |
| Erkläre die Alpha-Fehlerinflation | - bei jedem Einzelvergleich besteht die Gefahr des Alpha-Fehlers - bei mehreren Einzelvergleichen = kumulierte Gefahr = Alpha-Fehlerinflation - 5% Irrt.w.s wird schnell sehr gering (bei mehr Einzelvergleichen) - Alpha-Fehlerinflation = 1-(1-Alpha)k |
| Erläutere den Post-hoc-Test | - um rauszufinden welche Mittelwerte sich im einzelnen unterscheiden (Ergebnis der ANOVA ist signifikant, aber was unterscheidet sich genau?) - mögliche Anzahl paarweiser Vergleiche bei k Gruppen = k*(k-1) / 2 - Korrekturtest durch Bonferroni-Korrektur, um Problem der Alpha-Fehlerinflation in den Griff zu bekommen (bei Varianzanalyse automatisch bei SPSS) - Alphaadj= Alpha/ k (Anzahl der Tests) 5/ 3= 1,66 = neues Alphaniveau - drei Vergleiche mittels Bonferroni-Korrektur möglich-> 1&2; 1&3; 2&3 |
| Erkläre in diesem Zusammenhang die Effektstärken | - geben Auskunft über die praktische Bedeutsamkeit statistischer Signifikanz - sind die Leistungsunterschiede zwischen den Leistungsniveaus klein,mittel,groß? - für jeden Signifikanztest werden eigene Effektstärken berechnet - eta2 >0,01= kleiner Effekt; > 0,059= mittlerer Effekt; > 0,138= großer Effekt |
| Definieren Sie den Begriff "Theorie". | - Ein geordnetes System von Aussagen, das hilft, die Wirklichkeit und auf sie bezogene Forschungsprobleme zu strukturieren. |
| Benennen Sie Bestandteile einer Theorie. | - Definitionen der Begriffe - Postulate (Annahmen über Beziehungen bedeutsamer Variablen. Beruht auf persönlichen Beobachtungen - Deduktion |
| Definieren Sie die unabhängig Variable (UV)! | - Eine vom Versuchsleiter direkt oder indirekt manipulierbare Variable durch Manipulation oder Selektion - Reizvariable |
| Nennen Sie Beispiele für die UV! | - Alter, Geschlecht, vorgegebene Zeit |
| Definieren Sie die abhängige Variable (AV)! | - Ereignis das die Manipulation der UV beobachtet - Versuchsleiter hat keinen direkten Einfluss - Reaktionsvariable |
| Nennen Sie Beispiele für die AV! | - Einstellungen, Test- und Wettkampfleistungen, z.B. Sprungweite, 100m-Zeit |
| Erläutern Sie die Beziehung von UV und AV! | - Abstufungen der UV verändern systematisch die AV. - UV ist die Ursache, AV die Wirkung. - Aus der Veränderung der UV folgt die Veränderung der AV. - Funktionale Beziehung von UV und AV: AV = f(UV) |
| Erläutern Sie "Wissenschaftliche Hypothesen". | - Sind Annahmen über reale Sachverhalte in Form von Konditionalsätzen - Sie weisen über den Einzelfall hinaus und sind durch Erfahrungsdaten falsifizierbar |
| Erläutern Sie manifeste und latente Variable! | - Manifeste Variable (direkt beobachtbar; z.B. Anzahl gelöster Testaufgaben) - Latente Variable (nicht-beobachtbar, liegt einer manifesten Variable als hypothetisches Konstrukt zugrunde; z.B. Intelligenz) wird über Umwege versucht zu erfassen |
| Erläutern Sie die Begriffe Verifizierbarkeit und Falsifizierbarkeit! | - Veritas (Wahrheit) Facere (Machen)Vermuteter Sachverhalt wird wahr gemacht - Falisificare (als falsch erkennen) Widerlegung. Nachweis der Ungültigkeit einer Aussage, Hypothese |
| Definieren Sie Moderator-/Kontroll- und Stövariable und nennen Sie je ein Beispiel und begründen Sie. | - Moderatorvariable verändert den Einfluss einer UV auf die AV (Straßenlärm) - Wenn Ausprägung der Moderatorvariable vorsorglich erhoben Kontrollvariable - Bei Nichtbeachtung der Moderatorvariable Störvariable |
