955764
Data Warehousing and Mining
- Data Warehousing
- Increased corporate productivity.
- Competitive advantage.
- Potential for high ROI.
- Extremely high initial costs (£50k+)
- Long development time (3 years +/-)
- High demand for memory.
- High maintenance costs.
- Problems with source data (extraction, cleaning, loading).
- Increased corporate productivity.
- Building a Data Warehouse
Database (Dimensionality Modelling)
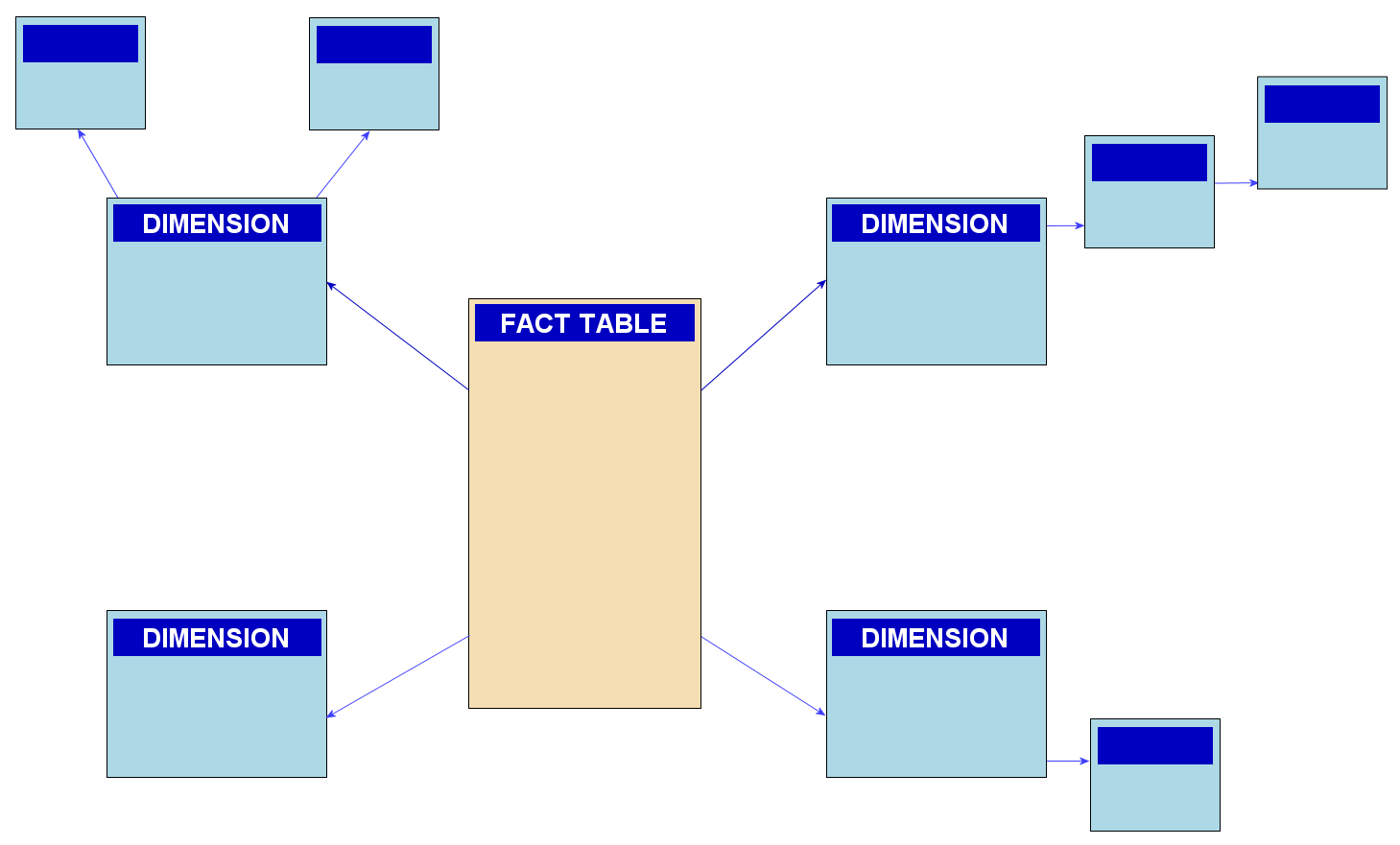
- Fact Tables
- Contains facts generated by events in the past.
- Data in tables should be regarded as read only.
- Tables are often very large.
- Contains facts generated by events in the past.
