718663
Description
Flashcards by aeilish.wynne, updated more than 1 year ago
|
|
Created by aeilish.wynne
about 10 years ago
|
|
| Question | Answer |
| Carbohydrates are Made from Monosaccharides Most carbs are long chains of monoasccharides. Glucose is a monosacchaire with six carbon atoms. | There are two types of glucose, aplha and beta. Glucose's structure is related to its function - as the main energy source. It's structure makes it soluble so it can be easily transported - contains a lot of energy. |
| Monosacchairdes join together to form disaccharides (2 mono's) and polysaccharides (more than 2 mono's). By glycosidic bonds - through condensation reaction (water released) | The reverse of a condensation is hydrolysis. A water molecule reacts with glycosidic bond, breaks it apart. |
| Starch - main energy source - Plants. Plants store excess glucose as starch, when energy needed - starch broken down to glucose. Mix of 2 polysaccharides - amylose and amylopectin. | Glycogen - main energy soucre - animals Excess glycogen stored as glycogen. 1-4/1-6 glyco bonds - lots of side branches - released quickly. Compact, insoluble in water, large = lots of energy. |
| Amylose - long, unbranched, 1-4 glyco bond, coiled structure, makes it compact = good for storage = more into a small place. | Amylopectin - long, branched chain (of glucose), 1-4/1-6 glyco bonds. Side branches allow enzymes to get at glyco bonds easily = quick release of glucose. |
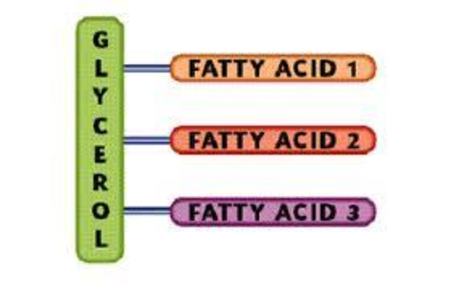
| Triglycerides 1 glycerol molecule. 3 fatty acids (FA's) attached to it. FA's have long tails made of hydrocarbons - hydrophobic. Lips are insoluble in water. |
Image:
Triglycerides (image/jpg)
|
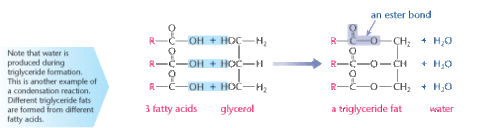
| Triglycerides are formed by condensation reactions - broken by hydrolysis. 3 fatty acids and 1 glycerol are joined by ester bonds. Hydrogen atom on glycerol bonds to OH group on fatty acid - releasing water molecule. Hydrolysis - water is added to each ester bond - breaks it apart - triglyceride splits. | |
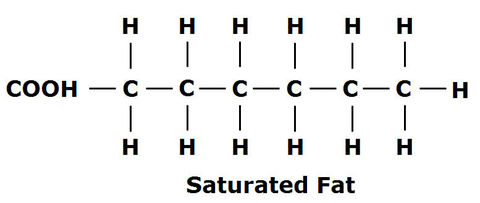
| Saturated Lipids - mainly found in animal fats (e.g. butter). Don't have double bonds between carbon atoms (in hydrocarbon tail). EVERY carbon is attached to at least 2 hydrogen atoms. |
Image:
Structure_Lipid (image/jpg)
|
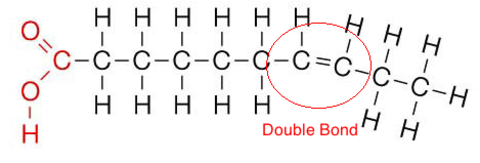
| Unsaturated lipid - mainly found in plants (e.g. olive oil). Melt at lower temperatures than sats. Have a double bond between carbon atoms in tails. Double bond = chain to kink. 2 or more double bonds = polyunsaturated. | |
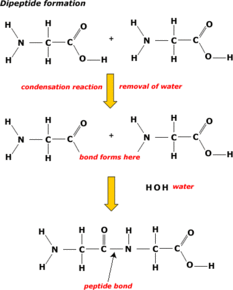
| Proteins made from lots of smaller molecules - monomers - linked together. Monomers are amino acids = Proteins made from long chain of amino acids. | DIPEPTIDE = 2 amino acids join together. POLYPEPTIDE = more than 2 amino acids join together. Proteins = 1 or more polypeptides. |
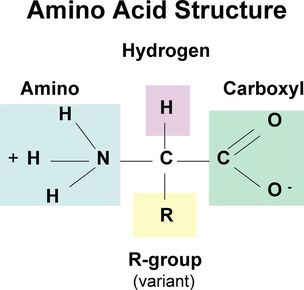
| Different amino acids have different variable groups. Made of carboxyl group (COOH), amino group (NH2), attached to central carbon. The difference between amino acids is the variable group (R group) | |
| Amino acids are linked by PEPTIDE bonds. Which forms dipeptides and polypeptides. Formed by condensation reactions. | |
| Proteins have 4 structural levels. Primary - the sequence of amino acids in a polypeptide chain. Secondary - hydrogen bonds begin to form between amino acids in chain - automatically coils into alpha helix or folds into beta pleated sheet. | Tertiary - coilded or folded chain is often coilded or folded further. More bonds form between different parts of polypeptide chain. Proteins made of a single polypeptide chain this strucutre is their 3D one. Quaternary - is the way that the polypeptide chains assemble together. If proteins have more than 1 chain this is the protein's final 3D structure. |
| Primary - held by peptide bonds between amino acids. Secondary - held by hydrogen bonds formed between nearby amino acids. Quaternary - determined by tertiary structure - due to this it can be influenced by all bonds mentioned. | Tertiary - Ionic: weak interactions between negative and positive charges on different parts of molecule. Disulfide: when 2 molecules of the amino acid cysteine come close the sulfur atom in one cysteine bonds to sulfur in the other. Hydrophobic and hydrophilic: when hydrophobic groups are close - clump together. meaning hydrophilic groups are more likely to be pushed outside. Hydrogen bonds. |