| Erklären Sie den Unterschied zwischen einer gerichteten und einer ungerichteten Hypothese! | - Gerichtete Hypothese: Richtung des Unterschieds wird postuliert - Ungerichtete Hypothese: Irgendein Unterschied wird postuliert |
| Erklären Sie den Zusammenhang zwischen Messwert und Messfehler! | wahrer Wert = individuelle Merkmalsausprägung Messfehler = Ungenauigkeit der Messinstrumente Ziel methodischer Maßnahmen: Messfehler = 0 |
| Erklären Sie den Begriff Messfehler! | - Messwert = wahrer Wert + Messfehler - Messfehler = Ungenauigkeit der Messinstrumente |
| Erklären Sie die Begriffe Objektivität und Reliabilität! | - Reliabilität: Zuverlässigkeit (formale Genauigkeit) einer Messung - Objektivität: Antwort bzw. Messwerte sind unabhängig vom Prüfer - Validität: Eignung, Gültigkeit Es gibt die drei Gütekriterien die aufeinander aufbauen. Ohne Objektivität keine Reliabilität. Ohne Reliabilität keine Validität |
| Welche Arten von Wissenschaftlichen Hypothesen kennen Sie? | Nullhypothese: Drückt inhaltlich aus, dass Unterschiede, Zusammenhänge, Veränderungen oder besondere Effekte in der interessierenden Population nicht und/oder nicht in die erwartete Richtung auftreten Alternativhypothese: Behauptet, dass in der Population ein Effekt vorliegt, dass sich Populationsparameter unterscheiden. - Zusammenhangshypothesen: Zusammenhang zweier oder mehrerer Variablen - Zusammenhangsmaße nach Skalenniveau - Der Zusammenhang zwischen Merkmalen wird als Korrelation bezeichnet |
| Nennen Sie die Kriterien von Hypothesen. | Hypothesen sind allgemeingültige, über den Einzelfall oder ein singuläres Ereignis hinausgehende Aussagen (Behauptungen) -> Allsatz • Die Aussage enthält mindestens zwei semantisch gehaltvolle Begriffe und ist widerspruchsfrei. Wenn, dann --> Konditionalsätze • Die empir. Geltungsbedingungen sind implizit oder explizit im Einzelnen aufgezählt • Die Begriffe sind auf Wirklichkeitsphänomene hin operationalisierbar • Die Aussage ist falsifizierbar, d.h. es müssen Ereignisse denkbar sein, die dem Konditionalsatz widersprechen. |
| Was versteht man unter Operationalisierung? | - Beobachtbarmachung theoretischer Variablen und deren Zusammenhänge - Beinhaltet zwei Aspekte: - Festlegung der Bedingung, - Erfassen der Ausprägung |
| Nennen Sie die 5 Axiome der klassischen Testtheorie! | - Testergebnis = wahrer Wert + Messfehler - Mittelwert mehrerer unabhän. Messungen repräsentiert den wahren Wertebereich - Wahrer Wert und Fehlerwert sund unkorreliert - Der Fehlerwert ist nicht korreliert mit anderen Persönlichkeitsmerkmalen - Fehlerwerte sind unkorreliert |
| Definieren Sie Grundgesamtheit und Stichprobe. | - Alle potentiell untersuchbaren Einheiten, die ein gemeinsames Merkmal aufweisen - Teilmenge aller Untersuchungseinheiten, die die relevanten Eigenschaften der Grundgesamtheit möglichst gut abbildet - Je besser die Stichprobe die Population repräsentiert, desto präziser sind die Aussagen über die Grundgesamtheit - Je größer die Stichprobe, desto präziser sind die Aussagen über Grundgesamtheit |
| Welche Arten von Variablen kennen Sie? | - Unabhängige Variablen • Stetige Variablen - Abhängige Variablen • Kontinuierliche Variablen - Moderierende Variablen • Manifeste Variablen - Kontrollvariablen • Latente Variablen - Störvariablen |
| Was ist eine Variable? | - Bezeichnung für Merkmale die in mindestens 2 Ausprägungen auftreten können |