- Dimension Tables
- Contains descriptive textual data.
- Simple primary keys.
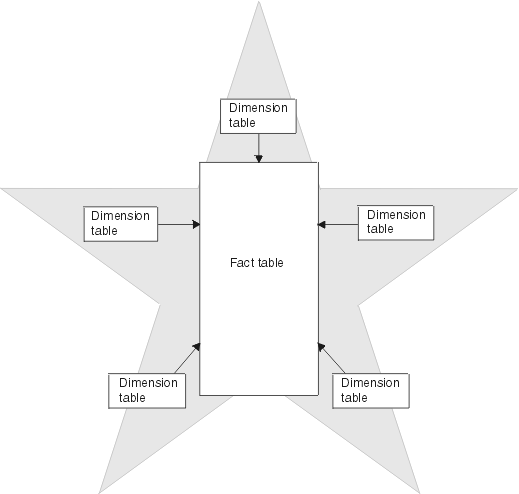
- Gives a characteristic star scheme or star join.
- Contains descriptive textual data.
- Fact Tables
- Star Schema
- De-normalising reference
data can speed up query
performance.
- Main aim is to avoid
data redundancy.
- This achieved in part
via the process of
normalisation.
- De-normalising reference
data can speed up query
performance.
- OTLP System
- Automating business saves money.
- Data could be useful in organisations future operations.
- Information too detailed.
- May require information from more than one OTLP system.
- Difficult to extract information.
- Automating business saves money.
- Snowflake Schema
- Variant of Star Schema where
dimension tables do not
contain de-normalised data.
- Dimension tables have
other dimension tables
linked to them via
foreign keys.
- More than one
dimension table can
share these "dimension
of a dimension" tables.
- Variant of Star Schema where
dimension tables do not
contain de-normalised data.
- Starflake Schema
- Hybrid structure that
contains a mixture of star
and snowflake schema's.
- Contains both
normalised and
de-normalised data.
- Some dimension tables
may be present in both
normalised and
de-normalised forms.
- Hybrid structure that
contains a mixture of star
and snowflake schema's.
- OLAP Analytical Operations
- Consolitation
- Involves the aggregation of
data, such as "roll ups" e.g.
branches can be rolled up to
cities, cities to countries etc.
- Involves the aggregation of
data, such as "roll ups" e.g.
branches can be rolled up to
cities, cities to countries etc.
- Drill-down
- Reverse of consolidation.
- Involves displaying the
detailed data that
compromises the
consolidated data.
- Reverse of consolidation.
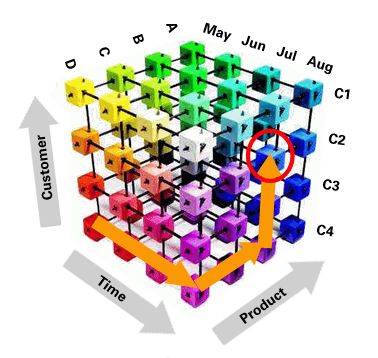
- Slicing and Dicing (aka pivoting)
- Ability to view data from different viewpoints.
- One slice may display revenue by
type of property within cities.
- Another slice may display revenue
by branch office within city.
- Often performed along a time
axis to find patterns and trends.
- Ability to view data from different viewpoints.
- Consolitation
- Data Mining Operations and Techniques
- Predictive Modelling
- Reflect human experience using observations
to form a model of the important
characteristics of some phenomenon.
- Model developed using a
two-phase supervised
learning approach.
- The training phase uses a large sample of
historical data called a training set to build
a model of the important characteristics.
- The testing phase tests the
accuracy and performance of
the model on new data.
- The training phase uses a large sample of
historical data called a training set to build
a model of the important characteristics.
- Used in credit approval,
customer retention
management, direct marketing.
- Reflect human experience using observations
to form a model of the important
characteristics of some phenomenon.
- Database Segmentation
- Partition database into an
unknown number of segments
or clusters of similar records.
- Results can be displayed on scatterplot.
- Used in customer profiling and direct marketing.
- Partition database into an
unknown number of segments
or clusters of similar records.
- Link Analysis
- Aims to discover links (called associations) between
individual records or groups of records in a database.
- Aims to discover links (called associations) between
individual records or groups of records in a database.
- Anomaly Detection
- Identifies outliers (expressions of deviation from
previously known expectations and norms).
- Used in detection of credit card and insurance
fraud, quality control and defects tracing.
- Identifies outliers (expressions of deviation from
previously known expectations and norms).
- Predictive Modelling
Media attachments
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.