| Globular - round, compact, made of multiple polypeptide chains. Chains are coiled up so hydrophilic parts are on the outside and hydrophobic parts face inwards. Makes protein soluble = easily transported. E.g. haemoglobin | Fibrous - long, insoluble polypeptide chains, tightly coiled round each other - forming a rope shape. Held together by lots of bonds - make protein strong. Often found in supportive tissue e.g. collagen. |
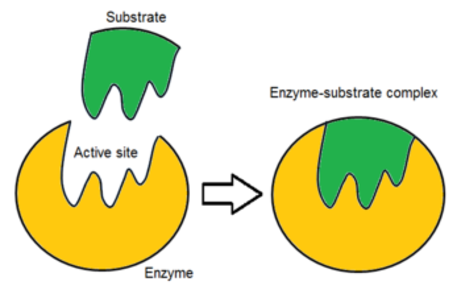
| Enzymes are biological catalysts. They catalyse metabolic reactions e.g. digestion and respiration. Can be intracellular (within cells) or extracellular (outside cells) e.g. in the blood and digestive system. | Enzymes are globular proteins. They have an active site which has a specific shape. The active site is where the substrate molecules bind to. They are highly specific due to their 3D structure. |
| In a chemical reaction, a certain amount of energy needs to be supplied to the chemicals before the reaction will start - activation energy. Enzymes lower the amount of activation energy needed - making reactions happen at lower temperatures = faster rate of reaction. | When a substrate fits into the active sit it forms an enzyme-substrate complex - this is what lowers the activation energy. If 2 substrate molecules need to be joined, being attached to the enzyme holds them close together, reducing any repulsion. If the enzyme is catalysing a breakdown reaction fitting into the active site puts a strain on bonds in the substrate - so the molecule breaks up more easily. |
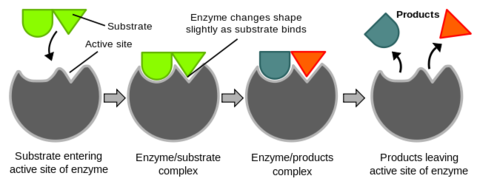
| Enzyme's only work with substrates that fit their active site. Early scientists came up with the lock and key model. Where the substrate fits into the enzyme like a key fits into a lock. They soon realised it didn't give the full story. New evidence showed that the enzyme-substrate complex changed shape slightly to complete the fit. this locks the substrate even more tightly to the enzyme. | |
| The induced fit method explains why enzymes are so specific and only bond to one particular substrate. Not only does the substrate have to be the right shape to fit the active site it also has to make the active site change shape. | |
| Enzymes are very specific that they usually only catalyse one reaction. Because only one substrate will fit into the active site. This site's shape is determined by the enzyme's 3D structure - determined by the primary structure. | Each different enzyme has a different 3D structure and so a different shaped active site. If the substrate shape doesn't match the active site the reaction won't be catalysed. If the 3D structure is altered in ANY WAY the shape of the active site will change. Meaning the substrate won't fit into the active site and the enzyme can no longer carry out its function. |
| The more enzyme molecules there are in one solution the more likely a substrate molecule is to collide with one and form with enzyme-substrate complex - increasing the concentration of the enzyme increases the rate of reaction. | If the amount of the substrate is limited, there comes a point when there is more enzyme molecules to deal with all the available substrate molecules so adding. more enzyme has no further effect . |
| DNA and RNA are polynucleotides - made up of lots of mononucleotides. Each mono is made from a pentose sugar (the sugar in Dna is Deoxyribose and in Rna its Ribose), phosphate group and a nitrogenous base. Each mono has the same sugar and phosphate but the base can vary. | There are four possible bases - adenine (A), thymine (T) (in RNA uracil (U) replaces T), cytosine (C) and guanine (G). The mononucleotides are joined through condensation reactions between the phosphate of one mono and the sugar of another. DNA is 2 polynucleotide strands whereas RNA is just 1. |
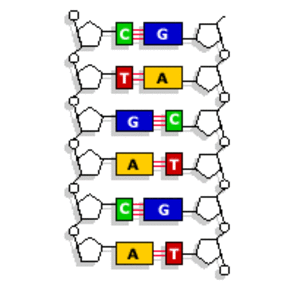
| 2 complementary DNA strands join together by hydrogen bonds between the bases. Each base can only join with one partner - this is called COMPLEMENTARY BASE PAIRING. A-T and C-G. The 2 DNA strands wind up to form the DNA double helix. | |
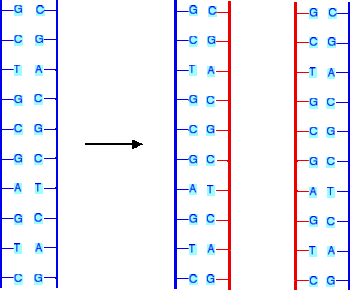
| Self-Replication. DNA helix unzips forming two single strands - each original strand acts as a template for a new strand. Free-floating mononucleotides join to each original template strand through complementary base pairing. The monos on the new strand are joined together by the enzyme DNA polymerase. Hydrogen bonds form between the bases on the new and original strand. Each DNA molecule contains one strand from the original DNA and one new strand. This is called SEMI-CONSERVATIVE REPLICATION because half of the new strands are from the original. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.