459506
Description
Mind Map by kalaiyarasi, updated more than 1 year ago
|
|
Created by kalaiyarasi
about 12 years ago
|
|
BIG DATA
Annotations:
- Data sets whose size or type is beyond the ability of traditional relational databases to capture, manage, and process the data with low-latency.
- Big data comes from sensors, devices, video/audio, networks, log files, transactional applications, web, and social media - much of it generated in real time and in a very large scale.
- Technologies
Annotations:
- it needs certain exceptional technologies to efficiently process huge volumes of data in a good span of time
- Apache Hadoop
Annotations:
- Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
- Pig
Annotations:
- Pig(programming tool) was developed at Yahoo! Pig is a high-level platform for creating MapReduce programs used with Hadoop.
- Pig provides capabilities in the language for loading, storing, filtering, grouping, de-duplication, ordering, sorting, aggregation, and joining operations on the data
- Modules
Annotations:
- Hadoop Common - contains libraries and utilities needed by other Hadoop modules
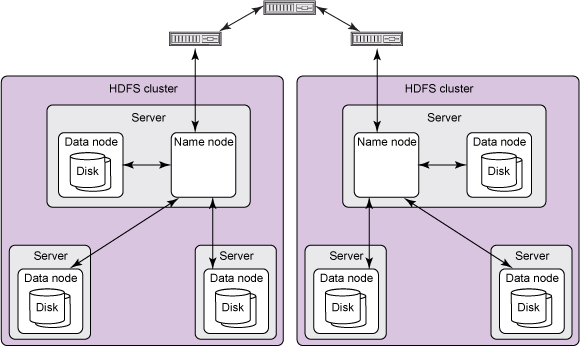
- Hadoop Distributed File System (HDFS) - a distributed file-system that stores data on the commodity machines
- Hadoop YARN - a resource-management platform responsible for managing compute resources in clusters
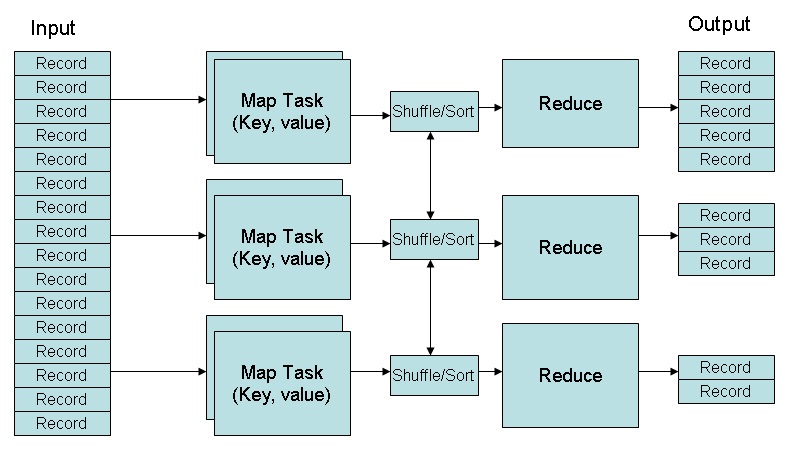
- Hadoop MapReduce - a programming model for large scale data processing
- MapReduce
Annotations:
- Pioneered by Google.It uses parallel, distributed algorithm. 'MapReduce' is a framework for processing problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster.
