2458546
| Question | Answer |
| Overfitting and Tree Pruning | Overfitting an induced tree may overfit the training data. Too many branches, some may reflect anomalies due to noise or outliers. Poor accuracy for unseen samples. |
| Two approaches to avoid overfitting | PREPRUNING: Halt tree construction early—do not split a node if this would result in the goodness measure falling below a threshold. Difficult to choose an appropriate threshold. PPOSTPRUNING: Remove branches from "fully grown" tree—get a sequence of progressively pruned trees. Use a set of data different from the training data to decide which is the "best pruned tree" |
| Naive Bayesian Classifer: Comments | |
| Associative Classification | Association rules are generated and analyzed for use in classification Search for strong associations between frequent patterns (conjuring of attribute-value pairs) and class labels |
| Associative Classification: Why effective? | It explores highly confident associations among multiple attributes and may overcome some constraints introduced by decision-tree induction, which considers only one attribute at a time In many studies, associative classification has been found to be more accurate than some traditional classification methods, such as C4.5 |
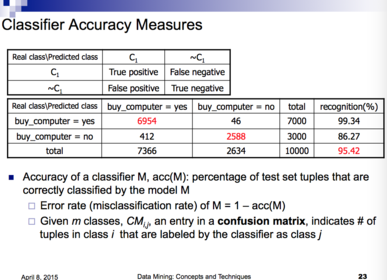
| Classifier Accuracy Measures | |
| Evaluating the Accuracy of a Classifier or Predictor: HOLDOUT METHOD | Given data is randomly partitioned into two independent sets: TRAINING SET (e.g., 2/3) for model construction TEST SET (e.g., 1/3) for accuracy estimation RANDOM SAMPLING: a variation of holdout — repeat holdout k times, accuracy = avg. of the accuracies obtained |
| Evaluating the Accuracy of a Classifier or Predictor | CROSS-VALIDATION (k-fold, where k = 10 is most popular) Randomly partition the data in k mutually exclusive subsets, each approximately equal size. At i-th iteration, use Di as test set and others as training set. LEAVE-ONE-OUT: k folds where k = # of tuples, for small size data STRATIFIED CROSS-VALIDATION: folds are stratified so that class list. in each fold is approx. the same as that in the initial data |
| Ensemble Methods: Increasing the Accuracy | Ensemble Methods: use a combination of models to increase accuracy, combine series of k learned models, M1, M2, ..., Mk, with the aim of creating improved model M* POPULAR ENSEMBLE METHODS: Bagging: average the prediction over a collection of classifiers Boosting: weighted vote with collection of classifiers |
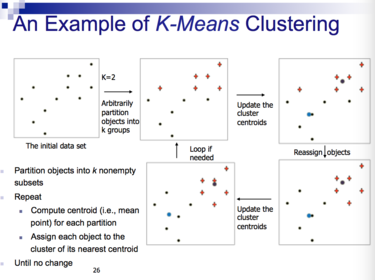
| An example of K-Means Clustering | |
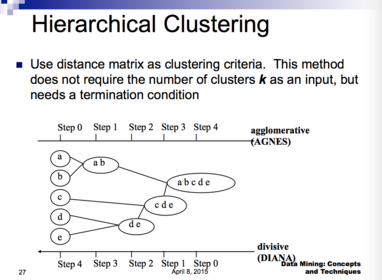
| Hierarchical Clustering | |
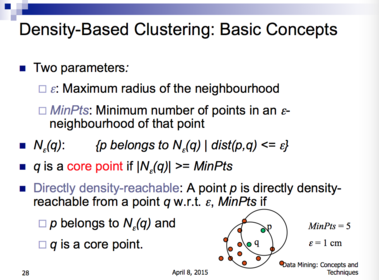
| Density-Based Clustering: Basic Concepts | |
| Density reachable | |
| Density-connected | |
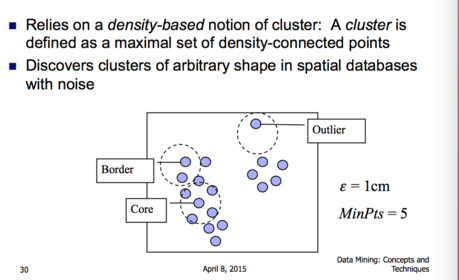
| Density Based Spatial Clustering of Applications with noise | |
| The Curse of Dimensionality | Data in only one dimension is relatively packed adding a dimension stretch the points across that dimension, making them further apart adding more dimensions will make the points further apart-high dimensional data is extremely spares distance measure becomes meaningless due to equi-distance |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
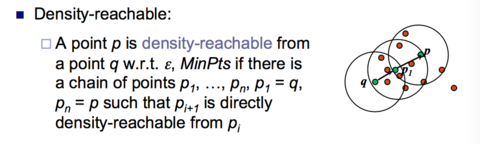{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.