22307125
Description
Quiz by Mohammed Arif Mazumder, updated more than 1 year ago
|
|
Created by Mohammed Arif Mazumder
almost 6 years ago
|
|
Question 1
Question
Which of these is the last step of an iteration within the CRISP-DM process?
Answer
-
Analysis
-
Deployment
-
Modelling
-
Evaluation
Question 2
Question
If a model predicts the number of days a customer takes to come back to a company's website, which metric is the most adequate to assess the performance of the model?
Answer
-
Recall
-
Accuracy
-
Precision
-
Mean absolute error
Question 3
Question
Machine Learning steps generally followed
1) [blank_start]_________________________[blank_end]
2) [blank_start]_________________________[blank_end]
3) [blank_start]_________________________[blank_end]
4) [blank_start]_________________________[blank_end]
5) [blank_start]_________________________[blank_end]
Answer
-
Data Ingestion
-
Preparing Data
-
Build and Train Models
-
Model Deployment
-
Monitoring Models
Question 4
Question
A face recognition model for accessing a gym is posing issues because it denies access to too many customers. Why might this be?
Answer
-
The model is too sensitive and a higher threshold would solve the problem.
-
The model is too specific and a lower threshold would solve the problem.
-
The model is too specific and a higher threshold would solve the problem.
-
The model is too sensitive and a lower threshold would solve the problem.
Question 5
Question
What is PII?
Answer
-
Publicly Identifiable Information
-
Personally Identifiable Information
-
Personally Identifiable Index
-
Publically Incriminating Index
Question 6
Question
What is used to compare the predicted and actual values of a binary classification model?
Answer
-
Correlation coefficient
-
BLEU score
-
R-squared value
-
Confusion matrix
Question 7
Question
A weather forecast model must update its predictions first thing in the morning, everyday. It is trained on daily historical data, available publicly, but that data is only refreshed at noon each day, so it is not available at the correct time necessary for updating the model's predictions. How could this problem be solved?
Answer
-
Replicate the dataset and run the predictions in production with that.
-
Train the model with different data because the model must make inferences using the same type of input data it saw during training.
-
Replicate the dataset and train the model with that.
-
Do not use the dataset when running the model in production.
Question 8
Question
An online retail company wants to improve the speed at which it analyzes how users interact with its website. What is the most pressing architectural question you would address first?
Answer
-
Whether the data ingestion processes are event-driven and real time, or nightly batch.
-
Whether the data is being put into a data lake before analysis
-
Whether processes str in place to clean and preprocess data before storage
-
Whether business rules are applied on data in transit or in-situ
Question 9
Question
Which module would you use to evaluate the performance of a binary classifier using scikit-learn?
Answer
-
sklearn.metrics.r2_score
-
sklearn.metrics.mean_absolute_error
-
sklearn.metrics.auc
-
sklearn.metrics.median_absolute_error
Question 10
Question
After sampling 10,000 values of a random variable you observe that the mode, median, and mean are the same. What is the most likely variable distribution?
Answer
-
Poisson distribution
-
Normal distribution
-
Uniform distribution
-
Logarithmic distribution
Question 11
Question
Which technique can be useful to handle highly imbalanced true/false labels?
Answer
-
Systematic sampling
-
Stratified sampling
-
Convenience sampling
-
Simple random sampling
Question 12
Question
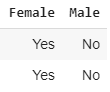
You have a dataset with Female and Male features. What will be the feature names when the code below is executed?
```import pandas as pd
def azureml_main(dataframe1 = None, dataframe2 = None):
pd.get_dummies(dataframe1)
return dataframe1,```
Image:
Qq (binary/octet-stream)
{kind=link}
Answer
-
Female, Male
-
Female_No, Male_Yes
-
Female_Yes, Male_No
-
Female_Yes, Female_No, Male_Yes, Male_No
Question 13
Question
You have a dataset that you want to use for your company's ML algorithm. It has 30 dimensions and you want to reduce the size to 3 dimensions to decrease memory usage and computation time. Which method should you choose?
Answer
-
t-Distributed Stochastic Neighbor Embedding
-
Linear Discriminant Analysis
-
K-means model stacking
-
Principal Component Analysis
Question 14
Question
What is Kubernetes?
Answer
-
A proprietary platform built by Google and Docker to run and manage your applications.
-
A container orchestrator to provision, manage, and scale applications.
-
A serverless platform to build and manage your apps.
-
An an open-source system to deploy, manage, and run Cloud Foundry apps.
Question 15
Question
Your team is building a data engineering and data science development environment.
The environment must support the following requirements:
✑ support Python and Scala
✑ compose data storage, movement, and processing services into automated data pipelines
✑ the same tool should be used for the orchestration of both data engineering and data science support workload isolation and interactive workloads
✑ enable scaling across a cluster of machines
You need to create the environment.
What should you do?
Answer
-
Build the environment in Apache Hive for HDInsight and use Azure Data Factory for orchestration.
-
Build the environment in Azure Databricks and use Azure Data Factory for orchestration.
-
Build the environment in Apache Spark for HDInsight and use Azure Container Instances for orchestration.
-
Build the environment in Azure Databricks and use Azure Container Instances for orchestration.
Want to create your own Quizzes for free with GoConqr? Learn more.