| Nennen Sie Haupt- und Nebengütekriterien eines Tests. | - Reliabilität - Validität - Objektivität - Testfairness |
| Nennen und beschreiben Sie die Hauptarten der Validität. | - Ein Versuch ist intern Valide, wenn Veränderungen der AV eindeutig auf die Variation der UV zurückzuführen ist - Annahme: Manipulationen der UV bedingen Veränderungen der AV - Übertragbarkeit der Ergebnisse auf Nicht-Stichprobe (General.s.b.k. der Ergebnisse) - Interne Validität ist die notwendige, jedoch nicht die hinreichende Bedingung für eine externe Validität |
| Was ist ein (theoretisches) Konstrukt? | - Ein nicht unmittelbar operational fassbarer Begriff der sich auf nicht direkt beobachtbare Eigenschaften bezieht (Intelligenz) |
| Was sind die Kriterien bei einer Stichprobenkonstruktion? | Ziel der Untersuchung • Verallgemeinerung, Generalisierung der Ergebnisse • Vollerhebung vs. Teilerhebung • Grundgesamtheit (Population, Universum) vs. Stichprobe (sample) • Repräsentativität einer Stichprobe • Randomisierung, Parallelisierung • Stichprobengröße vs. Stichprobenfehler • Erstellen einer Vergleichs-/Kontrollgruppe mit den gleichen Vpn-Merkmalen |
| Erläutern Sie empirisches und numerisches Relativ! | - Der Gegenstandsbereich der Objekte (Ereignisse), die gemessen und erfasst werden, bezeichnen wir als empirisches Realtiv, die zugeordneten Zahlenwerte als numerisches Relativ. |
| Erläutern Sie das Repräsentationsproblem (Skalierungs-, Eindeutigkeits-, Bedeutsamkeitsproblem)! | Repräsentationsproblem - Ist die Eigenschaft überhaupt messbar? Das Eindeutigkeitsproblem Wenn die Eigenschaft messbar ist (Repräsentationsproblem), Was kann man mit den Zahlen machen? Es lassen sich verschiedene Skalentypen bzw. Skalenniveaus hinsichtlich ihrer Eindeutigkeit unterscheiden. • Nominalskalen: eineindeutige Transformationen • Ordinalskalen: monotone Transformationen • Intervallskalen: positiv lineare Transformationen (y = ax + b) • Verhältnisskalen: positive Verhältnistransformationen (y = ax mit a > 0) Bedeutsamkeitsproblem Welche mathematischen Manipulationen innerhalb des numerischen Relativs sind zulässig, in dem das empirische Relativ abgebildet wurde? Eine Aussage ist bedeutsam, wenn sich ihr Wahrheitswert bei einer zulässigen Transformation der Werte nicht ändert. |
| Erläutern Sie absolute und relative Häufigkeit! | Die absolute Häufigkeit, mit der die Ausprägung xi auftritt, wird als f(xi) (englisch: frequencies) bezeichnet. Für viele Analysezwecke sind relative Häufigkeiten, bezeichnet mit p(xi), besser geeignet als absolute (z.B. bei Vergleichen verschiedener Gruppen). Die Relativierung erfolgt auf die Gesamtzahl der Häufigkeiten p(x)i = f(xi) / n Relative Häufigkeiten werden gewöhnlich in Prozentwerten angegeben. p(x)i = f(xi) / n ● 100 [%] |
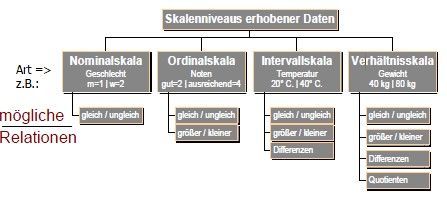
| Welche Skalenniveaus gibt es? Nennen Sie je 3 Beispiele! | Nominalskalenniveau Ordinalskalenniveau (Objekte mit größten Merkmalsausprägung erhält größte Zahl) Intervallskalenniveau ( Spiegeln Rangreihe und Größe der Merkmalsunterschiede) Verhältnisskala (Ordnet den Objekten des empirischen Relativs Zahlen zu, sodass das Verhältnis zwischen zwei Zahlen dem Verhältnis der Merkmalsausprägung entspricht |
| Grenzen Sie die qualitativen Untersuchungsansätze von den quantitativen ab! | |
| Skalenniveaus |
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.