17101273
| Question | Answer |
| Descriptive Question | Passed tense The question asked for explanation of what happened. e.g. 1. Which sets of customers are most likely in their buying patterns? 2. What factors are most important in determining customer similarity? |
| Predictive Question | Future tense The question asked for what is going to happen. e.g. 1. How much worldwide demand will there be for crude oil next year? 2. What will worldpay's stock price be in five years? |
| Prescriptive Question | What action would be best? e.g. what strategy can an airline use to get passengers to their destinations quickly before, during and after a big snow storm? |
| Classifier | The classifier that is father from making mistakes (a.k.a misclassification) |
| Soft Classifier | Used when there is no way avoid making mistakes. One that gives as good a separation as possible. |
| Cost of Misclassification | The more costly one type of bad decision is, the more we want to move the line away from it. |
| Vertical | From top to bottom Because there is no left to right line in V |
| Horizontal | From left to right People always say what a beautiful horizon, which is very harmony. |
| Structured Data | The data that can be stored structurally. Quantitative Data Categorical Data |
| Unstructured Data | No structure. e.g. written text |
| Data Point | all the information about one observation. |
| Time series data | The same thing is measured at same-period time intervals |
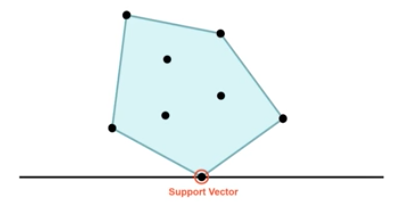
| Support Vector Machines (SVM) | For Classification Model |
| Support Vector Machines (SVM) Soft Classifier | The bigger the lambda is, the more important a large margin outweighs avoiding mistakes and misclassification. |
| Support Vector Machines Error Measurement | Measure classification error Also for the Hard Separator (Make no Mistake) |
| Support Vector Machines Why the name? | |
| Add Cost to the SVM | |
| Why scale data in SVM | As the coefficient values of different variables might be different by multiple magnitude. e.f. # of people and Annual Income$ |
| Eliminate classifiers in SVM | Near-Zero coefficients are probably not relevant for classification. |
| Support Vector Machine | SVM does not have to straight line. One model can use multiple SVM with different multipliers. The bigger the multiplier is, the more important to avoid classification error. |
| Scale Data | Common scaling: data between 0 and 1 Scale linearly 0 and 1 can be a and b |
| Standardization | |
| When to use Scale | Scale to a fixed range When the bounded range is important. Neural networks Batting average RGB color intensities SAT Scores |
| When to use standardization | Principal Component Analysis (PCA) Clustering |
| K-nearest Neighbor Classification KNN | For situations that there are more than two classes Pick the k closest points (like neighbors) Allow to weight attributes differently |
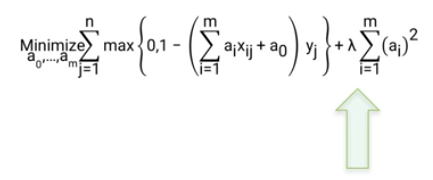{kind=link}
{kind=link}
{kind=link}
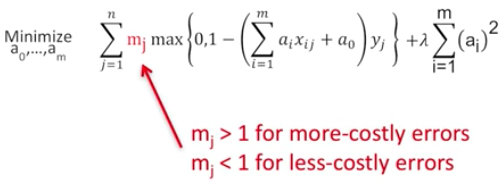{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.