4319349
Description
Mind Map by pa cao, updated more than 1 year ago
More
|
|
Created by s.rajeswari30
about 10 years ago
|
|
|
|
Copied by pa cao
about 10 years ago
|
|
Big Data
- Definition
Annotations:
- Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.
- Technologies
Annotations:
- 1.Column-oriented database 2.Schema-less databases or No SQL databases. 3. MapReduce. 4,Hadoop 5.Hive 6.PIG 7. WibiData 8. PLATFORA 9.Storage Technologies 10.SkyTree
- Hadoop
Annotations:
- Hadoop, formally called Apache Hadoop, is an Apache Software Foundationproject and open source software platform for scalable, distributed computing. Hadoop can provide fast and reliable analysis of both structured data and unstructured data. Given its capabilities to handle large data sets, it's often associated with the phrase big data.
- Example
Annotations:
- 1.ebay 2.Facebook 3.Linked in 4.yahoo
- Architecture
- Hadoop Common
Annotations:
- The common utilities that support the other Hadoop subprojects.
- Hadoop Distributed File
System
Annotations:
- A distributed file system that provides high-throughput access to application data.
- Hadoop MapReduce
Annotations:
- A software framework for distributed processing of large data sets on compute clusters.
- Hadoop YARN
Annotations:
- A framework for job scheduling and cluster resource management.
- Hadoop Common
- Scheduling
Annotations:
- By default Hadoop uses FIFO, and optional 5 scheduling priorities to schedule jobs from a work queue. In version 0.19 the job scheduler was refactored out of the JobTracker, and added the ability to use an alternate scheduler
- Capacity scheduler
Annotations:
- The capacity scheduler was developed by Yahoo. The capacity scheduler supports several features that are similar to the fair scheduler. 1.Jobs are submitted into queues. 2.Queues are allocated a fraction of the total resource capacity. 3.Free resources are allocated to queues beyond their total capacity. 4.Within a queue a job with a high level of priority has access to the queue's resources. There is no preemption once a job is running.
- Fair scheduler
Annotations:
- The fair scheduler was developed by Facebook. The goal of the fair scheduler is to provide fast response times for small jobs and QoS for production jobs.
- History
Annotations:
- Hadoop was created by Doug Cutting and Mike Cafarella in 2005. Cutting, who was working at Yahoo! at the time, named it after his son's toy elephant. It was originally developed to support distribution for the Nutch search engine project
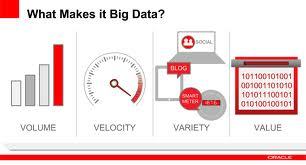
- Characteristic
Annotations:
- 1.Volume 2.Variety 3. Velocity 4.Value
- Government
Annotations:
- In 2012, the Obama administration announced the Big Data Research and Development Initiative, which explored how big data could be used to address important problems faced by the government. The initiative was composed of 84 different big data programs spread across six departments.
- Big data analysis played a large role in Barack Obama's successful 2012 re-election campaign.
- The United States Federal Government owns six of the ten most powerful supercomputers in the world.
- The Utah Data Center is a data center currently being constructed by the United States National Security Agency. When finished, the facility will be able to handle a large amount of information collected by the NSA over the Internet. The exact amount of storage space is unknown, but more recent sources claim it will be on the order of a few Exabytes
- Private
Annotations:
- eBay.com uses two data warehouses at 7.5 petabytes and 40PB as well as a 40PB Hadoop cluster for search, consumer recommendations, and merchandising. Inside eBay’s 90PB data warehouse
- Amazon.com handles millions of back-end operations every day, as well as queries from more than half a million third-party sellers. The core technology that keeps Amazon running is Linux-based and as of 2005 they had the world’s three largest Linux databases, with capacities of 7.8 TB, 18.5 TB, and 24.7 TB.
- Walmart handles more than 1 million customer transactions every hour, which is imported into databases estimated to contain more than 2.5 petabytes (2560 terabytes) of data – the equivalent of 167 times the information contained in all the books in the US Library of Congress
- Facebook handles 50 billion photos from its user base.
- FICO Falcon Credit Card Fraud Detection System protects 2.1 billion active accounts world-wide.
- The volume of business data worldwide, across all companies, doubles every 1.2 years, according to estimates.
- Windermere Real Estate uses anonymous GPS signals from nearly 100 million drivers to help new home buyers determine their typical drive times to and from work throughout various times of the day.
- Example
Annotations:
- 1.IBM 2.Hp 3.Teradata 4.Oracle 5. SAP 6.Amazon 7.Google 8. Microsoft 9.10 gen 10. cloudera
Media attachments
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.