- Characteristics
Annotations:
- The McKinsey Global Institute estimates that data volume is growing 40% per year, and will grow 44x between 2009 and 2020
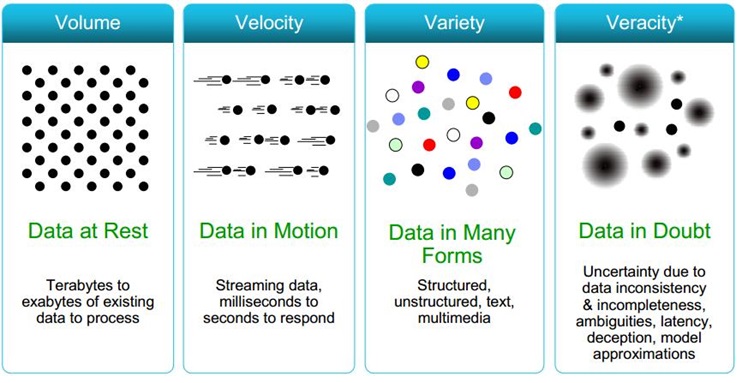
- Four characteristics that define big data: 1)volume 2)velocity 3)variety 4)value
- To make the most of big data, enterprises must evolve their IT infrastructures to handle these new high-volume, high-velocity, high-variety sources of data and integrate them with the pre-existing enterprise data to be analyzed.
- Volume
Annotations:
- Machine-generated data is produced in much larger quantities than non-traditional data. ex:For instance, a single jet engine can generate 10TB of data in 30 minutes.
- Velocity
Annotations:
- Social media data streams – while not as massive as machine-generated data. ex: Even at 140 characters per tweet, the high velocity (or frequency) of Twitter data ensures large volumes (over 8 TB per day).
- Variety
Annotations:
- Traditional data formats tend to be relatively well defined by a data schema and change slowly. In contrast, non-traditional data formats exhibit a dizzying rate of change.
- As new services are added, new sensors deployed, or new marketing campaigns executed, new data types are needed to capture the resultant information.
- Veracity
Annotations:
- uncertainty of data poor data quality costs US economy 3.1 trillion dollars a year
- Architecture & Patterns
Annotations:
- "Big data architecture and patterns" series presents a structured and pattern-based approach to simplify the task of defining an overall big data architecture
- Classify big data
Annotations:
- Business problems can be categorized into types of big data problems. ex:BUSINESS PROBLEM:Utilities: Predict power consumptionBIG DATA TYPE:Machine-generated data
- Defining logical architecture
Annotations:
- The logical layers help to define and categorize the various components required for a big data solution. 1.Big data sources 2.Data massaging and store layer 3.Analysis layer 4.Consumption layer
- Understanding patterns
Annotations:
- Addresses the most common and recurring big data problems and solutions. It helps to define a high level solution for a big data problem.
- Atomic Patterns
Annotations:
- The atomic patterns describe the typical approaches for consuming, processing, accessing, and storing big data.
- Composite patterns
Annotations:
- Composite patterns, which are comprised of atomic patterns to solve the big data problems.
- Choosing Solution Patterns
Annotations:
- A specific solution pattern (made up of atomic and composite patterns) is applied to the business scenario. solution patterns are used to architect a big data solution.
- Determining the viability of a business problem
Annotations:
- Before making the decision to invest in a big data solution, evaluate the data available for analysis.Asking the right questions is a good place to start. ex:Does my big data problem require a big data solution?What insights are possible with big data technologies?
- Selecting the right product for big data solution
Annotations:
- Products and technologies that form the backbone of a big data solution
- Big data analytics
Annotations:
- Without analytics, big data is just noise. Big data analytics is the use of advanced analytic techniques against very large, diverse data sets
- Importance
Annotations:
- Analyzing big data allows analysts, researchers, and business users to gain new insights resulting in significantly better and faster decisions.
- Database systems
- Massively Parallel Processing (MPP)
Annotations:
- A system that parallelizes the query execution of a DBMS, and splits queries and allocates them to multiple DBMS nodes in order to process massive amounts of data concurrently.
- Each part communicates via messaging interface.
- Stream processing
Annotations:
- A system that processes a constant data (or events) stream, or a concept in which the content of a database is continuously changing over time.
- Column oriented database
Annotations:
- a database management system (DBMS) that stores data tables as sections of columns of data rather than as rows of data.
- Key value storage
Annotations:
- Every single item in the database is stored as an attribute name (or "key"), together with its value.
- Distributed Database
Annotations:
- They store data across multiple computers to improve performance by allowing transactions to be processed on many machines, instead of being limited to one
- Massively Parallel Processing (MPP)
Media attachments
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.